Motion, measured via optical flow, provides a powerful cue to discover and learn objects in images and videos. However, compared to using appearance, it has some blind spots, such as the fact that objects become invisible if they do not move. In this work, we propose an approach that combines the strengths of motion-based and appearance-based segmentation. We propose to supervise an image segmentation network with the pretext task of predicting regions that are likely to contain simple motion patterns, and thus likely to correspond to objects. As the model only uses a single image as input, we can apply it in two settings: unsupervised video segmentation, and unsupervised image segmentation. We achieve state-of-the-art results for videos, and demonstrate the viability of our approach on still images containing novel objects. Additionally we experiment with different motion models and optical flow backbones and find the method to be robust to these change.
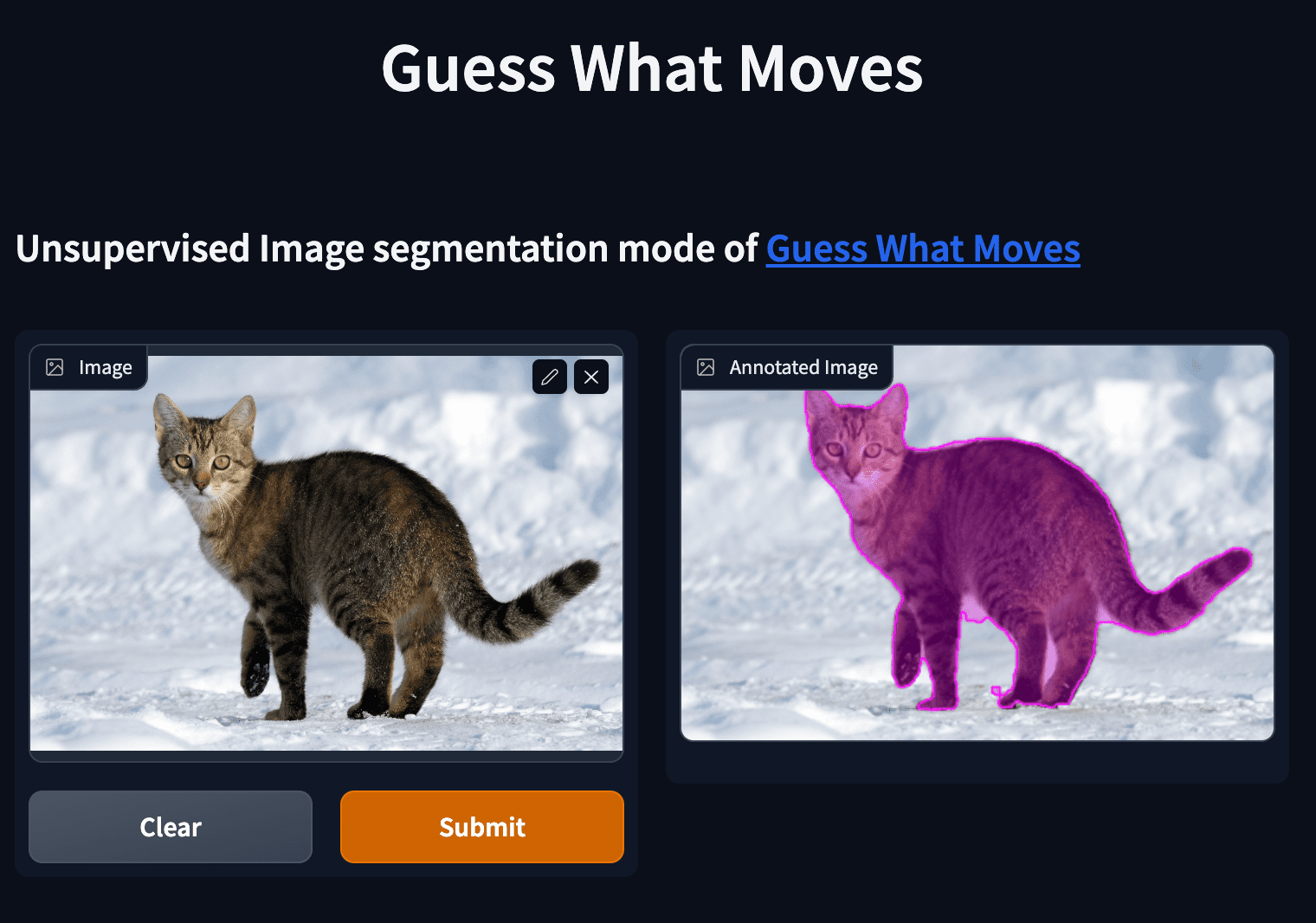
Try out the web demo at
Create and name a conda environment of your choosing, e.g. gwm:
conda create -n gwm python=3.8
conda activate gwmthen install the requirements using this one liner:
conda install -y pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch && \
conda install -y kornia jupyter tensorboard timm einops scikit-learn scikit-image openexr-python tqdm gcc_linux-64=11 gxx_linux-64=11 fontconfig -c conda-forge && \
yes | pip install cvbase opencv-python wandb && \
yes | python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'Datasets should be placed under data/<dataset_name>, e.g. data/DAVIS2016.
- For video segmentation we follow the dataset preparation steps of MotionGrouping.
- For image segmentation we follow the dataset preparation steps of unsupervised-image-segmentation.
Experiments are controlled through a mix of config files and command line arguments. See config files and src/config.py for a list of all available options.
python main.py GWM.DATASET DAVIS LOG_ID davis
python main.py GWM.DATASET FBMS LOG_ID fbms
python main.py GWM.DATASET STv2 LOG_ID stv2Run the above commands in src folder.
Evaluation scripts are provided as eval-vid_segmentation.ipynb and eval-img_segmentation.ipynb notebooks.
See checkpoints folder for available checkpoints.
This repository builds on MaskFormer, MotionGrouping, unsupervised-image-segmentation, and dino-vit-features.
@inproceedings{choudhury+karazija22gwm,
author = {Choudhury, Subhabrata and Karazija, Laurynas and Laina, Iro and Vedaldi, Andrea and Rupprecht, Christian},
booktitle = {British Machine Vision Conference (BMVC)},
title = {{G}uess {W}hat {M}oves: {U}nsupervised {V}ideo and {I}mage {S}egmentation by {A}nticipating {M}otion},
year = {2022},
}