这一步很多步骤和上面的数据清洗过程是类同的,相同的部分就仅展示过程截图了。
新建MapReduce项目:
由于中文分词和英文的词频统计有较大差异,我们无法通过简单的分隔符来切割中文的句子和段落(会造成语义问题),因此这里我借助了一个开源的第三方分词库 IKanalyzer。
下载地址(谷歌代码仓库):http://code.google.com/archive
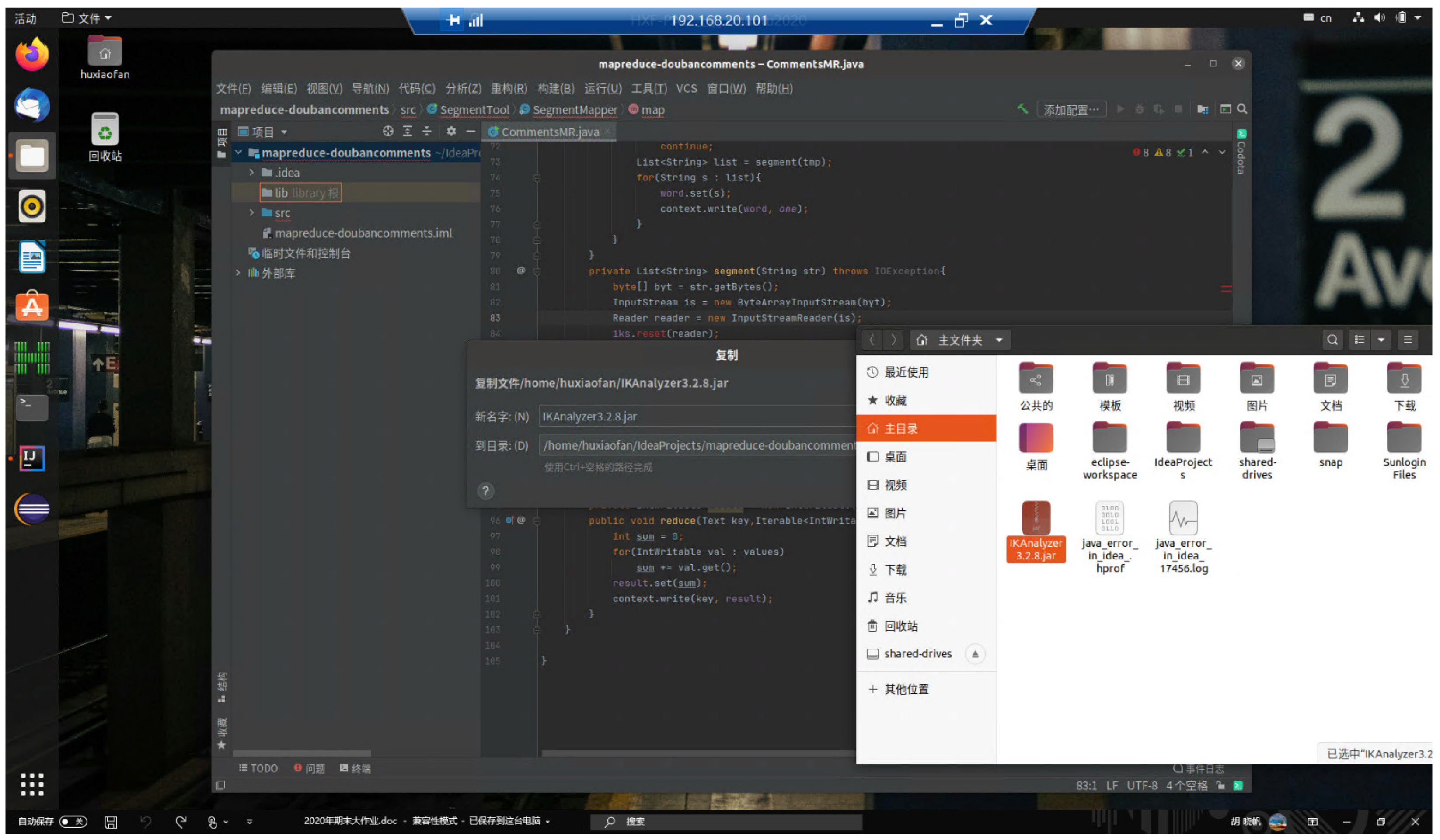
