- 從基礎重新訓練自己,填補不足、穩固基底。
-
第十六天為總整理,對於檢查
資料型態與尋找遺失值的方法更為了解。除了練習python語法外,最重要的還是了解資料想解決的問題及相關領域背景,如何用有限的資料發揮最大效益。 -
EDA(Exploratory Data Analysis)探索式資料分析與敘述統計做差不多的事,只是換了更炫砲的名字。
KDE(Kernel Density Estimation)以無母數方法看樣本密度函數。
完全不會特徵工程,花了更多時間在閱讀相關資料。
寫太多開另一個Markdown:Note
Loss Function
-
回歸:
- MSE(Mean Square Error)
- MAE(Mean Absolute Error)
-
$R^2$ (R-square) - MAPE(Mean Absolute Percentage Error)
分類:
-
AUC(Area Under Curve):線越左上越好;機率值
-
F1-Score(Precision, Recall):希望某類不要分錯;分類結果
True Positive, False Positive, True Negative, False Negative
T / F:模型預測對錯, P / N:模型預測結果
Precision:模型判定瑕疵,樣本確實為瑕疵的比例
Recall:模型判定的瑕疵,佔樣本所有瑕疵的比例(以瑕疵檢測為例,若為 recall=1 則代表所有瑕疵都被找到) $$ F_{\beta} = (1+\beta^2)\frac{precisionrecall}{(\beta^2+precision)+recall} $$
-
混淆矩陣(Confusion Matrix)
-
top-k accuracy:用於多分類問題
-
訓練樣本及測試樣本
Bias vs Variance
-Bias大,重新建模,因為未包含目標(加變數或升次方)
-Variance大,增加資料筆數或正規化(Regularization)

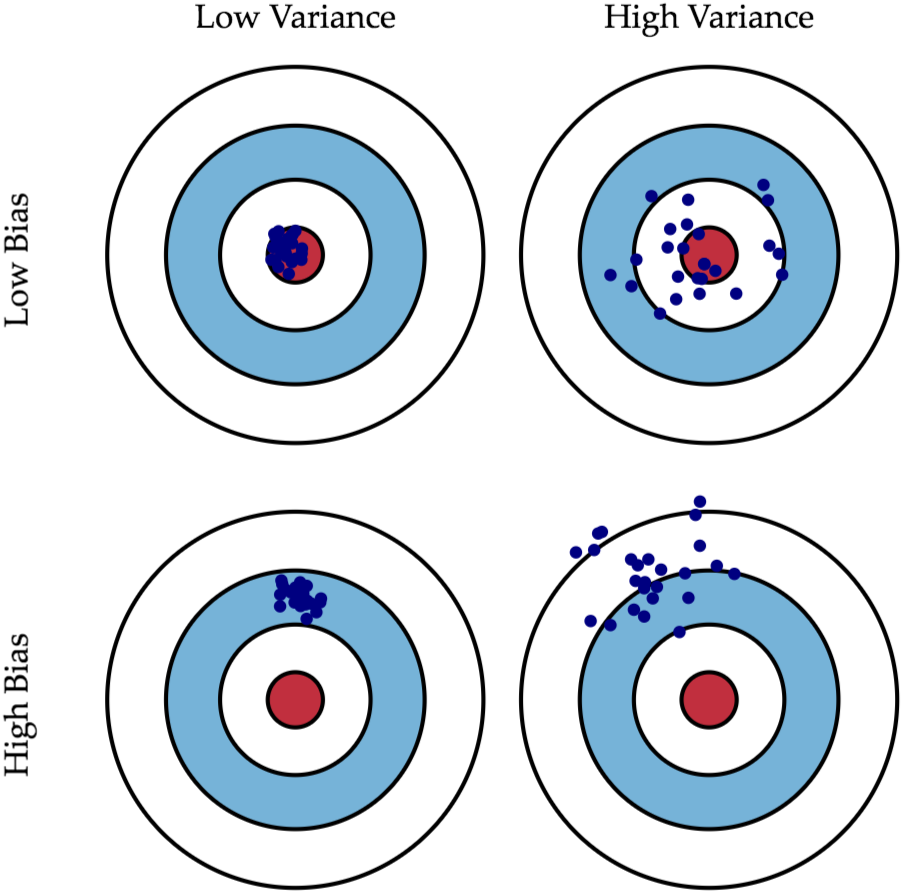
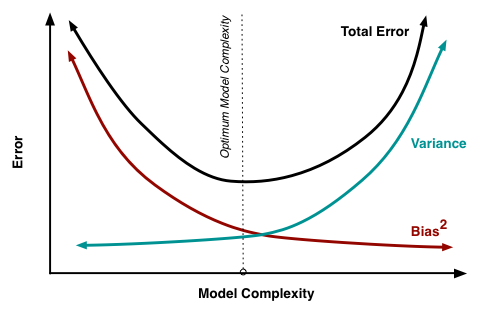

先將訓練資料集分成訓練資料及交叉驗證資料,選出損失函數較低的模型,再用完整訓練資料集重新訓練模型,再使用測試資料集評估模型效益。