{kind=link}
{kind=link}
Top 20% entry for Kaggle Freesound Audio Tagging 2019 competition
The goal of this competition was to build a multi-label classifier to recognize sounds in audio samples from a dictionary of 80 common sounds. My best solution was to convert the sounds to mel spectogram images and apply deep learning classifiers.
More info can be found at the Kaggle site: https://www.kaggle.com/c/freesound-audio-tagging-2019/overview
The data consists of 4970 audio samples (.wav files) that have been classified by human listeners according to 80 labels (for example, Applause, Bark, Accordion, Bus, Cheering, etc.) In addition a 'noisy' data set was also provided, where the training labels were generated by a predictive model. This data set did not seem to help the training results in my experiment.
A few audio samples were removed, becuase there was an error in labeling them.
Feature Generation was inspired by this starter kernel: https://www.kaggle.com/daisukelab/cnn-2d-basic-solution-powered-by-fast-ai
One of the drawbacks of this approach is that image classifiers handle rgb images (3 channels) yet the mel spectrograms reflect greyscale images (all channels get the same info). I tried some additional experiments where I increased the frequency bands of the mel spectrogram and spread those across the three color channels. THe thought was that this would provide additional information to the network and avoid redundant channel info. Cross validation results showed that this did not produce better results, however.
Black and white Mel spectrogram (all channels equal)
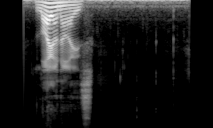
Colored Mel spectrogram (lower bands in red channel, mid bands in green channel, high bands in blue channel)

The mixup techique was used to generate additional training sample images based on weighted combinations of the existing data. These weighted combinations are then labelled with a weighted combination of the original labels. This resulted in a larger number of examples of sound combinations.
Resnet18 and Resnet34 were used, along with different mel spectrum sample parameters, as well as test time augmentation (or not).
Model selection was based on the best cross-validation scores.