下载完成后,将分词包拖到项目的库文件目录中:(这里我使用的版本是3.2.8)
Map阶段代码:
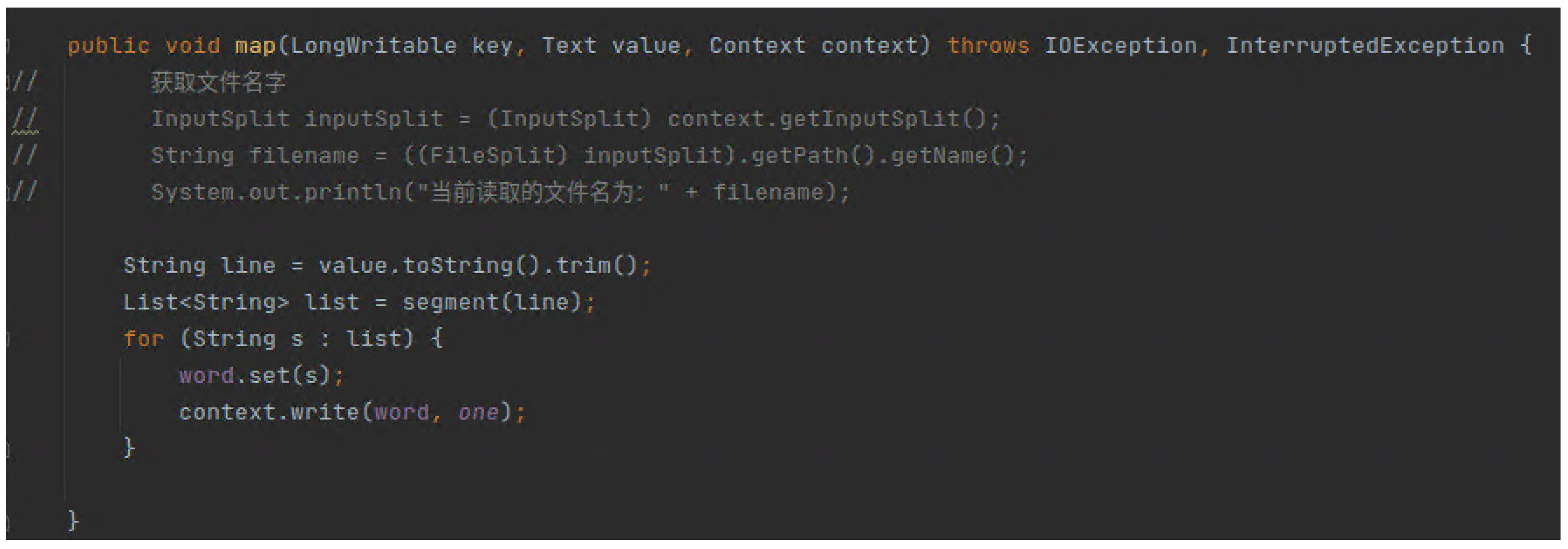
分词处理代码:


Reduce阶段代码:
