This repository is ImageNet Classification with Deep Convolutional Neural Networks Pytorch third-party implementation of AlexNet.
PDF: https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
NIPS Open Proceedings: https://papers.nips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
The original implementation of Alex Krizhevsky is not open sources, but many other third-party implementation is available, including Pytorch official implementation: https://pytorch.org/hub/pytorch_vision_alexnet/
Notes:
-
Compared to architecture detailed in the paper, Pytorch implementation makes modifications, including: removing
Local Response Normalization, changing input/output channel of convolutional layer, and etc.. For better re-implement the paper, I write AlexNet of both paper version and Pytorch Version. -
I trained AlexNet on
Cifar10,Cifar100, andPascalVOC2012. Due to the computation limitation, I didn't train on larger datasets likeImageNet. -
Since images in
Cifar10andCifa100are pretty tiny (32 * 32 * 3), using 11 * 11 kernel in the first convolutional layer will simply crash the network. There're two ways to address the problem:- Modify the first layer kernel size
- Resize the image from 32 to 224 before put into the network
I have tested both, and find the first way runs fast and achieves higher accuracy. So, I also write a
CifarAlexNetwhich shifts the kernel size of the first convolution layers. -
Training
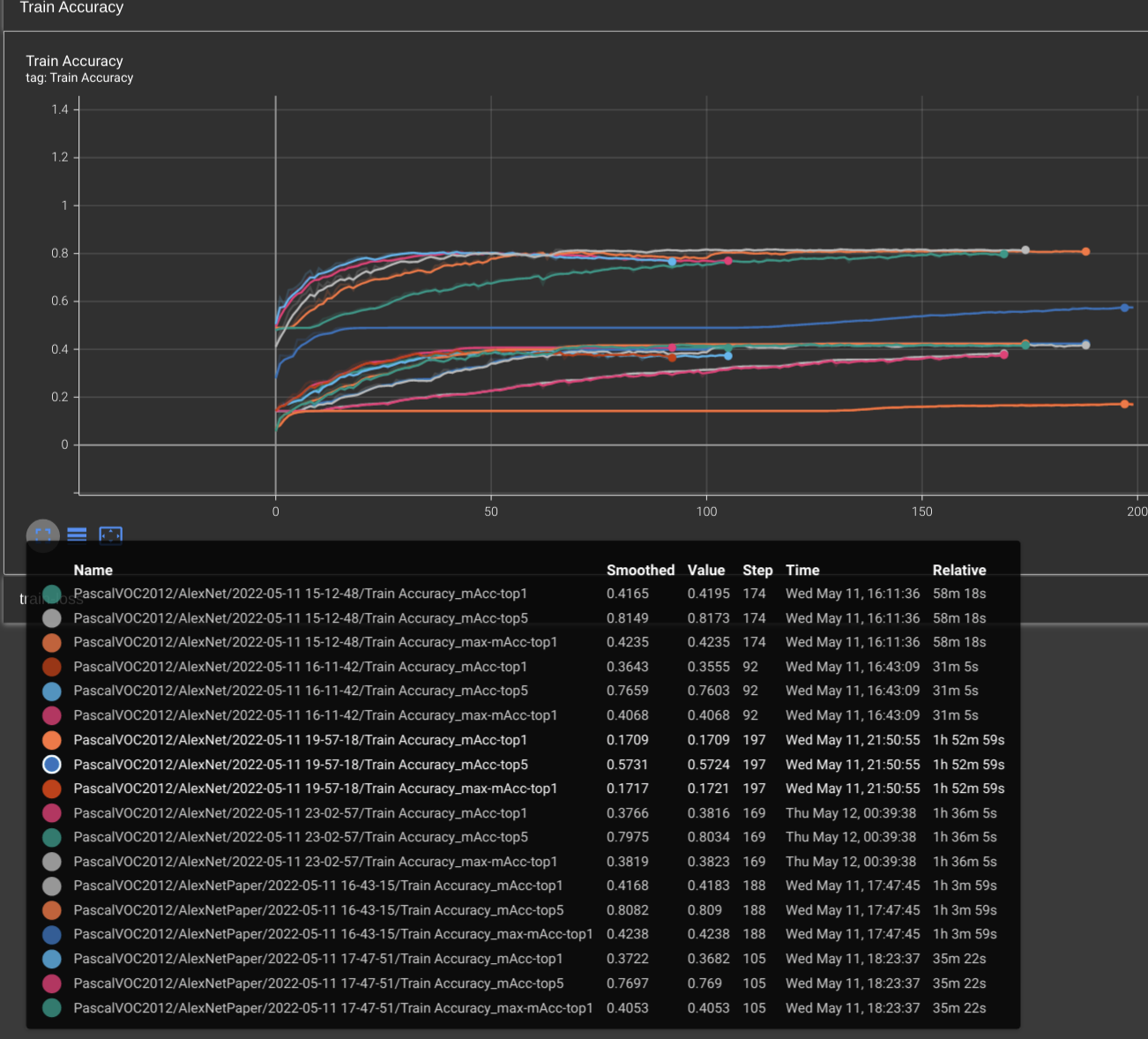
PascalVOC2012takes too much time since my poor GPU cannot support. I roughly run thePascalVOC2012about 100~200 epochs, and finding the accuracy can be further promoted to meet the result claimed in the paper. -
Current version is V2 where I basically rewrite all the code, so, you can only pull the v2 branch and run the codes.
