![]()

![]()
Environments | Installation | Quickstart | Training | Citation | Docs









Jumanji has been accepted at ICLR 2024, check out our research paper.
Jumanji is a diverse suite of scalable reinforcement learning environments written in JAX. It now features 22 environments!
Jumanji is helping pioneer a new wave of hardware-accelerated research and development in the field of RL. Jumanji's high-speed environments enable faster iteration and large-scale experimentation while simultaneously reducing complexity. Originating in the research team at InstaDeep, Jumanji is now developed jointly with the open-source community. To join us in these efforts, reach out, raise issues and read our contribution guidelines or just star 🌟 to stay up to date with the latest developments!
- Provide a simple, well-tested API for JAX-based environments.
- Make research in RL more accessible.
- Facilitate the research on RL for problems in the industry and help close the gap between research and industrial applications.
- Provide environments whose difficulty can be scaled to be arbitrarily hard.
- 🥑 Environment API: core abstractions for JAX-based environments.
- 🕹️ Environment Suite: a collection of RL environments ranging from simple games to NP-hard combinatorial problems.
- 🍬 Wrappers: easily connect to your favourite RL frameworks and libraries such as
Acme,
Stable Baselines3,
RLlib, Gymnasium
and DeepMind-Env through our
dm_envandgymwrappers. - 🎓 Examples: guides to facilitate Jumanji's adoption and highlight the added value of JAX-based environments.
- 🏎️ Training: example agents that can be used as inspiration for the agents one may implement in their research.
Jumanji provides a diverse range of environments ranging from simple games to NP-hard combinatorial problems.
| Environment | Category | Registered Version(s) | Source | Description |
|---|---|---|---|---|
| 🔢 Game2048 | Logic | Game2048-v1 |
code | doc |
| 🎨 GraphColoring | Logic | GraphColoring-v1 |
code | doc |
| 💣 Minesweeper | Logic | Minesweeper-v0 |