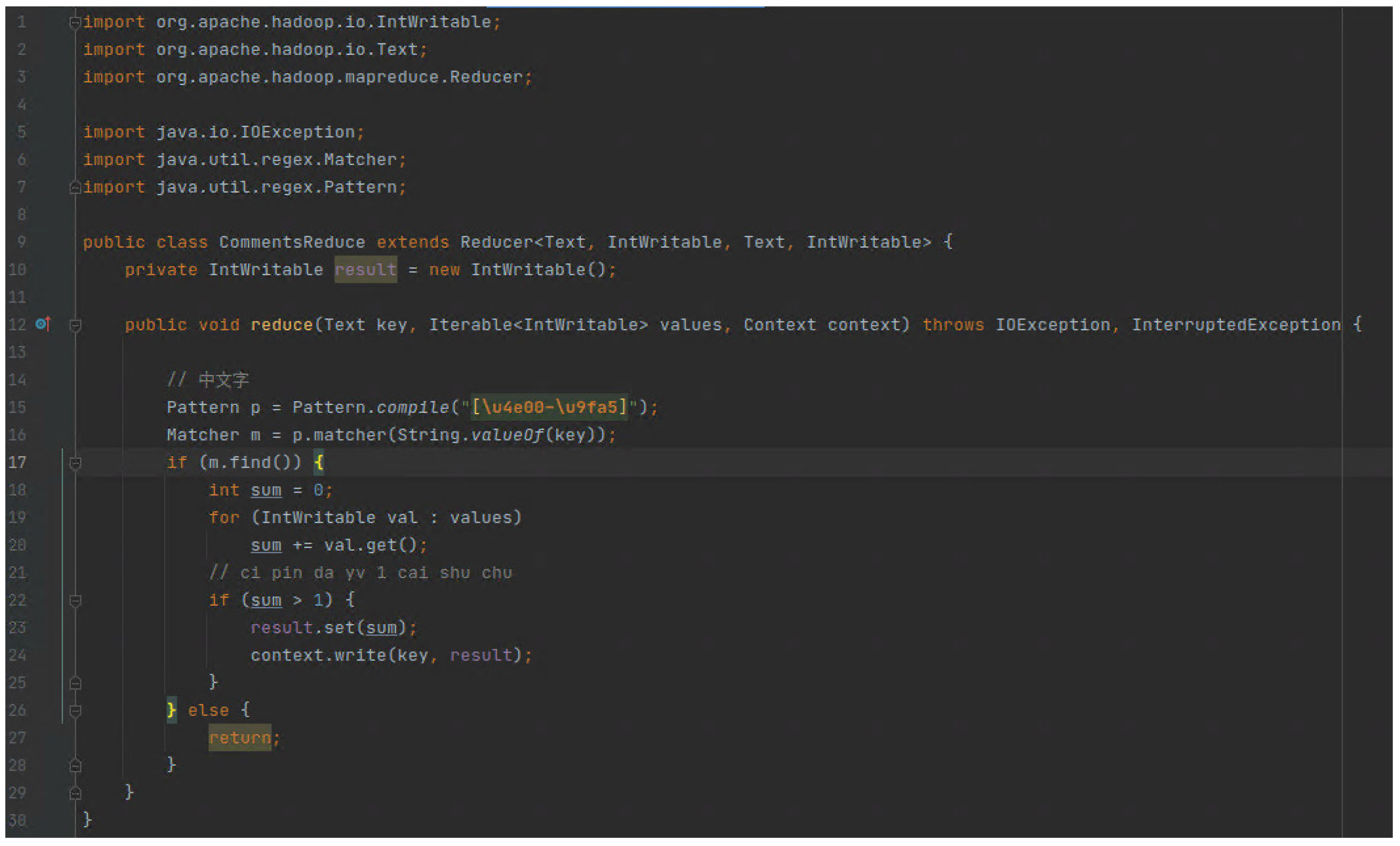
这里使用正则表达式进行筛选,仅保留中文分词结果。并同时 将value进行规约。
这部分代码主要是指定Mapper类,Reduce类,指定文件的输入输出信息以及期交MapReduce作业。
