This is the code for Symbolic Integration by integrating learning models with different strengths and weaknesses. This project is carried out by Funahashi Lab. at Keio University.
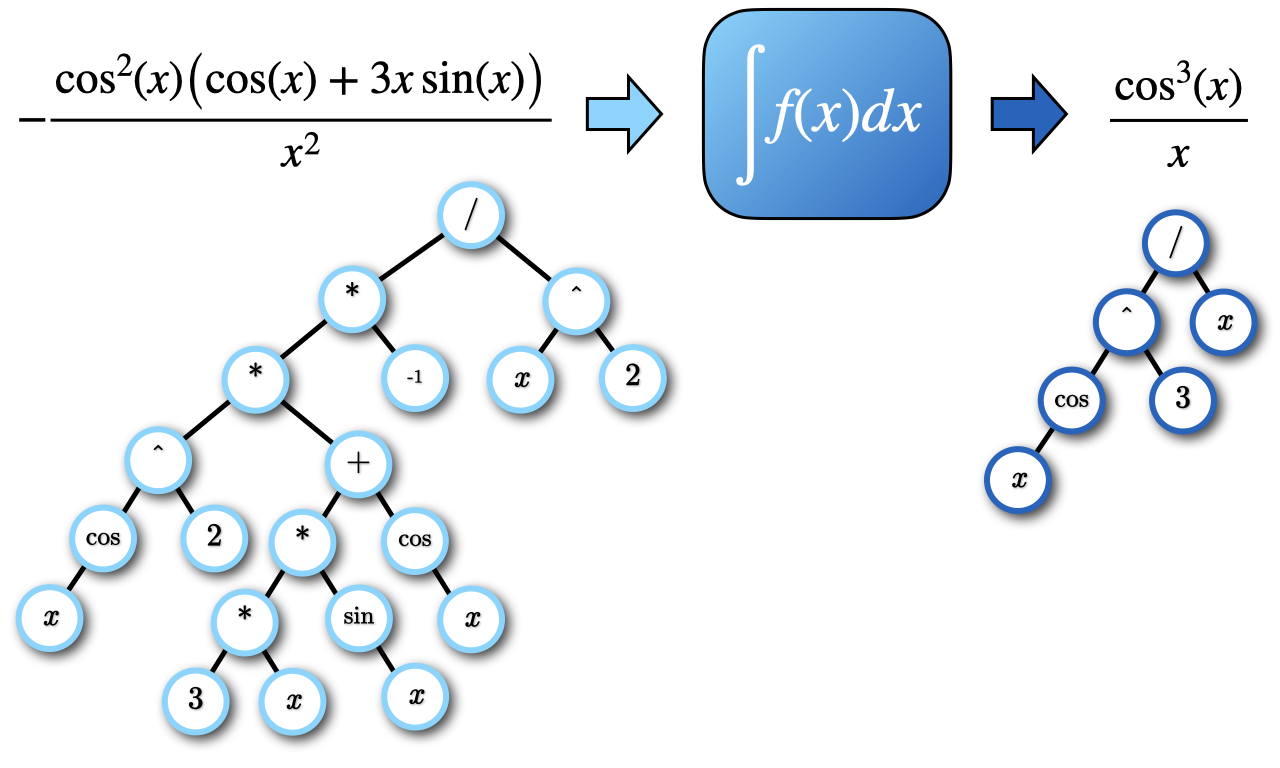
We developed following eight learning models for symbolic integration that were combinations of input-output schemes (string/subtree, polish/IRPP) and learning models (LSTM/Transformer).
- LSTM string polish model
- LSTM string IRPP model
- LSTM subtree polish model
- LSTM subtree IRPP model
- Transformer string polish model
- Transformer string IRPP model
- Transformer subtree polish model
- Transformer subtree IRPP model
We have tested SymbolicIntegrator on the following environments.
- CPU version
- macOS Catalina 10.15.7 (MacBookPro16,2)
- CPU: Intel i7-1068NG7 (8) @ 2.30GHz
- Memory: 32GB
- Python: 3.6.3
- GPU version
- Ubuntu 18.04.5 LTS x86_64
- CPU: Intel Xeon Silver 4114 (40) @ 3.000GHz
- GPU: NVIDIA Tesla V100 PCIe 32GB
- Memory: 96GB
- Python: 3.7.6 (conda 4.9.2)
-
Download this repository by
git clone.% git clone https://github.com/funalab/SymbolicIntegrator.git
-
Install requirements.
