EDSL
The EDSL is the experimental implementation of TLE-Raw.
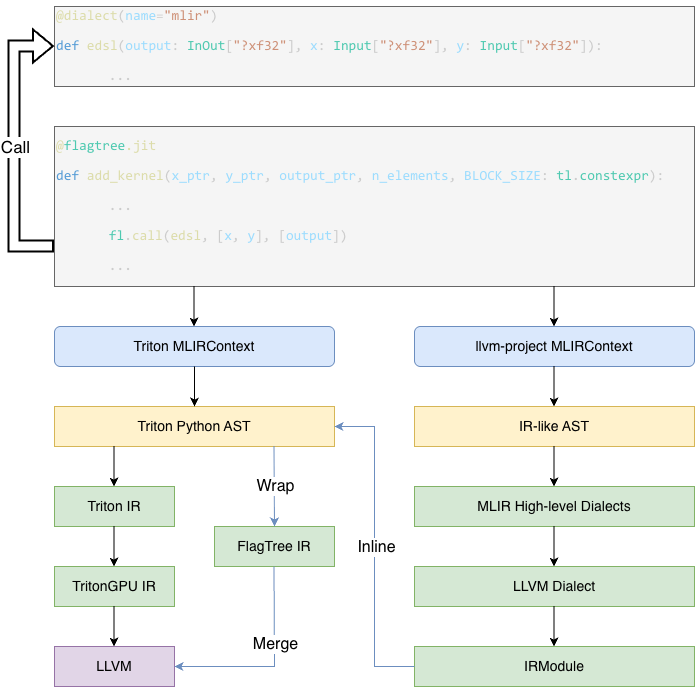
The main compilation pipeline of the EDSL is divided into two parts. On the one hand, the compiler compiles EDSL kernels and extracts the generated code as strings. On the other hand, we establish a pipeline to inject the compiled MLIR strings into the original Triton IR.
The code responsible for EDSL kernel compilation is primarily maintained in the python/triton/experimental/flagtree directory. The entry point that triggers EDSL kernel compilation is the dialect function in python/triton/experimental/flagtree/edsl/runtime.py. This function constructs an EdslMLIRJITFunction object to store kernel-related metadata and compilation state.
The EdslMLIRCodeGenerator, defined in python/triton/experimental/flagtree/edsl/mlir/codegen.py, specifies the frontend code parsing rules and describes how to lower Python code into the corresponding MLIR representation. Subsequently, EdslMLIRJITFunction applies a predefined compilation pipeline to lower the MLIR code, ultimately producing MLIR that is largely based on the LLVM Dialect. This portion of the generated MLIR is extracted as a string and passed to the next stage of processing.
Function parameters currently require annotations, which fall into two categories. One is InOut, indicating that the parameter may be modified within the function, and the other is Input, indicating that the parameter is read-only and must not be modified. During frontend code processing, if a parameter is annotated as InOut, it is automatically returned in the generated MLIR code to facilitate SSA-based analysis of value changes in Triton kernels.
The annotations are required to specify shape and type information in the MLIR text format, which are subsequently translated into the corresponding memref types for LLVM code generation.
In the original Triton kernel, we introduce a new operation named fl.call to invoke the previously defined EDSL kernels. This operation takes three arguments: the first is the kernel object being invoked, the second is the output list, and the third is the input list. The output list and input list are concatenated in order to form the operands of the compiled LLVM function, while the types of the output list define the return types of the LLVM function.
In Triton, the most critical change we introduce is a new operation, FlagTree_DSLRegionOp, which takes the arguments provided by fl.call and is used to encapsulate the previously compiled MLIR code in the LLVM Dialect. In create_edsl_region_by_llvm_func within python/src/flagtree_ir.cc, we describe how an EDSL kernel function is transformed into a DSLRegionOp. Within its region, the types of the operands are used to construct the parameter list, and additional ExtractOps are introduced as placeholders to represent extracting the required argument information from Triton Tensor types for the original LLVM function. The transformation then copies all previously generated LLVM code except for llvm.return. When an llvm.return is encountered, a PackOp is inserted to represent reassembling the existing return values back into Triton Tensors, which are then propagated to the outer scope via yield. Since the necessary memory allocation information is not yet available at this stage, these placeholders are subsequently lowered to concrete LLVM instructions during later lowering passes.
During the lowering process, the key components are implemented in lib/Conversion/FlagTreeToLLVM and lib/Dialect/FlagTree/Transforms. Among them, three aspects are particularly important. First, shared memory is allocated in the TritonGPU Dialect to replace the operands of DSLRegionOp. Second, DSLRegionOp is removed during lowering to the LLVM Dialect. Finally, a set of conversion rules is defined for lowering the various ExtractOps and PackOps.
