A Docker-powered service for PDF document layout analysis and PDF OCR
This project provides a powerful and flexible PDF analysis service. The service enables OCR, segmentation, and classification of different parts of PDF pages, identifying elements such as texts, titles, pictures, tables, and so on. Additionally, it determines the correct order of these identified elements.

|

|
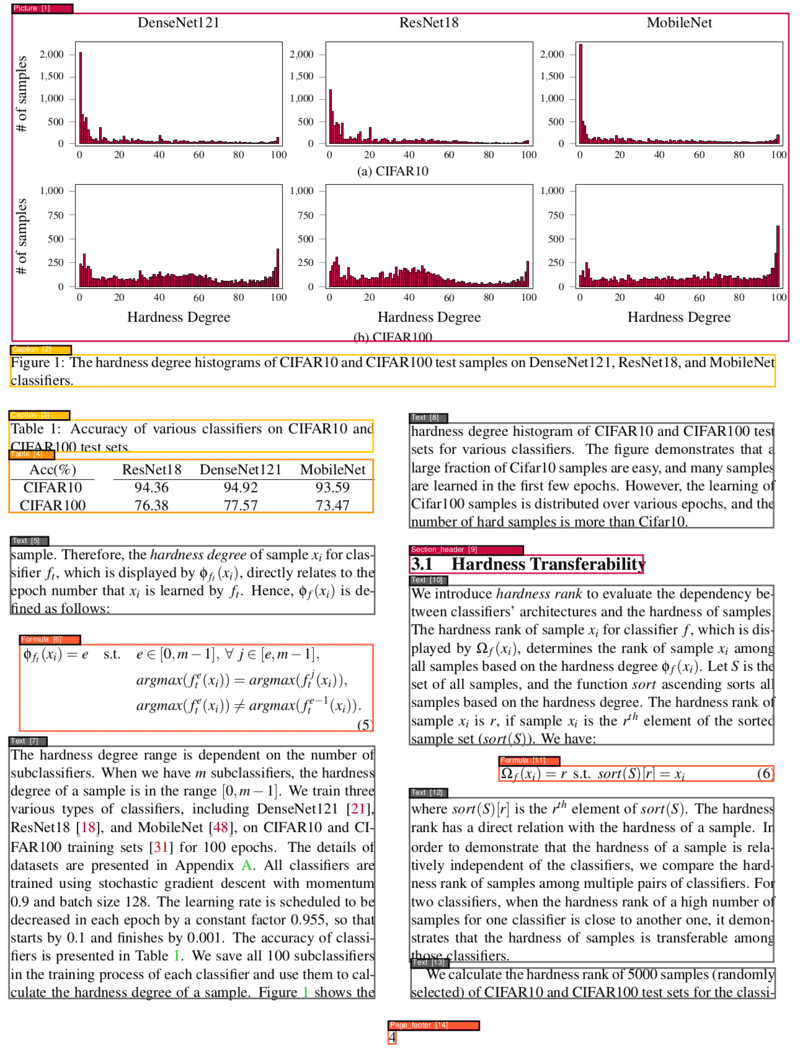
|

|
- GitHub: pdf-document-layout-analysis
- HuggingFace: pdf-document-layout-analysis
- DockerHub: pdf-document-layout-analysis
Run the service:
-
With GPU support:
make start -
Without GPU support:
make start_no_gpu
[OPTIONAL] OCR the PDF. Check supported languages (curl localhost:5060/info):
curl -X POST -F 'language=en' -F 'file=@/PATH/TO/PDF/pdf_name.pdf' localhost:5060/ocr --output ocr_document.pdf
Get the segments from a PDF:
curl -X POST -F 'file=@/PATH/TO/PDF/pdf_name.pdf' localhost:5060
To stop the server:
make stop
- Docker Desktop 4.25.0 install link
- For GPU support install link
- 2 GB RAM memory
- 5 GB GPU memory (if not, it will run on CPU)
There are two kinds of models in the project. The default model is a visual model (specifically called as Vision Grid Transformer - VGT) which has been trained by Alibaba Research Group. If you would like to take a look at their original project, you can visit this link. There are various models published by them and according to our benchmarks the best performing model is the one trained with the DocLayNet dataset. So, this model is the default model in our project, and it uses more resources than the other model which we ourselves trained.
The second kind of model is the LightGBM models. These models are not visual models, they do not "see" the pages, but we are using XML information that we extracted by using Poppler. The reason there are two models existed is, one of these models is predicting the types of the tokens and the other one is trying to find out the correct segmentations in the page. By combining both, we are segmenting the pages alongside with the type of the content.
Even though the visual model using more resources than the others, generally it's giving better performance since it "sees" the whole page and has an idea about all the context. On the other hand, LightGBM models are performing slightly worse but they are much faster and more resource-friendly. It will only require your CPU power.
The service converts PDFs to text-searchable PDFs using Tesseract OCR and ocrmypdf.
As we mentioned, we are using the visual model that trained on DocLayNet dataset. Also for training the LightGBM models, we again used this dataset. There are 11 categories in this dataset:
1: "Caption"
2: "Footnote"
3: "Formula"
4: "List item"
5: "Page footer"
6: "Page header"
7: "Picture"
8: "Section header"
9: "Table"
10: "Text"
11: "Title"
For more information about the data, you can visit the link we shared above.
As we mentioned at the Quick Start, you can use the service simply like this:
curl -X POST -F 'file=@/PATH/TO/PDF/pdf_name.pdf' localhost:5060
This command will run the visual model. So you should be prepared that it will use lots of resources. Also, please note that if you do not have GPU in your system, or if you do not have enough free GPU memory, the visual model will run on CPU. You should be expecting a long response time in that case (See speed benchmark for more details).
If you want to use the non-visual models, which are the LightGBM models, you can use this command:
curl -X POST -F 'file=@/PATH/TO/PDF/pdf_name.pdf' -F "fast=true" localhost:5060
The shape of the response will be the same in both of these commands.
When the process is done, the output will include a list of SegmentBox elements and, every SegmentBox element will has this information:
{
"left": Left position of the segment
"top": Top position of the segment
"width": Width of the segment
"height": Height of the segment
"page_number": Page number which the segment belongs to
"page_width": Width of the page which the segment belongs to