-
CPU version
% cd SymbolicIntegrationModel/ % python -m venv venv % source ./venv/bin/activate % pip install -r requirements.txt
-
GPU version (requires Anaconda)
% cd SymbolicIntegrationModel/ % conda create --name symbolic --file conda-spec-file.txt % conda activate symbolic
-
-
Download learned model and dataset (5.3 GB).
- On Linux:
% wget https://fun.bio.keio.ac.jp/software/SymbolicIntegrationModel/SymbolicIntegrationModel.zip % unzip SymbolicIntegrationModel.zip % rm SymbolicIntegrationModel.zip
- On macOS:
% curl -O https://fun.bio.keio.ac.jp/software/SymbolicIntegrationModel/SymbolicIntegrationModel.zip % unzip SymbolicIntegrationModel.zip % rm SymbolicIntegrationModel.zip
- On Linux:
-
Inference on test dataset.
To run LSTM models, follow the commands below after change directory.
-
LSTM string polish model
The best learned model for LSTM string polish model is
LSTM_string/model/LSTM_string_polish_best_model. To verify the accuracy of the learned model using test data (10 functions) inLSTM_string/dataset/LSTM_string_Polish_test_Integrand_first_10eq.txt, run the following:% cd LSTM_string/src % python LSTM_string_polish_model.py --token_dataset ../dataset/LSTM_string_polish_token.txt --Integrand_dataset ../dataset/LSTM_string_Polish_test_Integrand_first_10eq.txt --Primitive_dataset ../dataset/LSTM_string_Polish_test_Primitive_first_10eq.txt --study_name MLP_cupy_successiveHalvingPruner_epoch30_complete_correct_2nd_try_cross_valid --learned_model ../model/LSTM_string_polish_best_model [--gpu id] -
LSTM string IRPP model
The best learned model for LSTM string IRPP model is
LSTM_string/model/LSTM_string_IRPP_best_model. To verify the accuracy of the learned model using test data (10 functions) inLSTM_string/dataset/LSTM_string_IRPP_test_Integrand_first_10eq.txt, run the following:% cd LSTM_string/src % python LSTM_string_IRPP_model.py --token_dataset ../dataset/LSTM_string_polish_token.txt --Integrand_dataset ../dataset/LSTM_string_IRPP_test_Integrand_first_10eq.txt --Primitive_dataset ../dataset/LSTM_string_IRPP_test_Primitive_first_10eq.txt --study_name MLP_cupy_MedianPruner_epoch30_integrand_reverse_polish_Primitive_polish_third_try_memory_edited_v102_continue_untilepoch200 --learned_model ../model/LSTM_string_IRPP_best_model [--gpu id] -
LSTM subtree polish model
The best learned model for LSTM subtree polish model is
LSTM_subtree/model/LSTM_subtree_polish_best_model. To verify the accuracy of the learned model using test data (10 functions) inLSTM_subtree/dataset/LSTM_subtree_polish_test_Integrand_first_10eq.txt, run the following:% cd LSTM_subtree/src % python LSTM_subtree_model.py --token_dataset ../dataset/LSTM_subtree_polish_token.txt --Integrand_dataset ../dataset/LSTM_subtree_polish_test_Integrand_first_10eq.txt --Primitive_dataset ../dataset/LSTM_subtree_polish_test_Primitive_first_10eq.txt --study_name MLP_cupy_MedianPruner_epoch30_subtree_complete_correct_continue --learned_model ../model/LSTM_subtree_polish_best_model [--gpu id] -
LSTM subtree IRPP model
The best learned model for LSTM subtree IRPP model is
LSTM_subtree/model/LSTM_subtree_IRPP_best_model. To verify the accuracy of the learned model using test data (10 functions) inLSTM_subtree/dataset/LSTM_subtree_IRPP_test_Integrand_first_10eq.txt, run the following:% cd LSTM_subtree/src % python LSTM_subtree_model.py --token_dataset ../dataset/LSTM_subtree_IRPP_token.txt --Integrand_dataset ../dataset/LSTM_subtree_IRPP_test_Integrand_first_10eq.txt --Primitive_dataset ../dataset/LSTM_subtree_IRPP_test_Primitive_first_10eq.txt --study_name MLP_cupy_MedianPruner_epoch30_subtree_Integrand_reverse_polish_Primitive_polish_continue --learned_model ../model/LSTM_subtree_IRPP_best_model [--gpu id]
The following list of options will be displayed by adding -h option to each script for LSTM models.
