#CIS 565 -- Fall 2013
##Overview
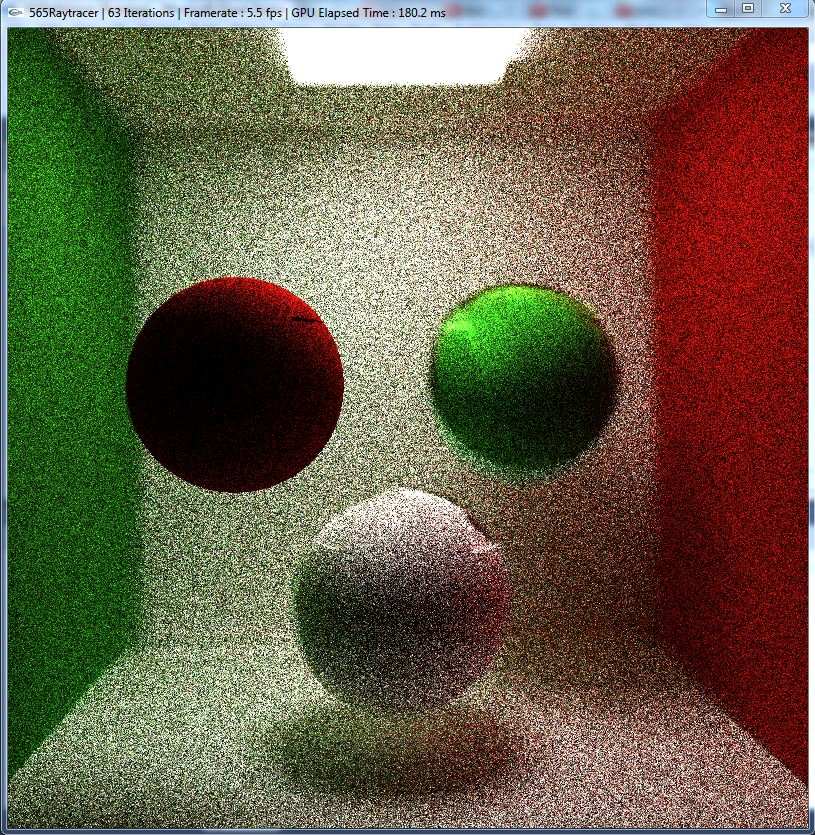
Taking our raytracing code from before, we hae modified the GPU raytracer into a GPU pathtracing supporting super-sampling anti-aliasing, depth of field, obj loading, and Fresnel. For optimization, we have implemented stream compaction.
<img src="https://raw.github.com/harmoli/Project2-Pathtracer/master/renders/test_glass_blue_dof.0.jpg" "Glass Blue">
{kind=link}
<img src="https://raw.github.com/harmoli/Project2-Pathtracer/master/renders/test1_dof.0.jpg" "Simple DOF">
{kind=link}
The features that will be discussed below are those in addition to the ones implemented in the raytracer. The discussion section will discuss some of the findings and observations when changing from the raytracer to pathtracer.
###OBJ Mesh Loading
We have implemented a simple obj mesh loader that ignores vertex and texture normals. We have designed it such that the mesh data is stored in separate structs that have indices to point to the start and end index of the mesh's faces in the serialized face array. We did this because the GPU requires serialized memory. Instead of adding complex structs and serializing them before sending them over to the GPU, we have opted for a simpler structure with more lookups.
As of now, the loader works; however, we have had trouble with color attenuation on the loaded mesh. As seen below, the normals and intersection passes seem to be fine. However, when running the renderer, the loaded object does not follow the normal shading rules. We have already considered the possibility of the ray internally reflecting, but increasing the offset of the newly cast ray does not seem to remedy this problem.
<img src="https://raw.github.com/harmoli/Project2-Pathtracer/master/renders/test.0.jpg" "Accumulation Problem on Icosahedron">
{kind=link}
We have implemented stream compaction using a shared memory verion of naive exclusive prefix sum in hopes of gaining performance from utilizing on-chip shared memory. This version requires a tail-recursion like method to reassemble the final output array from the different blocks by adding partial sums on the recall.
Much of our implementation was aided and informed by Ch. 39 (Parallel Prefix Sum with CUDA) of GPU Gems 3. The major modification to the code presentation is that we copy over the buffered array in every iteration of the scan step. We found that following their pseudocode resulted in inaccurate output arrays because the entries would be inconsistent in the buffer on the swap iteration.
