Microsoft is trying to help create machines that can have conversations by releasing a new set of data for free.
The data, called the Microsoft Machine Reading Comprehension dataset (MS MARCO) is a bundle of 100,000 English queries along with corresponding answers. It's supposed to help people build artificial intelligence systems that can understand human written language.
The queries in MS MARCO are based on anonymized questions that were submitted to Microsoft’s Bing search engine and Cortana virtual assistant. The answers are based on information found online, written by humans and checked for accuracy.
The data set can be downloaded from the link.
Imagine a Scaniro where medical student wants to operate a patient and during operation he wants to ask question from his/her supervisor. An Engineering student want to see the aircraft engine condition when it is running 10000 feet height with 320 km/hr and need to know various answers regarding aircraft enginnering. Not limited to that, we can create all scanrios where presence of human is impossible.
We can create all scanrios and an virtual agent can answers the user queries.For proof of concept Marco Dataset is considered and and models are built on subset of data as in initial step.
In this section the brief description of proccess followed with their respective Ipython Notebook is given. Instead of using All dataset, Only "yes & no" subset data is filtered out for Machine Learning purpose the subsetting code can be seen in Marco subsetting yes_no answers.ipynb. Further on the subset data, we deployed Gradient Boosting Machine and Deep Learning Model on the bag of words and tf-idf. The initial results and curves were not so good. We found imbalance class distribution between "yes and no", so we increased sample of "no" data by fraction 0.7 and had very excellent results. The results are compared in following section when data is dealt with imbalance calss and without.