--Integrand_dataset : Specify Integrand data (text file). --Primitive_dataset : Specify Primitive data (text file). --token_dataset : Specify dictionary of mathematical symbols used in Integrand and Primitive data (text file). --study_name : Specify hyperparameter values from Optuna result (SQLite database). --learned_model : Specify learned model (npz file). --gpu id, -g id : Specify GPU ID (negative value indicates CPU).To run Transformer models, follow the commands below after change directory.
-
Transformer string polish model
The best learned model for Transformer string polish model is
Transformer_string/model/Transformer_string_polish_best_model. To verify the accuracy of the learned model using test data (10 functions) inTransformer_string/dataset/Transformer_string_polish_test_Integrand_first_10eq.txt, run the following:% cd Transformer_string/src % python Transformer_string_model.py --source ../dataset/Transformer_string_polish_test_Integrand_first_10eq.txt --target ../dataset/Transformer_string_polish_test_Primitive_first_10eq.txt --source_vocab_list ../dataset/Transformer_string_polish_Integrand_vocab.pickle --target_vocab_list ../dataset/Transformer_string_polish_Primitive_vocab.pickle --learned_model ../model/Transformer_string_polish_best_model [--gpu id] -
Transformer string IRPP model
The best learned model for Transformer string IRPP model is
Transformer_string/model/Transformer_string_IRPP_best_model. To verify the accuracy of the learned model using test data (10 functions) inTransformer_string/dataset/Transformer_string_IRPP_test_Integrand_first_10eq.txt, run the following:% cd Transformer_string/src % python Transformer_string_model.py --source ../dataset/Transformer_string_IRPP_test_Integrand_first_10eq.txt --target ../dataset/Transformer_string_IRPP_test_Primitive_first_10eq.txt --source_vocab_list ../dataset/Transformer_string_IRPP_source_vocab.pickle --target_vocab_list ../dataset/Transformer_string_IRPP_target_vocab.pickle --learned_model ../model/Transformer_string_IRPP_best_model [--gpu id] -
Transformer subtree polish model
The best learned model for Transformer subtree polish model is
/Transformer_subtree/model/Transformer_subtree_polish_best_model. To verify the accuracy of the learned model using test data (10 functions) inTransformer_subtree/dataset/Transformer_subtree_polish_test_Integrand_first_10eq.txt,run the following:% cd Transformer_subtree/src % python Transformer_subtree_model.py --source ../dataset/Transformer_subtree_polish_test_Integrand_first_10eq.txt --target ../dataset/Transformer_subtree_polish_test_Primitive_first_10eq.txt --source_vocab_list ../dataset/Transformer_subtree_polish_Integrand_vocab.pickle --target_vocab_list ../dataset/Transformer_subtree_polish_Primitive_vocab.pickle --learned_model ../model/Transformer_subtree_polish_best_model [--gpu id] -
Transformer subtree IRPP model
The best learned model for Transformer subtree IRPP model is
Transformer_subtree/model/Transformer_subtree_IRPP_best_model. To verify the accuracy of the learned model using test data (10 functions) inTransformer_subtree/dataset/Transformer_subtree_IRPP_test_Integrand_first_10eq.txt,run the following:% cd Transformer_subtree/src % python Transformer_subtree_model.py --source ../dataset/Transformer_subtree_IRPP_test_Integrand_first_10eq.txt --target ../dataset/Transformer_subtree_IRPP_test_Primitive_first_10eq.txt --source_vocab_list ../dataset/Transformer_subtree_IRPP_Integrand_vocab.pickle --target_vocab_list ../dataset/Transformer_subtree_IRPP_Primitive_vocab.pickle --learned_model ../model/Transformer_subtree_IRPP_best_model [--gpu id]
The following list of options will be displayed by adding -h option to each script for Transformer models.
--source : Specify Integrand data (text file). --target : Specify Primitive data (text file). --source_vocab_list : Specify dictionary of mathematical symbols used in Integrand data (pickle file). --target_vocab_list : Specify dictionary of mathematical symbols used in Primitive data (pickle file). --learned_model : Specify learned model (npz file). --gpu id, -g id : Specify GPU ID (negative value indicates CPU).To integrate the above eight models and perform inference, run the following:
% cd Integrated_all_model % ./run.sh [--gpu id | -g id] ../LSTM_string/dataset/LSTM_string_Polish_test_Integrand_first_10eq.txt
If you want to run it on the GPU, please specify the GPU ID with
--gpuor-goption (ex.--gpu 0). -
-
How to train (GPU recommended)
To train LSTM models with performing cross-validation, follow the commands below after change directory.