###Fresnel Reflection and Refraction
We have implemented perfect relection, perfect refraction (Snell's law) and Fresnel Reflection/Refraction using Schlick's approximation. Due to its tree like approach to calculating reflection and refraction, unpolarized Fresnel has the potential to grow indefinitely. This would not be helpful when trying to use stream compaction. Thus, we have used Schlick's approximation to approximate the likelihood of refraction and reflection on each iteration and bounce of a ray. In line with the motivation behind path tracing, it relies on successive iterations to converge to a physically correct solution.
<img src="https://raw.github.com/harmoli/Project2-Pathtracer/master/renders/test_glass_mirrors_colored.0.jpg" "Colored Glass and Mirrors">
{kind=link}
##Discussion
While moving from a raytracer to a pathtracer, there were certain aspects of the code that produced interesting results. Here, we will present some of these hurdles, the ways in which we belief these things came about, and the subsequent fixes.
###Artifacts in Depth of Field
After implementing naive pathtracing, we added depth of field. When rendering diffuse objects, there were persistent artifacts that showed up on the spheres, as shown below.
Debugging showed that it resulted from jittering the position of the camera to achieve the effect. Interestingly, we found that, with the correct math to compute depth of field, we had odd renderings:
-
When changing the depth of field, the image would blur in a biased direction and then "restabilize" and become clear in a shifted direction. We found that this happened regardless of the maximum trace depth.
-
When changing the aperture, the spheres and the image would warp in a biased zig-zag pattern that was reproduced every time.
Because of this, we decided to change the seed input to the hashing function that produced random numbers to jitter our camera position. Originally, the seed was the product of the iteration and the pixel index (iterations * index); however, from the first point, we believe that increasing the seed by a factor of the time may have biased the generation to jitter less in a particular position as large float numbers have less precision from each other as they reach a limit. Thus, we changed the hash to only be seeded by the index, and that, effectively, fixed our problem.
<img src="https://raw.github.com/harmoli/Project2-Pathtracer/master/renders/ScreenShots/DOF_artifacts.JPG" "Artifacts in DOF">
{kind=link}
###Architecture Compilation
While debugging, we changed the compilation architecture from 1.0 to 3.0. Interestingly, this reduced the performance by 10 fold (from ~300 ms per frame to ~3000+ ms per frame). This also happens when changing from 1.0 to 2.0. Similarly, the kernel will fail in 2.0 and 3.0 unless we specifically sync threads after the pathtracing step in each iteration.
##Performance Analysis
###Effects of Stream Compaction
Overall, we see that path tracing without stream compaction generally scales linearly with trace depth : as trace depth increases, sec per frame increases and, thus, fps drops.
We see that stream compaction generally gives a 2x speedup. In this particular scene, stream compaction levels off in fps after 300+ depth.
Pathtracing without Stream Compaction
| Depth | Sec Per Frame | FPS |
|---|---|---|
| 100 | 520 ms | 1.7 |
| 200 | 523 ms | 1.8 |
| 300 | 628-632 ms | 1.5-1.6 |
Pathtracing with Stream Compaction
| Depth | Sec Per Frame | FPS |
|---|---|---|
| 100 | 270 ms | 3.5 |
| 200 | 270-290 ms | 3.4 |
| 300 | 273 - 305 ms | 3.1 |
###Effects of Block Size on Stream Compaction
We also played around with the block size for stream compaction. All measurements are taken on a simple reflective scene with trace depth of 1000.
| Block Size | Sec Per Fram | FPS |
|---|---|---|
| 64 | 387 ms | 2.9 - 3.3 |
| 128 | 325 ms | 3.1 - 3.4 |
| 256 | 300 ms | 3.2 |
<iframe src="//player.vimeo.com/video/77302993" width="500" height="513" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe>
GPU PathTracer from Harmony Li on Vimeo.
Many thanks to Karl Li for the starter code and Liam for explaining stream compaction.
Stream Compaction : http://http.developer.nvidia.com/GPUGems3/gpugems3_ch39.html
Fresnel : http://graphics.stanford.edu/courses/cs148-10-summer/docs/2006--degreve--reflection_refraction.pdf