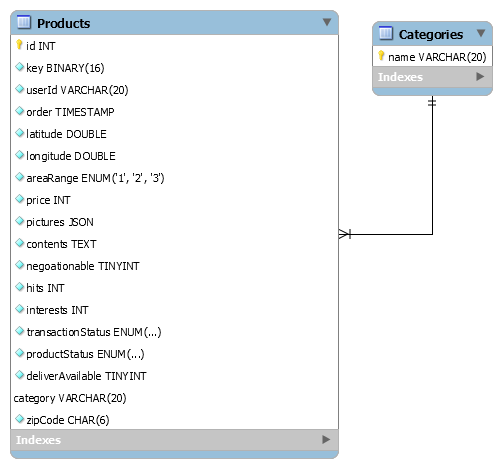
Product service Database modeling
title: String,
userId: String,
order: Date,
areaRange: enum: ['1', '2', '3'],
price: Number,
pictures: Array,
location: {
lat: { type: Number },
lon: { type: Number },
},
contents: String,
negotiable: Boolean,
hits: Number,
interests: Number,
currentStatus: enum: ['대기', '거래중', '거래완료', '비공개'],
productStatus: ['미개봉', '미사용', 'A급', '사용감 있음', '전투용', '고장/부품'],
deliverAvailable: Boolean,
category:
enum: [
'디지털/가전',
'가구/인테리어',
'유아동/유아도서',
'생활/가공식품',
'여성의류',
'여성잡화',
'뷰티/미용',
'남성패션/잡화',
'스포츠/레저',
'게임/취미',
'도서/티켓/음반',
'반려동물용품',
'기타 중고물품',
],
- 참조
- MySQL Server는 pluggable storage engine 아키텍쳐 사용
-
SHOW ENGINES를 통해 지원하는 엔진 종류를 확인할 수 있음
-
- InnoDB
- trnsaction-safe(ACID) storage
- DB수업에 학습했던 commit, rollback, recovery등의 기능을 수행
- MySQL 기본 엔진
-
특징 중 일부
- 트랜잭션 지원
- 인덱스 캐시 지원
- Full-text search index 지원(5.6 버전 이상)
- 외래키 지원
- trnsaction-safe(ACID) storage
- MyISAM
- 적은 사용량
- 테이블 수준의 락킹(테이블 접근 제어) - 읽기 전용이 대부분인 곳에서 사용
-
특징 중 일부
- 백업/회복 지원
- B-tree Index
- 클러스터 데이터베이스 미지원
- 데이터 캐시 미지원
- 외래키 미지원
- Full-text 검색 인덱스 지원
- 트랜잭션 미지원
- Memory
- CSV 등...
-
어느 것을 선택해야 할까?
- MyISAM
- 일반적으로 상품등록의 경우 글을 쓰는 횟수보다 조회하는 횟수가 많을 것이라 생각하기 때문에 MyISAM이 좀더 적절할 것 같다고 생각이 든다.
- MyISAM
-
참조
- Auto increment keys vs. UUID
- MS- 클러스터형 및 비클러스터형 인덱스 소개
- mysql documentation - innodb auto increment handling
- Natrual key(business key)
- unique key(유일키 - 행의 고유 식별자)중 후보키
- Surrogate key(대체 키)
-
클러스터형 인덱스
- 키 값을 기반으로 테이블이나 뷰의 데이터 행을 정렬하고 저장
- 테이블의 데이터 행이 정렬된 순서로 저장될 때만 테이블에 클러스터형 인덱스가 포함
- 테이블에 클러스터형 인덱스가 없으면 해당 데이터행은 힙 구조로 저장
- primary key
-
비클러스터형 인덱스
- 데이터 행으로부터 독립적
- 비클러스터형 인덱스 키 값이 있으며 각 키 값 항목에는 해당 키 값이 포함된 데이터 행에 대한 포인터가 있음
- 데이터 페이지가 힙에 저장되는 경우
- 위치는 행에 대한 포인터값
- 클러스터형 테이블
- 위치는 클러스터형 인덱스 키
- unique key
- 데이터 행으로부터 독립적
-
Auto increment
-
새로운 레코드가 삽십될때 유일한 숫자 생성
-
분산 시스템에는 적절하지 않다.