code | doc |
| 🎲 RubiksCube | Logic | RubiksCube-v0RubiksCube-partly-scrambled-v0 |
code | doc |
| 🔀 SlidingTilePuzzle | Logic | SlidingTilePuzzle-v0 |
code | doc |
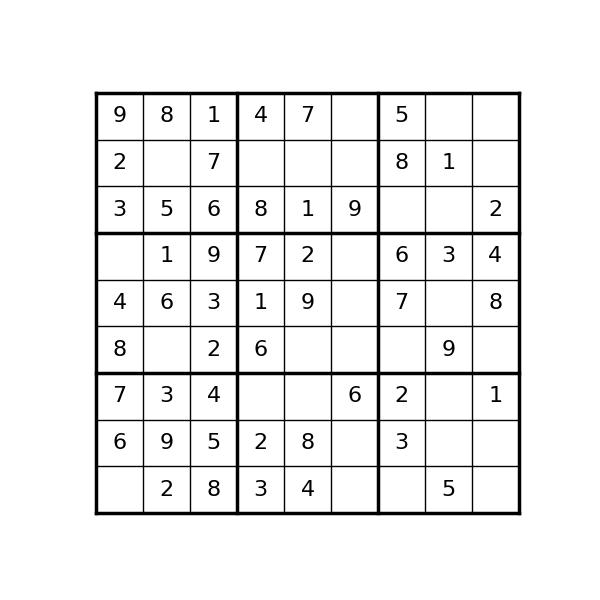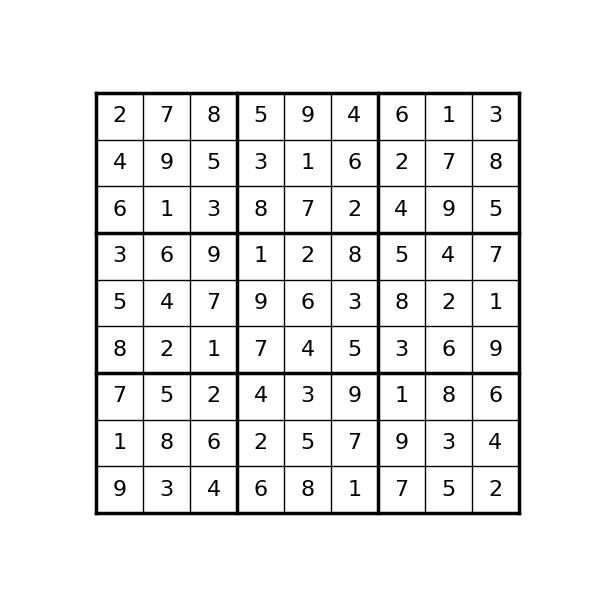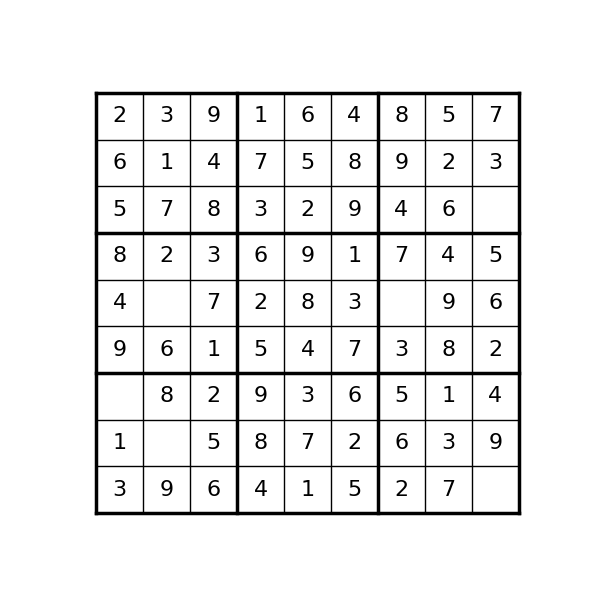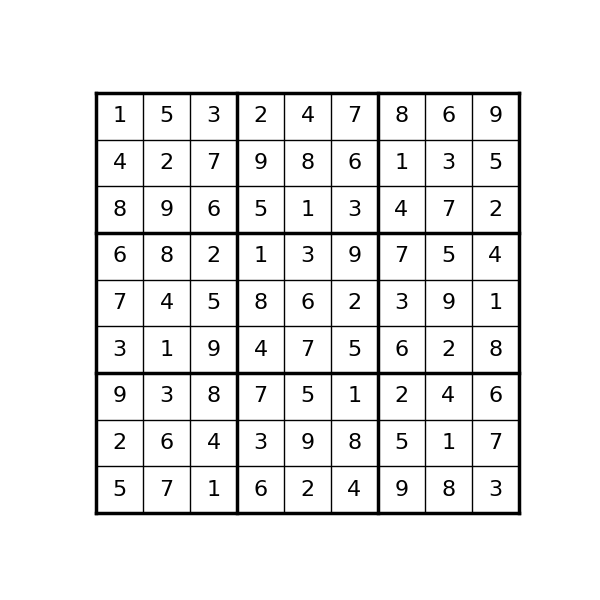
| ✏️ Sudoku | Logic | Sudoku-v0 Sudoku-very-easy-v0 |
code | doc |
| 📦 BinPack (3D BinPacking Problem) | Packing | BinPack-v1 |
code | doc |
| 🧩 FlatPack (2D Grid Filling Problem) | Packing | FlatPack-v0 |
code | doc |
| 🏭 JobShop (Job Shop Scheduling Problem) | Packing | JobShop-v0 |
code | doc |
| 🎒 Knapsack | Packing | Knapsack-v1 |
code | doc |
| ▒ Tetris | Packing | Tetris-v0 |
code | doc |
| 🧹 Cleaner | Routing | Cleaner-v0 |
code | doc |
| 🔗 Connector | Routing | Connector-v2 |
code | doc |
| 🚚 CVRP (Capacitated Vehicle Routing Problem) | Routing | CVRP-v1 |
code | doc |
| 🚚 MultiCVRP (Multi-Agent Capacitated Vehicle Routing Problem) | Routing | MultiCVRP-v0 |
code | doc |
| 🔍 Maze | Routing | Maze-v0 |
code | doc |
| 🤖 RobotWarehouse | Routing | RobotWarehouse-v0 |
code | doc |
| 🐍 Snake | Routing | Snake-v1 |
code | doc |
| 📬 TSP (Travelling Salesman Problem) | Routing | TSP-v1 |
code | doc |
| Multi Minimum Spanning Tree Problem | Routing | MMST-v0 |
code | doc |
| ᗧ•••ᗣ•• PacMan | Routing | PacMan-v1 |
code | doc |
| 👾 Sokoban | Routing | Sokoban-v0 |
code | doc |
| 🍎 Level-Based Foraging | Routing | LevelBasedForaging-v0 |
code | doc |
| 🚁 Search and Rescue | Swarms | SearchAndRescue-v0 |
code | doc |
You can install the latest release of Jumanji from PyPI:
pip install -U jumanjiAlternatively, you can install the latest development version directly from GitHub:
pip install git+https://github.com/instadeepai/jumanji.gitJumanji has been tested on Python 3.10, 3.11 and 3.12. Note that because the installation of JAX differs depending on your hardware accelerator, we advise users to explicitly install the correct JAX version (see the official installation guide).