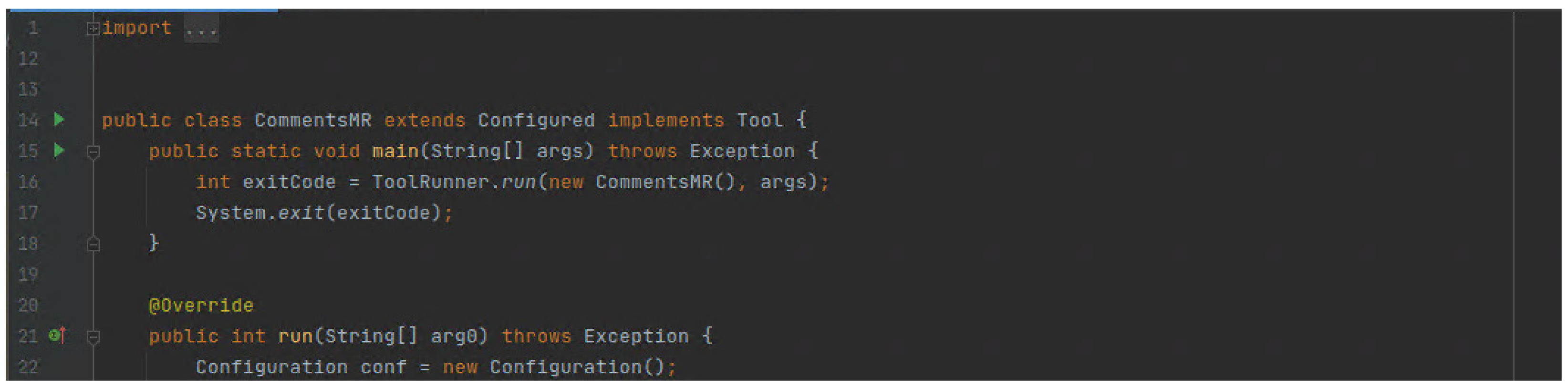
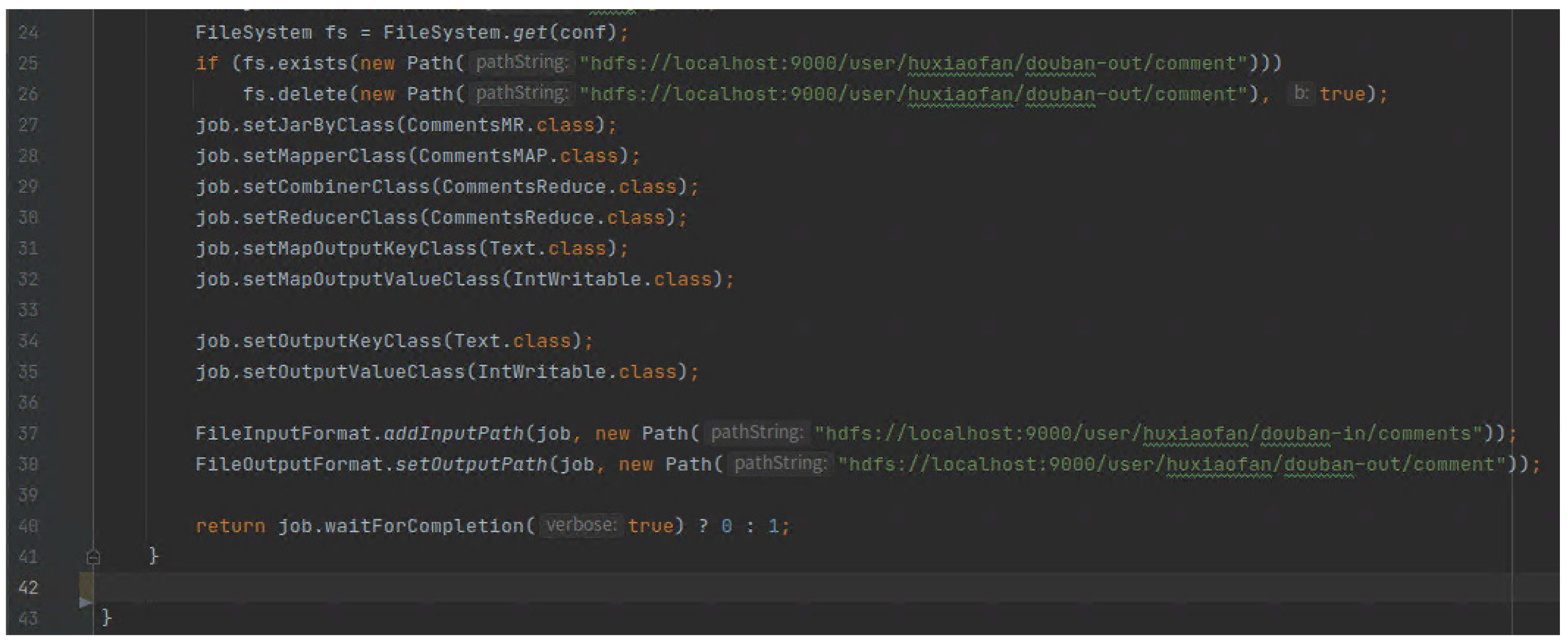
打包并运行MapReduce:
