In our CCS 2014 paper, The Web Never Forgets, we measure three advanced tracking mechanisms, canvas fingerprinting, cookie respawning, and cookie syncing and explore the privacy implications of their use. For a more detailed overview and access to the data visit the project's homepage.
This repository contains scripts for re-running the entire project, and is broken down into measurement, analysis, and visualization.
Two crawlers, one developed at KU Leuven and one developed at Princeton are used. The crawlers are both built on top of similar technologies, but are functionally quite different. The Leuven crawler isolates state between page visits and was used for all parallel crawls. The Princeton crawler keeps consistent state and was used for all sequential crawls.
Sequential Version v0.2.0 of
OpenWPM is contained in OpenWPM along with the necessary crawling scripts.
You can run these crawls from that directory with python sequential_crawl.py
Parallel A copy of modCrawler included in the modCrawler directory. Please check command line options for running the crawler with different settings.
The analysis performed in the paper can be recreated with the following analysis scripts. Once the data is downloaded, update the scripts to point to your download location, and find the analysis output either printed to stdout or to a summary file.
Canvas Fingerprinting
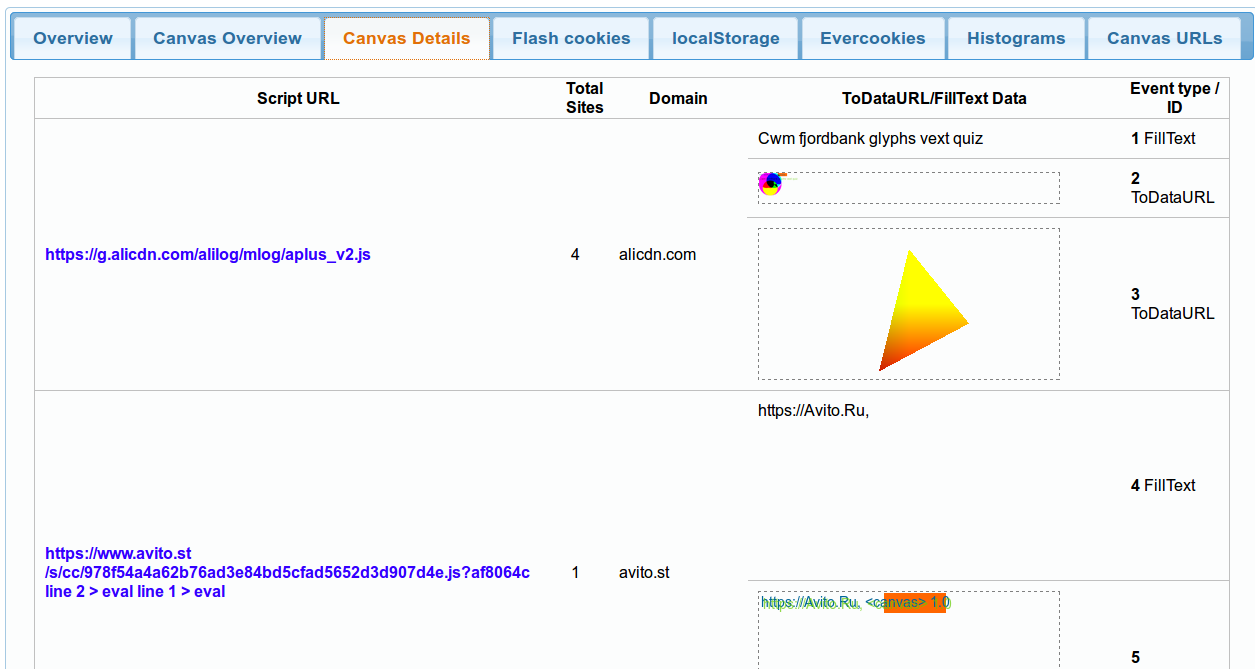
- modCrawler/analysis/canvas.py - The crawl report generated automatically includes detailed information about the detected canvas fingerprinters, evercookies etc.
Cookie Respawning
- ccs_respawn_measurements.py - HTTP Cookies respawned from Flash Objects
- modCrawler/analysis/extract_evercookies.py - HTTP Cookies respawned from Flash Objects for the parallel crawler.
Cookie Syncing - these analysis scripts and supporting utilities are included in analysis
- ccs_sync_measurements.py - cookie sync analysis + cookie respawn and sync analysis
- census_util - supporting utilities for all scripts
- extract_cookie_ids.py - extracts id cookies from pairs of databases
- extract_id_knowledge.py - supporting algorithms for sync analysis
Code for the generation of graphs, including those in our blogpost is included. Some manual visualization done in Gephi
modCrawler's crawl report will embed the images used by canvas fingerprinting scripts such as the following:
OpenWPM's dependencies can be found on the repo wiki
sudo pip install numpy tld publicsuffix networkx
modCrawler's dependencies can be found in the requirements.txt file and setup.sh script. setup.sh script will install all dependencies automatically. We strongly advise you to run modCrawler in a virtual machine or a container such as LXC. Please check modCrawler's own repository for updates and bug reports.