Rendering: Matplotlib is used for rendering all the environments. To visualize the environments
you will need a GUI backend. For example, on Linux, you can install Tk via:
apt-get install python3-tk, or using conda: conda install tk. Check out
Matplotlib backends for a list of
backends you can use.
RL practitioners will find Jumanji's interface familiar as it combines the widely adopted
OpenAI Gym and
DeepMind Environment interfaces. From OpenAI Gym, we adopted
the idea of a registry and the render method, while our TimeStep structure is inspired by
DeepMind Environment.
import jax
import jumanji
# Instantiate a Jumanji environment using the registry
env = jumanji.make('Snake-v1')
# Reset your (jit-able) environment
key = jax.random.PRNGKey(0)
state, timestep = jax.jit(env.reset)(key)
# (Optional) Render the env state
env.render(state)
# Interact with the (jit-able) environment
action = env.action_spec.generate_value() # Action selection (dummy value here)
state, timestep = jax.jit(env.step)(state, action) # Take a step and observe the next state and time stepstaterepresents the internal state of the environment: it contains all the information required to take a step when executing an action. This should not be confused with theobservationcontained in thetimestep, which is the information perceived by the agent.timestepis a dataclass containingstep_type,reward,discount,observationandextras. This structure is similar todm_env.TimeStepexcept for theextrasfield that was added to allow users to log environments metrics that are neither part of the agent's observation nor part of the environment's internal state.
Being written in JAX, Jumanji's environments benefit from many of its features including
automatic vectorization/parallelization (jax.vmap, jax.pmap) and JIT-compilation (jax.jit),
which can be composed arbitrarily.
We provide an example of a more advanced usage in the
advanced usage guide.
Like OpenAI Gym, Jumanji keeps a strict versioning of its environments for reproducibility reasons.
We maintain a registry of standard environments with their configuration.
For each environment, a version suffix is appended, e.g. Snake-v1.
When changes are made to environments that might impact learning results,
the version number is incremented by one to prevent potential confusion.
For a full list of registered versions of each environment, check out
the documentation.
To showcase how to train RL agents on Jumanji environments, we provide a random agent and a vanilla actor-critic (A2C) agent. These agents can be found in jumanji/training/.
Because the environment framework in Jumanji is so flexible, it allows pretty much any problem to be implemented as a Jumanji environment, giving rise to very diverse observations. For this reason, environment-specific networks are required to capture the symmetries of each environment. Alongside the A2C agent implementation, we provide examples of such environment-specific actor-critic networks in jumanji/training/networks.
⚠️ The example agents injumanji/trainingare only meant to serve as inspiration for how one can implement an agent. Jumanji is first and foremost a library of environments - as such, the agents and networks will not be maintained to a production standard.
For more information on how to use the example agents, see the training guide.
Contributions are welcome! See our issue tracker for good first issues. Please read our contributing guidelines for details on how to submit pull requests, our Contributor License Agreement, and community guidelines.
If you use Jumanji in your work, please cite the library using:
@misc{bonnet2024jumanji,
title={Jumanji: a Diverse Suite of Scalable Reinforcement Learning Environments in JAX},
author={Clément Bonnet and Daniel Luo and Donal Byrne and Shikha Surana and Sasha Abramowitz and Paul Duckworth and Vincent Coyette and Laurence I. Midgley and Elshadai Tegegn and Tristan Kalloniatis and Omayma Mahjoub and Matthew Macfarlane and Andries P. Smit and Nathan Grinsztajn and Raphael Boige and Cemlyn N. Waters and Mohamed A. Mimouni and Ulrich A. Mbou Sob and Ruan de Kock and Siddarth Singh and Daniel Furelos-Blanco and Victor Le and Arnu Pretorius and Alexandre Laterre},
year={2024},
eprint={2306.09884},
url={https://arxiv.org/abs/2306.09884},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
Other works have embraced the approach of writing RL environments in JAX. In particular, we suggest users check out the following sister repositories:
- 🤖 Qdax is a library to accelerate Quality-Diversity and neuro-evolution algorithms through hardware accelerators and parallelization.
- 🌳 Evojax provides tools to enable neuroevolution algorithms to work with neural networks running across multiple TPU/GPUs.
- 🦾 Brax is a differentiable physics engine that simulates environments made up of rigid bodies, joints, and actuators.
- 🏋️ Gymnax implements classic environments including classic control, bsuite, MinAtar and a collection of meta RL tasks.
- 🎲 Pgx provides classic board game environments like Backgammon, Shogi, and Go.
The development of this library was supported with Cloud TPUs from Google's TPU Research Cloud (TRC) 🌤.