Writing an Action
After writing a CloudCrowd::Action and installing it into the actions folder, CloudCrowd will be ready to run your own custom jobs. A minimal action consists of a single method, process, which defines the parallel part of the computation.
Optionally, actions may define a split method, which, running before process, splits up a single input into multiple inputs to be processed in parallel. All of the inputs to a job are already running in parallel in the first place, so defining a split method simply multiplies the potential parallelism of your job by a certain factor. Actions may also define a merge method, which receive all of the outputs of process in order to derive a single result.
An example of an action which employs all three stages is process_pdfs, included by default. It splits a single PDF input into smaller 10-page chunks, processes each page into a series of scaled images, as well as extracting the full text for that page, and then, when complete, merges all of the resulting files back together into a zipped-up directory, ready for download and import.
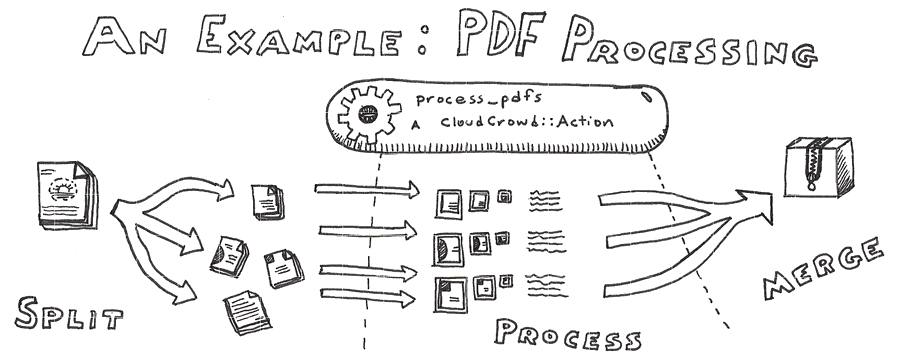
Actions are simple Ruby classes that inherit from CloudCrowd::Action, and implement at least a process method, for running the parallel portion of a task.
split |
optional | A method that uses the input — the input being anything JSON-serializable, or a URL to a file — and splits it up into work units suitable for parallel processing. Return an array of output from this method, and each element in the array will be sent as the input to the next step (process), in parallel across all your workers. |
process |
mandatory | Perform the parallel portion of the computation. The input comes directly from your Job request, or, if you have a split method defined, from the output of split. The return value from process is either returned as the output of the job, or sent to merge for further processing. |
merge |
optional | The input is an unordered array of all the outputs from the process stage. The return value of merge is the result of the Job. |
Inheriting from CloudCrowd::Action also provides a handful of convenience methods:
input |
The input value to this stage of the action. In split and process, this is usually the URL to the file that needs to be processed, but it can be anything JSON-serializable. In merge, this is an array containing every result that was returned from all of the workers processing (which are also often, but not necessarily, URLs). |
options |
As part of creating a job, you can specify an options configuration hash of arbitrary JSON for internal use. This options hash is passed through verbatim to each stage and every work unit. |
download(url,path) |
A convenience method to download the contents of a given URL to local storage, specified by a relative path. |
save(path) |
Saves the temporary file at the given path to a permanent location, using the AssetStore (S3 in production). This method will return a publicly accessible or authenticated URL to the file, which is usually what you’ll want to output. |
input_path |
If the input is a URL, it will automatically be downloaded for you to local storage before the action begins. input_path gives you the local path to the input file. |
In addition, all actions run within a work-unit-specific temporary directory, so relative paths work great for saving and loading scratch files, and all your scratch work will be automatically deleted at the end of the action.
The “Hello World” of MapReduce is to perform a distributed word count. So let’s implement a word_count action in what will be essentially two lines of code. We define process to use the UNIX wc utility to count the number of words in the input file (we’d prefer not to read the file into memory). We define merge to sum the total resulting word counts across all inputs. The complete class reads like this:
class WordCount < CloudCrowd::Action
def process
(`wc -w #{input_path}`).match(/\A\s*(\d+)/)[1].to_i
end
def merge
input.inject(0) {|sum, count| sum + count }
end
end
You can see how WordCount’s process returns the numeric count, and merge receives as its input the array of resulting counts. The input to process was the URL to a text file, so the file had been automatically downloaded before process was called, and made available through input_path.
There are many more examples available, both in the example configuration folder that crowd install provides, as well as in the Gallery of Actions.