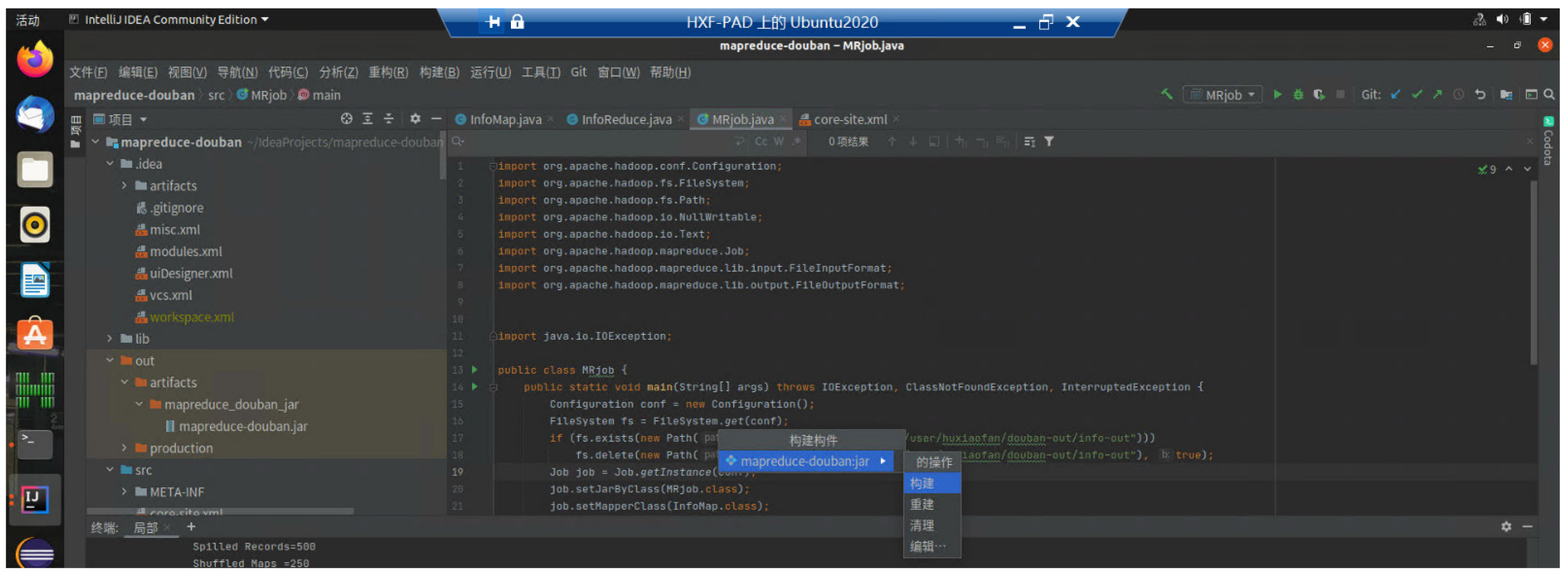
查看运行结果:
运行完成后可以通过浏览HDFS的输出文件夹查看效果。
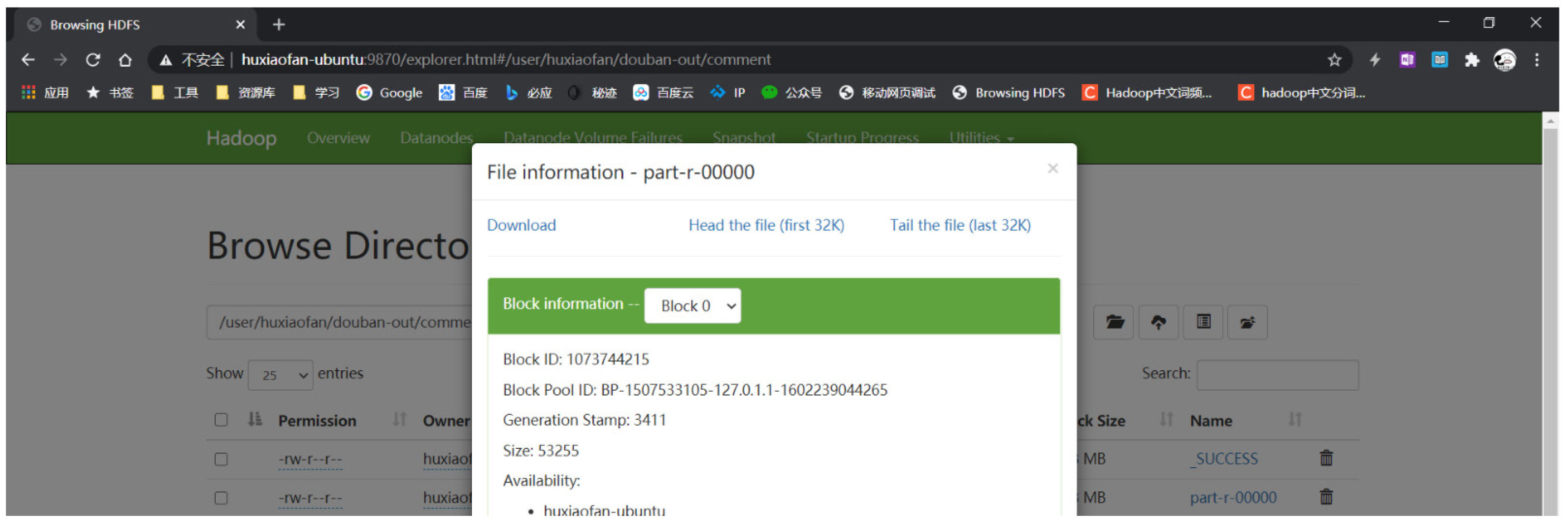
