{kind=link}
The orchestration portion of this project was done in azure data factory and azure monitor. A set of json files were used to show the configuration of the pieces of the projects orchestration. Azure Monitor logging, Data Factory pipelines, and Data Factory linked services all have their own sets of json files.
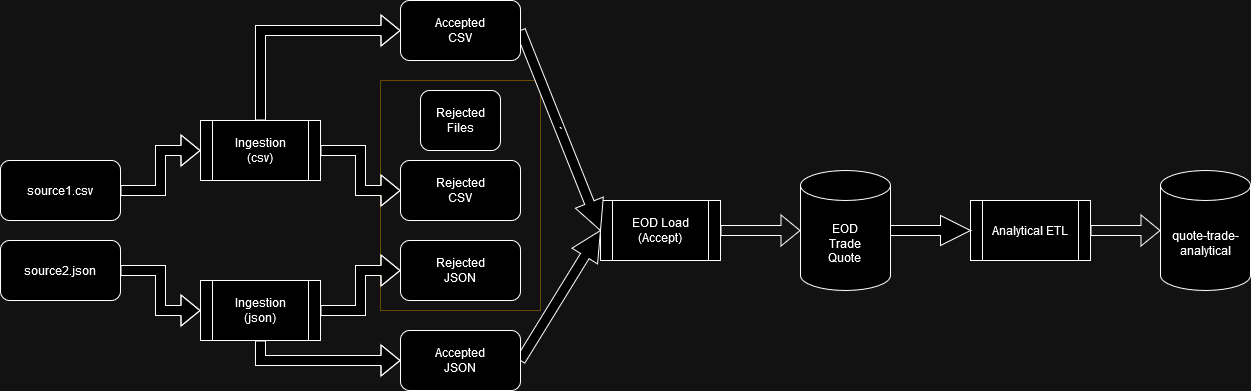
Data loading is shown in a python notebook. Here any corrections to trade and quote data was accepted, and previous versions of the record discarded. Data was written back to the storage account partitioned by trade_dt
The data ingestion process is shown as a python notebook. This notebook was exported from a Azure Databricks notebook where the data parsing was done.
The analytical etl process was done using an azure databricks notebook and is present as Analytical ETL.dbc & Analytical ETL.ipynb