-
LSTM string polish model
To train LSTM string polish model using training dataset (20 functions) in
LSTM_string/dataset/LSTM_string_Polish_train_valid_Integrand_first_20eq.txt, run the following:% cd LSTM_string/src % python LSTM_string_polish_train.py --batchsize 5 --epoch 2 --kfold 0 --token_dataset ../dataset/LSTM_string_polish_token.txt --Integrand_dataset ../dataset/LSTM_string_Polish_train_valid_Integrand_first_20eq.txt --Primitive_dataset ../dataset/LSTM_string_Polish_train_valid_Primitive_first_20eq.txt --study_name MLP_cupy_successiveHalvingPruner_epoch30_complete_correct_2nd_try_cross_valid_new --learned_model ../model/LSTM_string_polish_best_model_new [--gpu id]The trained model will be generated as
LSTM_string/model/LSTM_string_polish_best_model_new_fold_0/model_0/best_loss_model_epoch_2. -
LSTM string IRPP model
To train LSTM string IRPP model using training dataset (20 functions) in
LSTM_string/dataset/LSTM_string_IRPP_train_valid_Integrand_first_20eq.txt, run the following:% cd LSTM_string/src % python LSTM_string_IRPP_train.py --batchsize 5 --epoch 2 --kfold 0 --token_dataset ../dataset/LSTM_string_polish_token.txt --Integrand_dataset ../dataset/LSTM_string_IRPP_train_valid_Integrand_first_20eq.txt --Primitive_dataset ../dataset/LSTM_string_IRPP_train_valid_Primitive_first_20eq.txt --study_name MLP_cupy_MedianPruner_epoch30_integrand_reverse_polish_Primitive_polish_third_try_memory_edited_v102_continue_untilepoch200_new --learned_model ../model/LSTM_string_IRPP_best_model_new [--gpu id]The trained model will be generated as
LSTM_string/model/LSTM_string_IRPP_best_model_new_fold_0/model_0/best_loss_model_epoch_2. -
LSTM subtree polish model
To train LSTM subtree polish model using training dataset (20 functions) in
LSTM_subtree/dataset/LSTM_subtree_polish_train_valid_Integrand_first_20eq.txt, run the following:% cd LSTM_subtree/src % python LSTM_subtree_polish_train.py --batchsize 5 --epoch 2 --kfold 0 --token_dataset ../dataset/LSTM_subtree_polish_token.txt --Integrand_dataset ../dataset/LSTM_subtree_polish_train_valid_Integrand_first_20eq.txt --Primitive_dataset ../dataset/LSTM_subtree_polish_train_valid_Primitive_first_20eq.txt --study_name MLP_cupy_MedianPruner_epoch30_subtree_complete_correct_continue_new --learned_model ../model/LSTM_subtree_polish_best_model_new [--gpu id]The trained model will be generated as
LSTM_subtree/model/LSTM_subtree_polish_best_model_new_fold_0/model_0/best_loss_model_epoch_2. -
LSTM subtree IRPP model
To train LSTM subtree IRPP model using training dataset (20 functions) in
LSTM_subtree/dataset/LSTM_subtree_IRPP_train_valid_Integrand_first_20eq.txt, run the following:% cd LSTM_subtree/src % python LSTM_subtree_IRPP_train.py --batchsize 5 --epoch 2 --kfold 0 --token_dataset ../dataset/LSTM_subtree_IRPP_token.txt --Integrand_dataset ../dataset/LSTM_subtree_IRPP_train_valid_Integrand_first_20eq.txt --Primitive_dataset ../dataset/LSTM_subtree_IRPP_train_valid_Primitive_first_20eq.txt --study_name MLP_cupy_MedianPruner_epoch30_subtree_Integrand_reverse_polish_Primitive_polish_continue_new --learned_model ../model/LSTM_subtree_IRPP_best_model_new [--gpu id]The trained model will be generated as
LSTM_subtree/model/LSTM_subtree_IRPP_best_model_new_fold_0/model_0/best_loss_model_epoch_2.
The following list of options will be displayed by adding -h option to each script for training LSTM models.