-
Since checkpoints are too large, I will not upload the results
- Using higher learning rate at start and decease the learning rate during the training when the accuracy meets plateau is helpful. In my experiments, compared with training with Adam/SGD as normal, I find setting large learning rate at beginning do helps speed up training every times. It may start with a much lower accuracy, but quickly meets with normal Adam/SGD. However, not every time the final maximum accuracy is higher than normal setup.
- For
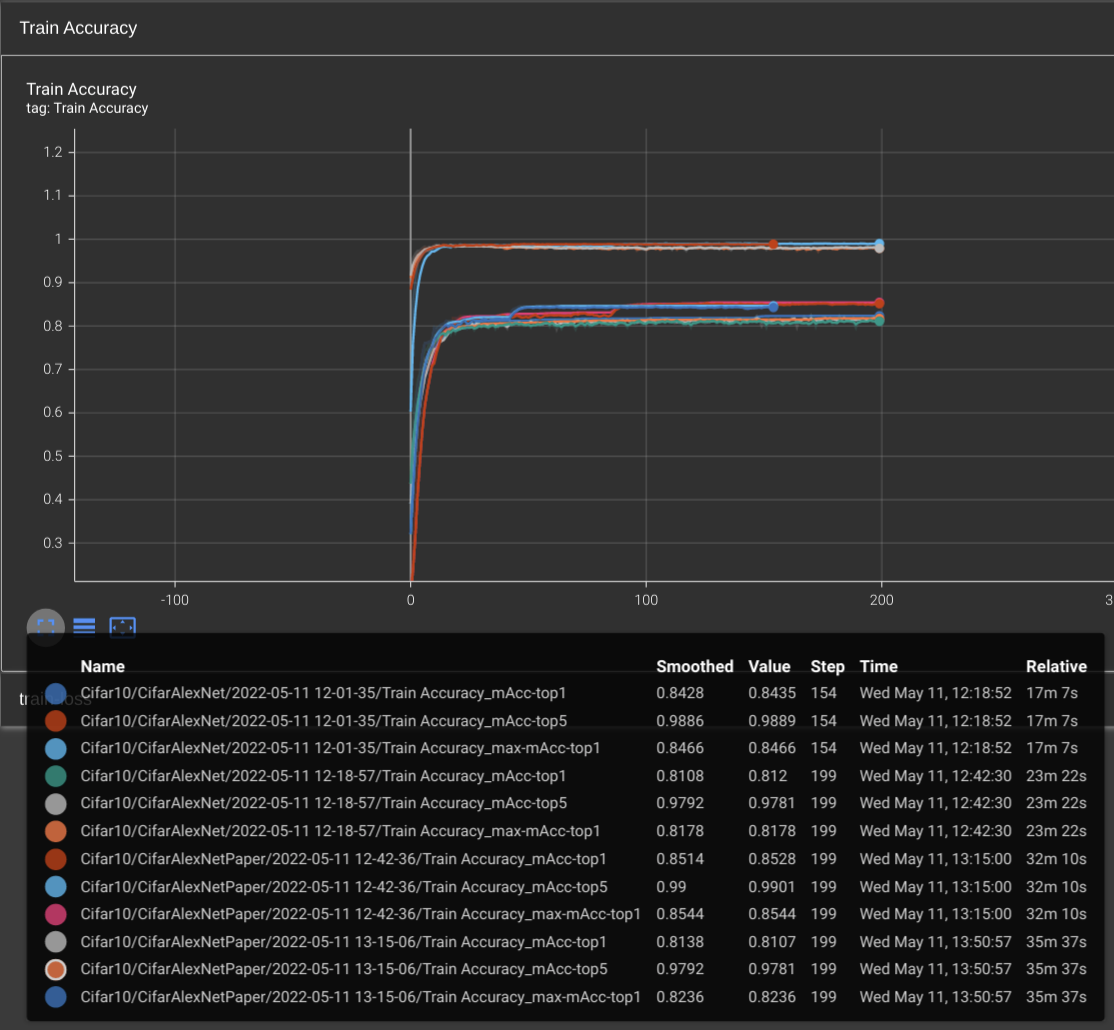
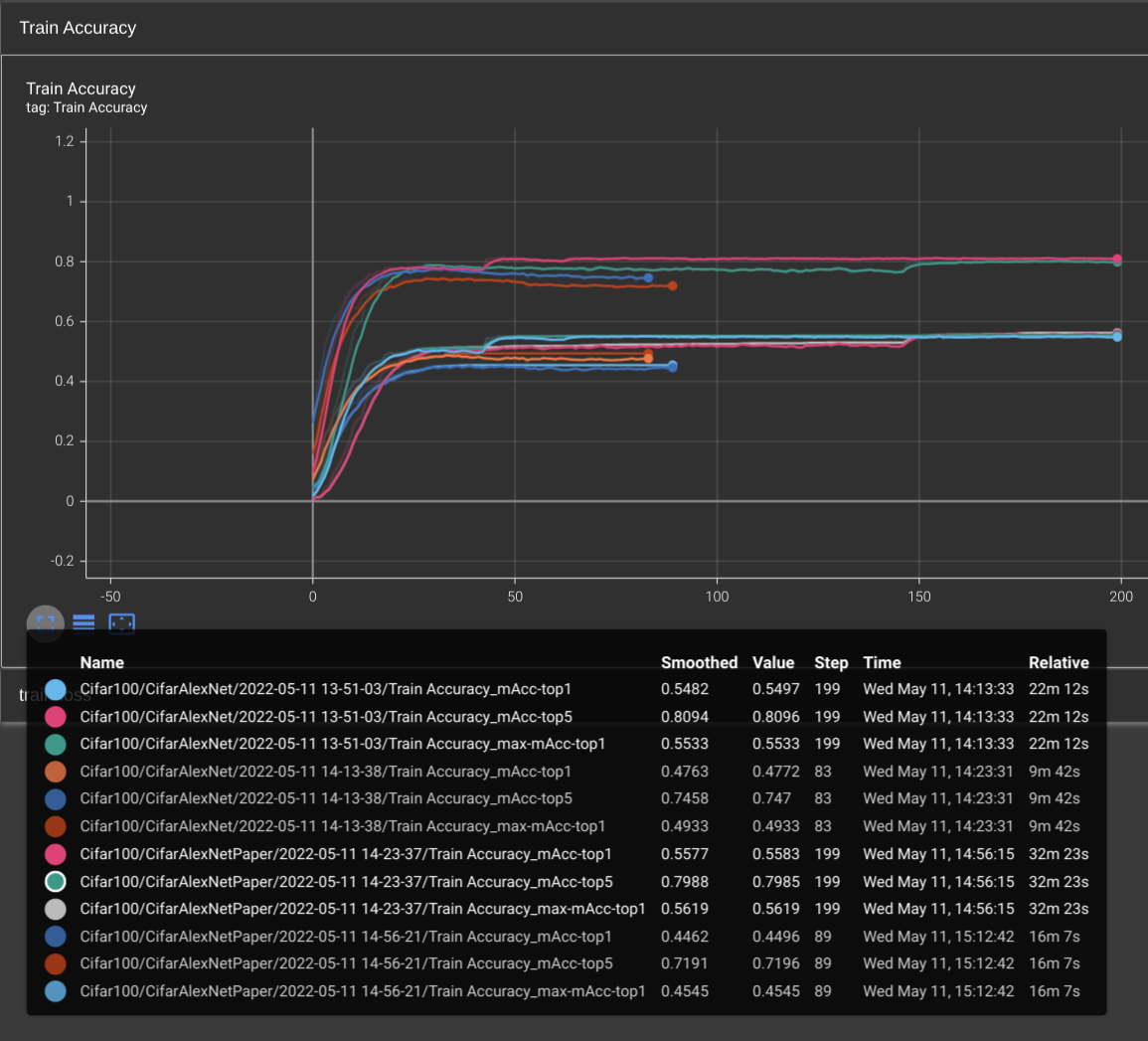
Cifar10andCifar100, shift the kernel of the first convolutional layer is much better than resize the image from 32 * 32 to 224 * 224. It runs faster and achieve more accuracy. It not hard to understand the speed acceleration. But for the accuracy improvement, I guess duplicating the pixels may cause the model learns useless patterns, which means noise is introduced when upsampling. Local Response Normalizeis useless. Without the LRN, the model can achieve higher accuracy.PascalVOC2012is harder thanCifar100andCifar10. AndCifar100is harder thanCifar10. Since training with same epoch, Pascal's accuracy is lower than Cifar100's and Cifar10's. I guess this may because down-sampling process ofCifar10andCifar100lost many detail pattern while keep the main pattern that is critical for classification. I didn't test the hypothesis with downscaling PascalVOC2012's images.- Large learning rate is especially helpful when training on
largedatasets likePascalVOC2012.
