Core Design Principles
HFSM has been designed around the following core principles:
Any abstract theory is reductionist by nature, which is both good and bad. A design based on such early abstraction has a high chance to suffer from the 'broken phone' effect: Еheory might abstract away details deemed 'unimportant' in the context of the theory.
The importance of said detail in the context of the practical design might turn out to be of much higher, yet be left out of the software being designed due to conformance urge.
Examples:
-
Classes might not always be the best way to represent 'events' in finite state machine. They can be implemented in a variety of ways, e.g. function calls.
-
Abstract 'set of state transitions' doesn't always have to be provided explicitly. It will be provided by the user at least once implicitly in client code initiating state transitions.
UML StateChart has been considered early in the development, and subsequently rejected, due to not adding much value beyond being supposedly well-understood by many programmers. The cost of that benefit was strongly offset by the severe limitations in design.
Artificial limitations on state transitions (e.g. explicit transition table) is known to lead to hard-to-understand code, as implicit transition set defined in user code comes in conflict with the explicit transition table. Programmer trying to make sense of such code has to inspect 2 code locations to figure out the actual destinations of state transitions.
On the contrary - states opt-in to respond to FSM logic, by implementing state methods. And only those they need, but not more.
HFSM uses compile-time polymorphism, sacrificing compile times for run-time performance. Originally created for videogames, known to have strong frame time and budgets, performance and efficiency are of highest priority.
The use of templates also opens the opportunity for the compiler to inline more freely.
HFSM leverages the power of modern C++ language constructs to minimize the overhead required to build a running state machine from the user code.
There's not a lot of code not directly mapped to useful functionality (a.k.a. 'boilerplate') required to use HFSM.
Other than required M:: scope and `M::Bare' state base, there aren't many useless lines of code one needs to type.
State transitions are implemented as template functions taking target state type as a template argument. This approach ensures one can't easily mis-spell the name of the state to transition into.
struct SourceState : M::Base {
void transition(Control& control, Context&) {
control.changeTo<TargetState>();
}
}#define HFSM_ENABLE_STRUCTURE_REPORT causes HFSM to automatically generate a structure report for an arbitrary FSM:
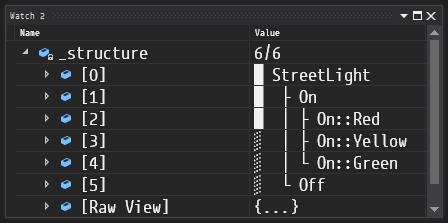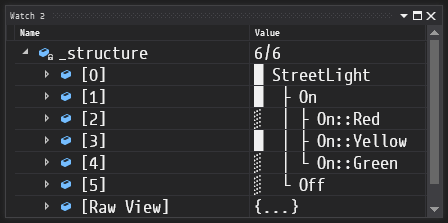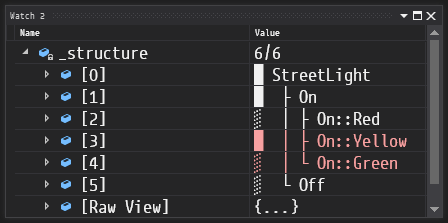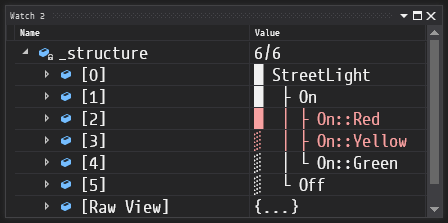
The goal of HFSM is to take over the task of managing the state machine built from the user-provided code in a consistent manner. With minimal limitations imposed by the library, it allows the programmer to write their code the way they want it, gently supporting you along the way with type-safe interface and extensive debug facilities. Powerful feature set and efficient code generation give allow for high run-time performance.
Combined, this allows for a new quality to emerge - using HFSM often leads to high programmer productivity, and in turn - enjoyment.
Try it out for yourself!