Scoring history:
| Model | Bag of Words | tf-idf |
|---|---|---|
| Gradient BM | 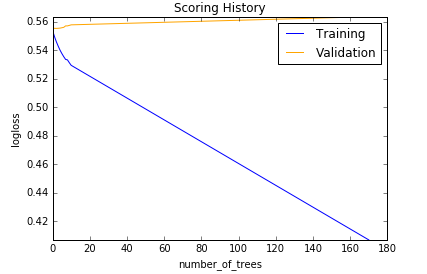 |
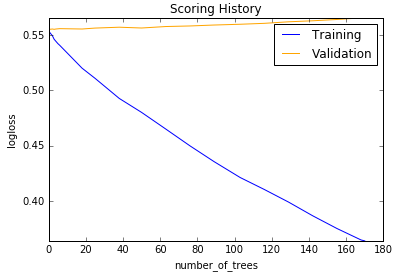 |
| Deep Learning | 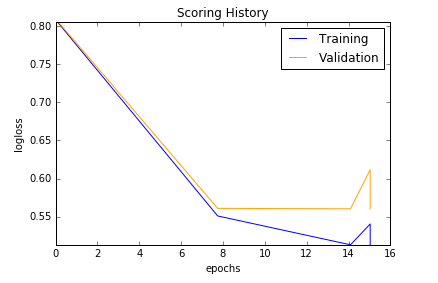 |
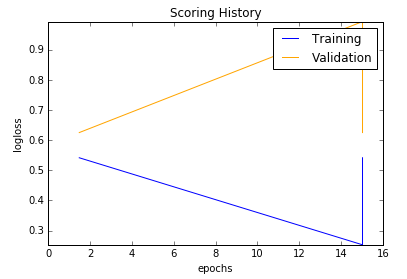 |
ROC:
| Model | Bag of Words | tf-idf |
|---|---|---|
| Gradient BM | 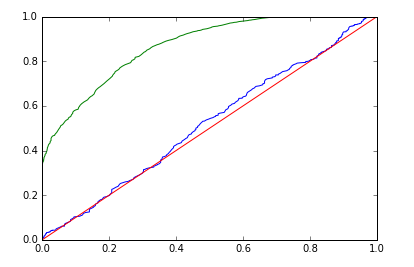 |
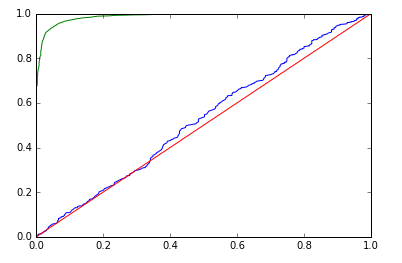 |
| Deep Learning | 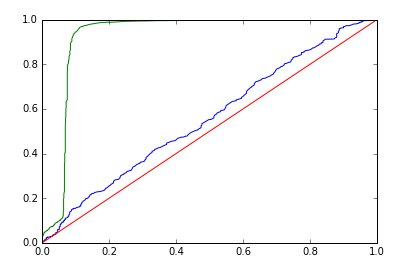 |
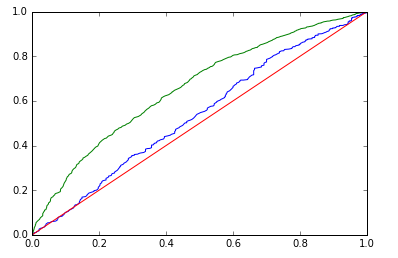 |
Aera Under the Curve:
| Model | Bag of Words | tf-idf |
|---|---|---|
| Gradient BM | Training AUC: 0.868, Validation AUC: 0.518 | Training AUC: 0.987, Validation AUC: 0.526 |
| Deep Learning | Training AUC: 0.927, Validation AUC: 0.556 | Training AUC: 0.658, Validation AUC: 0.536 |
Scoring history:
| Model | Bag of Words | tf-idf |
|---|---|---|
| Gradient BM | 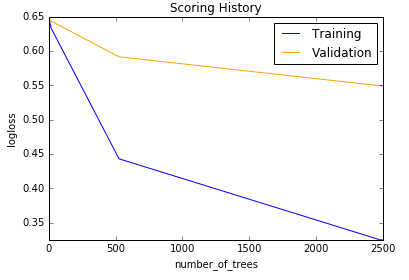 |
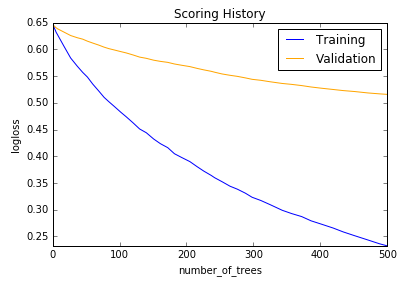 |
| Deep Learning | 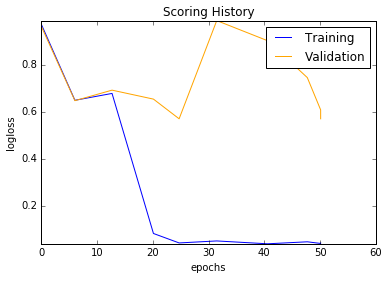 |
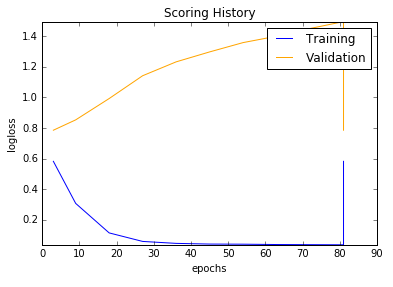 |
ROC:
| Model | Bag of Words | tf-idf |
|---|---|---|
| Gradient BM | 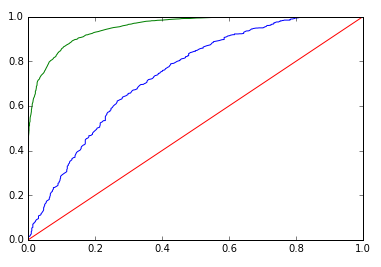 |
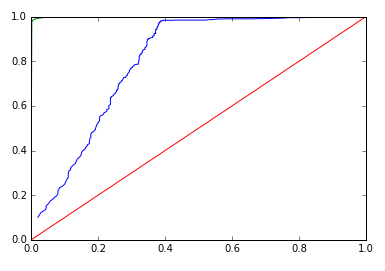 |
| Deep Learning | |
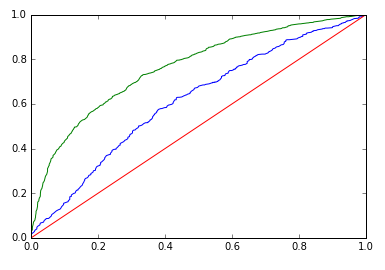 |
Aera Under the Curve:
| Model | Bag of Words | tf-idf |
|---|---|---|
| Gradient BM | Training AUC: 0.954, Validation AUC: 0.742 | Training AUC: 0.998, Validation AUC: 0.772 |
| Deep Learning | Training AUC: 0.998, Validation AUC: 0.802 | Training AUC: 0.763, Validation AUC: 0.614 |