"page_height": Width of the page which the segment belongs to
"text": Text inside the segment
"type": Type of the segment (one of the categories mentioned above)
}
If you want to get the visualizations, you can use this command:
curl -X POST -F 'file=@/PATH/TO/PDF/pdf_name.pdf' localhost:5060/visualize -o '/PATH/TO/OUTPUT_PDF/pdf_name.pdf'
Or with fast models:
curl -X POST -F 'file=@/PATH/TO/PDF/pdf_name.pdf' -F "fast=true" localhost:5060/visualize -o '/PATH/TO/OUTPUT_PDF/pdf_name.pdf'
And to stop the server, you can simply use this:
make stop
When all the processes are done, the service returns a list of SegmentBox elements with some determined order. To figure out this order, we are mostly relying on Poppler. In addition to this, we are also getting help from the types of the segments.
During the PDF to XML conversion, Poppler determines an initial reading order for each token it creates. These tokens are typically lines of text, but it depends on Poppler's heuristics. When we extract a segment, it usually consists of multiple tokens. Therefore, for each segment on the page, we calculate an "average reading order" by averaging the reading orders of the tokens within that segment. We then sort the segments based on this average reading order. However, this process is not solely dependent on Poppler, we also consider the types of segments.
First, we place the "header" segments at the beginning and sort them among themselves. Next, we sort the remaining segments, excluding "footers" and "footnotes," which are positioned at the end of the output.
Occasionally, we encounter segments like pictures that might not contain text. Since Poppler cannot assign a reading order to these non-text segments, we process them after sorting all segments with content. To determine their reading order, we rely on the reading order of the nearest "non-empty" segment, using distance as a criterion.
Our service provides a way to extract your tables and formulas in different formats.
As default, formula segments' "text" property will include the formula in LaTeX format.
You can also extract tables in different formats like "markdown", "latex", or "html" but this is not a default option.
To extract the tables like this, you should set "extraction_format" parameter. Some example usages shown below:
curl -X POST -F 'file=@/PATH/TO/PDF/pdf_name.pdf' localhost:5060 -F "extraction_format=latex"
curl -X POST -F 'file=@/PATH/TO/PDF/pdf_name.pdf' localhost:5060/fast -F "extraction_format=markdown"
You should be aware that this additional extraction process can make the process much longer, especially if you have a large number of tables.
(For table extraction, we are using StructEqTable and for formula extraction, we are using RapidLaTeXOCR)
These are the benchmark results for VGT model on PubLayNet dataset:
| Overall | Text | Title | List | Table | Figure |
|---|---|---|---|---|---|
| 0.962 | 0.950 | 0.939 | 0.968 | 0.981 | 0.971 |
You can check this link to see the comparison with the other models: https://paperswithcode.com/sota/document-layout-analysis-on-publaynet-val
For 15 pages academic paper document:
| Model | GPU | Speed (seconds per page) |
|---|---|---|
| Fast Model | ✗ [i7-8700 3.2GHz] | 0.42 |
| VGT | ✓ [GTX 1070] | 1.75 |
| VGT | ✗ [i7-8700 3.2GHz] | 13.5 |
Here are some of our other services that is built upon this service:
-
PDF Table Of Contents Extractor: This project aims to extract text from PDF files using the outputs generated by the pdf-document-layout-analysis service. By leveraging the segmentation and classification capabilities of the underlying analysis tool, this project automates the process of text extraction from PDF files.
-
PDF Text Extraction: This project aims to extract text from PDF files using the outputs generated by the pdf-document-layout-analysis service. By leveraging the segmentation and classification capabilities of the underlying analysis tool, this project automates the process of text extraction from PDF files.