--batchsize : Specify batchsize (int). --epoch : Specify epoch (int). --kfold : Specify the fold number for 10-fold cross validation (an integral number from 0 to 9) --Integrand_dataset : Specify Integrand data for training (text file). --Primitive_dataset : Specify Primitive data for training (text file). --token_dataset : Specify dictionary of mathematical symbols used in Integrand and Primitive data (text file). --study_name : Specify the arbitrary name of SQLite file for hyperparameter values from Optuna result (SQLite database). --learned_model : Specify the arbitrary directory name for learned models and log file (npz file). --gpu id, -g id : Specify GPU ID (negative value indicates CPU).To train Transformer models with performing cross-validation, follow the commands below after change directory.
-
Transformer string polish model
To train Transformer string polish model using training dataset (20 functions) in
Transformer_string/dataset/Transformer_string_polish_train_valid_Integrand_first_20eq.txt, run the following:% cd Transformer_string/src % python Transformer_string_train.py --batchsize 5 --epoch 2 -kfold 0 --source ../dataset/Transformer_string_polish_train_valid_Integrand_first_20eq.txt --target ../dataset/Transformer_string_polish_train_valid_Primitive_first_20eq.txt --out ../model/Transformer_string_polish_best_model_new --source-vocab 67 --target-vocab 67 [--gpu id]The trained model will be generated as
Transformer_string/model/Transformer_string_polish_best_model_new/best_model_valid_loss.npz. -
Transformer string IRPP model
To train Transformer string IRPP model using traing dataset (20 functions) in
Transformer_string/dataset/Transformer_string_IRPP_train_valid_Integrand_first_20eq.txt, run the following:% cd Transformer_string/src % python Transformer_string_train.py --batchsize 5 --epoch 2 -kfold 0 --source ../dataset/Transformer_string_IRPP_train_valid_Integrand_first_20eq.txt --target ../dataset/Transformer_string_IRPP_train_valid_Primitive_first_20eq.txt --out ../model/Transformer_string_IRPP_best_model_new --source-vocab 67 --target-vocab 67 [--gpu id]The trained model will be generated as
Transformer_string/model/Transformer_string_IRPP_best_model_new/best_model_valid_loss.npz. -
Transformer subtree polish model
To train Transformer subtree polish model using traing dataset (20 functions) in
Transformer_subtree/dataset/Transformer_subtree_polish_train_valid_Integrand_first_20eq.txt, run the following:% cd Transformer_subtree/src % python Transformer_subtree_train.py --batchsize 5 --epoch 2 -kfold 0 --source ../dataset/Transformer_subtree_polish_train_valid_Integrand_first_20eq.txt --target ../dataset/Transformer_subtree_polish_train_valid_Primitive_first_20eq.txt --out ../model/Transformer_subtree_polish_best_model_new --source-vocab 67 --target-vocab 67 [--gpu id]The trained model will be generated as
Transformer_subtree/model/Transformer_subtree_polish_best_model_new/best_model_valid_loss.npz. -
Transformer subtree IRPP model
To train Transformer subtree IRPP model using traing dataset (20 functions) in
Transformer_subtree/dataset/Transformer_subtree_IRPP_train_valid_Integrand_first_20eq.txt, run the following:% cd Transformer_subtree/src % python Transformer_subtree_train.py --batchsize 5 --epoch 2 -kfold 0 --source ../dataset/Transformer_subtree_IRPP_train_valid_Integrand_first_20eq.txt --target ../dataset/Transformer_subtree_IRPP_train_valid_Primitive_first_20eq.txt --out ../model/Transformer_subtree_IRPP_best_model_new --source-vocab 67 --target-vocab 67 [--gpu id]The trained model will be generated as
Transformer_subtree/model/Transformer_subtree_IRPP_best_model_new/best_model_valid_loss.npz.
The following list of options will be displayed by adding -h option to each script for training Transformer models.
--batchsize : Specify batchsize (int). --epoch : Specify epoch (int). --kfold : Specify the fold number for 10-fold cross validation (an integral number from 0 to 9) --source : Specify Integrand data (text file). --target : Specify Primitive data (text file). --out : Specify the arbitrary directory name for learned models and log file --source_vocab : Specify maximum number of words in dictionary of mathematical symbols used in Integrand data (int). --target_vocab : Specify maximum number of words in dictionary of mathematical symbols used in Primitive data (int). --gpu id, -g id : Specify GPU ID (negative value indicates CPU). -
The development of this algorithm was funded by Japan Science and Technology Agency CREST grant (Grant Number: JPMJCR2011) to Akira Funahashi.