-
InnoDB
In MySQL 8.0, this behavior is changed. The current maximum auto-increment counter value is written to the redo log each time it changes and is saved to an engine-private system table on each checkpoint. These changes make the current maximum auto-increment counter value persistent across server restarts. mysql documentation
- mysql 5.7 이전 버전에서는 auto increment는 main memeory영역에만 저장했기 때문에 auto increment를 이용하여 기본키를 지정할 경우에 장애가 발생하는 문제가 발생할 수 있음
- 8.0 버전에서는 log에 값을 기록
-
-
UUID
- 유일한 키, "the whole universe"
- 관계형 데이터베이스에서 성능 이슈 있음
- 데이터베이스에서 클러스터형 키로 설정되었을 경우 데이터 베이스는 새로운 값을 삽입할 때마다 순서에 맞게 재배치 작업을 수행한다.
- 16바이트(BIGINT는 8바이트 차지)
-
분산 시스템에서 데이터를 식별하는 것에 문제가 된다면, auto increment는 기본키로 사용하고, 각 필드를 식별하는 키는 uuid를 이용하여 처리하는 방법을 선택 ( 여러분은 유일키를 잡을시 자동증가 값으로 하시나요 아니면 UUID를 사용하시나요? 세브라이드님 답글 참조)
-
참조
- MySQL8.0 - Numeric Type Overview
-
Stackoverflow - What is the beneift of zerofil in MySQL
- 지정된 값까지 0으로 채우는 효과이외는 없다고 함
-
UNSIGNED 속성 추가
If you specify
ZEROFILLfor a numeric column, MySQL automatically adds theUNSIGNEDattribute to the column. -
8.0.17 버전 이후 부터 이 속성은 제거될 예정
As of MySQL 8.0.17, the
ZEROFILLattribute is deprecated for numeric data types and support for it will be removed in a future MySQL version.-
LPAD()함수를 사용하거나, CHAR등의 자료형을 활용하여 대체
Consider using an alternative means of producing the effect of this attribute. For example, applications could use the LPAD() function to zero-pad numbers up to the desired width, or they could store the formatted numbers in CHAR columns.
-
-
workbench를 통해서 DB 모델링시 해당 값은 크게 신경쓰지 않고 모델링
- 서비스별로 데이터베이스가 분리되어있기 때문에 join을 이용하여 처리하는 것이 아닌 api를 통해 찜수 횟수를 확인하기 때문에 완전히 일치할 가능성이 떨어지더라도 찜수를 별도의 필드로 넣어서 확인하는게 성능상에 이점이 있을 것 같다.
- 참조
- 지역 범위를 사용한다면 너비 우선탐색이 좀더 빠르게 끝날 것이라고 판단. > 그래프 데이터베이스??
- 용도가 다름 -> 추천서비스에 적합함
- MongoDB 위치 기반 쿼리
- 동을 어떻게 처리할가?
- 방법
- 위도,경도 값을 저장하고 추후 계산
- 우편번호를 입력받고 추후 계산
- 처음부터 시/군/구 + 동명을 입력받는다.
- 동 이름만 입력하고 나중에 생각한다.
- 주소아이디(우편번호와 같은 정보) + 동이름을 저장하는 것이 좋을 것 같다.
- (연산을 최소화 하자)
- 방법
- 지역범위를 어떻게 처리할까?
- 현재 위치(동)만, 구까지, 시까지 범위를 지정한다.
- 00시 까지의 범위는 너무 큰 것 같다.
- 거래를 할때 판매자의 위치까지 가는 경우가 있는데 이 경우 거리가 너무 멀다
- 필요한 물건이라면 해당 거리까지 찾아갈거 같기 때문에 거리는 문제가 되지 않을 것 같다.
- 그 경우 전국을 범위로 지정하는 것과 동일하다 생각한다.
- 00시 까지의 범위는 너무 큰 것 같다.
- 1단계 - 현재 동네만
- 2단계 - 인근동
- 인근 지역 찾는 알고리즘은 찾아볼것
- 3단계
- 구까지
- 현재 위치(동)만, 구까지, 시까지 범위를 지정한다.
-
MySQL = 관계형 데이터베이스
-
MongoDB = NoSQL
-
상품 서비스에서는 별도의 관계가 형성되지 않기 때문에 MongoDB를 사용