In Triton, tensors are often allocated in registers, which prevents different threads within an EDSL kernel from accessing arbitrary elements of a tensor. Therefore, before entering DSLRegionOp, we first copy the tensor contents into shared memory to ensure that all threads within the same thread block can randomly access any part of the tensor. After DSLRegionOp, the data in shared memory is copied back into tensors, which are then used to replace subsequent references. The corresponding implementation can be found in lib/Dialect/FlagTree/Transforms/ConvertArgToMemDesc.cpp.
Specifically, for each input tensor, we allocate a region of shared memory using LocalAllocOp and populate it with the tensor contents via LocalStoreOp. After the execution of DSLRegionOp, a new LocalLoadOp is inserted to load the data from shared memory back into tensors, and the allocated memory is released using LocalDeallocOp. One notable design choice is that, to ensure alignment between the parameters of Triton kernels and EDSL kernels, we explicitly enforce that all shared memory allocations disable swizzling optimizations and adopt a row-major layout.
In lib/Dialect/FlagTree/Transforms/DSLRegionInline.cpp, DSLRegionOp is eliminated and fully inlined into the LLVM code of the Triton kernel.
In MLIR, a default memref is lowered into a representation such as
llvm.struct<llvm.ptr, llvm.ptr, i64, array<?xi64>, array<?xi64>>.
As a result, the various ExtractOps are ultimately lowered based on this representation. Meanwhile, the shared memory allocated in the previous step is lowered into a structure similar to llvm.struct<llvm.ptr, i32, ...>. Accordingly, the lowering strategies for these operations are defined as follows:
-
ExtractAllocatedPtrOpis lowered to the pointer of the shared memory. -
ExtractAlignedPtrOpis lowered to the pointer of the shared memory. -
ExtractOffsetOpis lowered to a constant zero. -
ExtractSizesOpis lowered to the corresponding tensor sizes. -
ExtractStridesOpcomputes the stride for each dimension based on the tensor sizes, assuming a row-major layout.
The current EDSL implementation depends on a customized llvm-project build with Python bindings. Since the development version is still unstable, we recommend installing it inside a virtual environment to avoid affecting your system setup. You can follow the steps below to obtain and install it.
git clone https://github.com/triton-lang/llvm-project.git
git checkout triton-3.5Next, build it from source. Make sure your environment already has all the required dependencies for compiling llvm-project. Then, compile it using the following commands
cmake -G Ninja -B build -S llvm -DLLVM_ENABLE_PROJECTS="mlir;llvm;lld" -DLLVM_TARGETS_TO_BUILD="host;NVPTX;AMDGPU" -DCMAKE_BUILD_TYPE=Debug -DCMAKE_EXPORT_COMPILE_COMMANDS=ON -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DLLVM_ENABLE_LLD=ON -DMLIR_ENABLE_BINDINGS_PYTHON=ON
cmake --build buildAfter the build completes, you should be able to find the generated Python artifacts under build/tools/mlir/python_packages/mlir_core/mlir/. Next, you need to make them available to your Python interpreter. A safer approach is to do this by setting environment variables
export PYTHONPATH=<LLVM_PROJECT_PREFIX_PATH>/build/tools/mlir/python_packages/mlir_core/mlir/:${PYTHONPATH}If you are confident that it will not affect your host environment, you may also directly link it into your Python package manager
ln -s <LLVM_PROJECT_PREFIX_PATH>/build/tools/mlir/python_packages/mlir_core/mlir/ <PYTHON_PREFIX_PATH>/lib64/python3.10/site-packages/mlirIn the future, we plan to release our own managed llvm-project wheel package with Python bindings.
now we implement it, see below
- Install Prerequisites
apt install clang
- Clone the LLVM Wheel Builder && Build the Wheel Package
git clone --recursive https://github.com/starrryz/llvm-wheel.git
cd llvm-wheel
python -m build -w
This tool is used to build and package the corresponding version of LLVM into a wheel package. The default LLVM version is from: https://github.com/flagos-ai/llvm-project/tree/triton-3.5
- Install the LLVM Wheel
pip install ./dist/llvm_wheel-0.1.0-cp{}-cp{}-linux_x86_64.whl --force-reinstall
After installing the LLVM wheel, you can proceed with FlagTree's own build process.
- Clone FlagTree Repository and Install Dependencies
git clone --branch triton_v3.5_edsl https://github.com/flagos-ai/flagtree.git
cd flagtree
apt install zlib1g zlib1g-dev libxml2 libxml2-dev # Ubuntu
cd python
python3 -m pip install -r requirements.txt
- Install FlagTree Package (Nvidia Backend)
cd flagtree
python3 -m pip install . --no-build-isolation -v