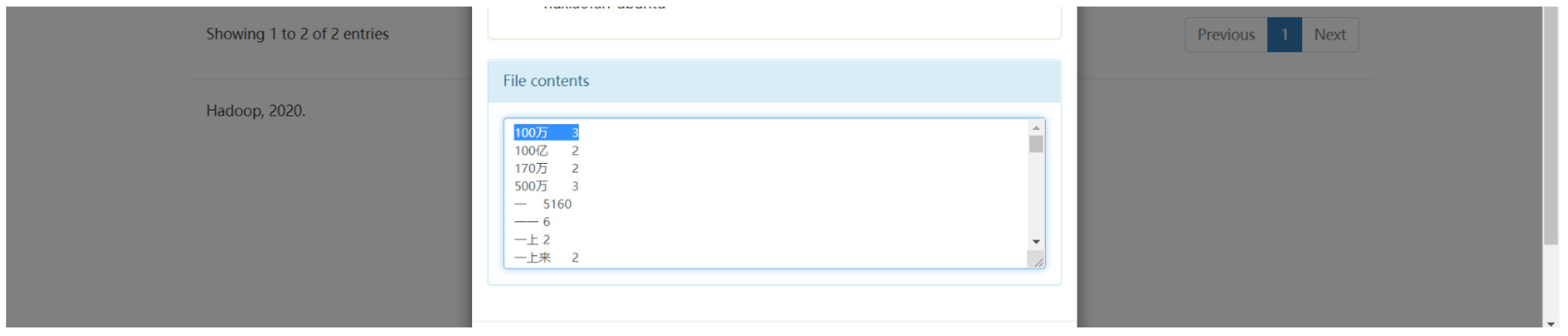
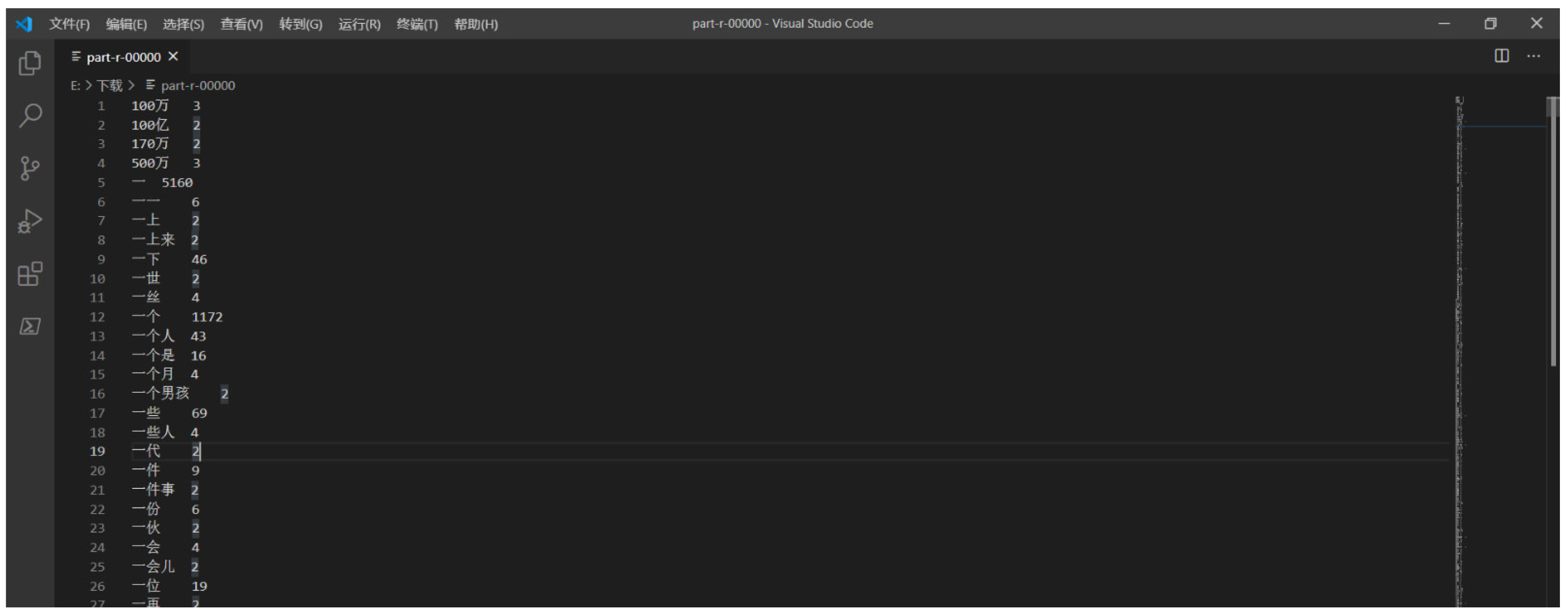
将HDFS的文件下载到本地 后,可以 看到基于中文分词的词频统计