-
Prepare the data
To prepare the data, make soft link or directly put your data in the
datasetfoldercd ~/projects/AlexNet mkdir dataset cd dataset # make soft link to the dataset or directly put your dataset in the folder ln -s /media/jack/JackCode1/dataset/cifar-10/cifar-10-batches-py/ cifar-100 ln -s /media/jack/JackCode1/dataset/cifar-100/cifar-100-python/ cifar-100 ln -s /media/jack/JackCode1/dataset/pascalvoc2012/VOCdevkit/VOC2012/ PascalVOC2012
Notes: the name of the datasets must be
cifar-10,cifar-100,PascalVOC2012After this, the directory should be like
tree dataset -L 2 -l
dataset ├── cifar-10 -> /media/jack/JackCode1/dataset/cifar-10/cifar-10-batches-py/ │ ├── batches.meta │ ├── data_batch_1 │ ├── data_batch_2 │ ├── data_batch_3 │ ├── data_batch_4 │ ├── data_batch_5 │ ├── readme.html │ └── test_batch ├── cifar-100 -> /media/jack/JackCode1/dataset/cifar-100/cifar-100-python/ │ ├── cifar-100-python │ ├── cifar-100-python.tar.gz │ ├── file.txt~ │ ├── meta │ ├── test │ └── train └── PascalVOC2012 -> /media/jack/JackCode1/dataset/pascalvoc2012/VOCdevkit/VOC2012/ ├── Annotations ├── ImageSets ├── JPEGImages ├── SegmentationClass └── SegmentationObject 9 directories, 13 files
-
run
main.pywith command line argumentsFirst, you can view all argument by offering
-h/--helpoptionpython main.py -h
and you will see
usage: main.py [-h] [-v] [-d] [-l] [-c] [-pt] [-pm] [-ne N_EPOCH] [-es EARLY_STOP] [-lls LOG_LOSS_STEP] [-lce LOG_CONFUSION_EPOCH] [-ds DATASET] [-m MESSAGE] AlexNet Pytorch Implementation training util by Shihong Wang ([email protected]) optional arguments: -h, --help show this help message and exit -v, --version show program's version number and exit -d, --dry_run If run without saving tensorboard amd network params to runs and checkpoints -l, --log If save terminal output to log -c, --cifar If use cifar modified network -pt, --paper_train If train the network using paper setting -pm, --paper_model If train the network exactly the same in paper -ne N_EPOCH, --n_epoch N_EPOCH Set maximum training epoch of each task -es EARLY_STOP, --early_stop EARLY_STOP Set maximum early stop epoch counts -lls LOG_LOSS_STEP, --log_loss_step LOG_LOSS_STEP Set log loss steps -lce LOG_CONFUSION_EPOCH, --log_confusion_epoch LOG_CONFUSION_EPOCH Set log confusion matrix epochs -ds DATASET, --dataset DATASET Set training datasets -m MESSAGE, --message MESSAGE Training digestNotes: currently, I didn't find a good solution to print long column tables in terminal which may also crash the log file, so the
-lceoption is currently aborted.Following are some training examples.
python main.py -l -c -ds "Cifar10" -m "Train cifar modified model on Cifar10 datasets with mordern setups (e.g., Adam optimizer, early stop, etc.), save training curves and log terminal output" python main.py -l -d -c -ds "Cifar100" -m "Same as the former one, but train with Cifar100 and log results only (will not save checkpoints and training curves)" python main.py -d -ds "PascalVOC2012" -pm -pt "Exactly same model and training setup in paper (with LRN, learning rate decay, SGD optimizer...)"
-
check the results in
logandrunsfoldercheck
logsfor terminal outputs.run following command to see training curves
tensorboard --logdir runs
You can check with previous commands, here I just put basic information of my training results without in-depth analysis. All training setups are in log
Helpful regular expressions are:
- check results of top
kresults on different datasets:PascalVOC2012\/.*\/.*topk - check results of max top 1 results of datasets:
Cifar10\/.*\/.*max
Results on Cifar10
Results on Cifar100
Results on PascalVOC2012