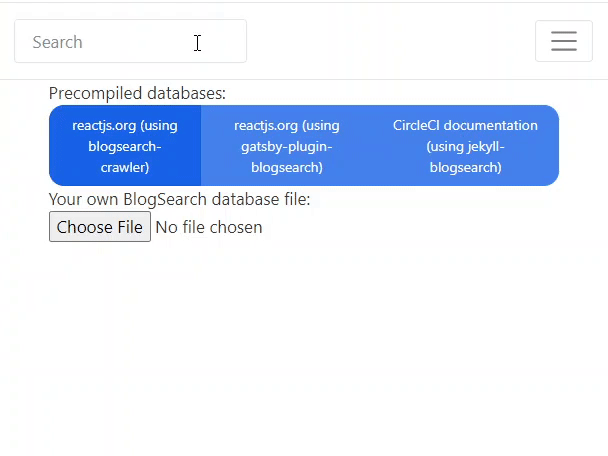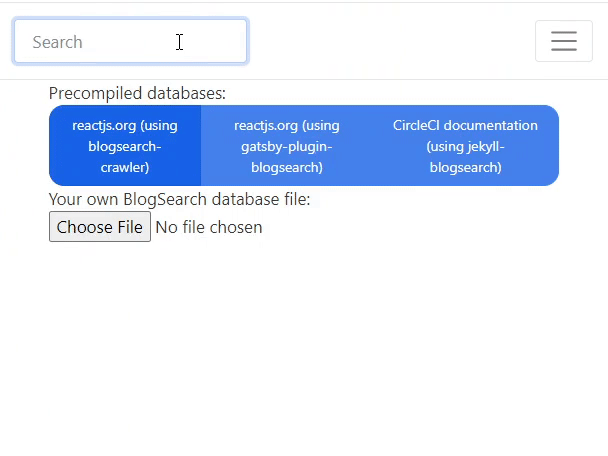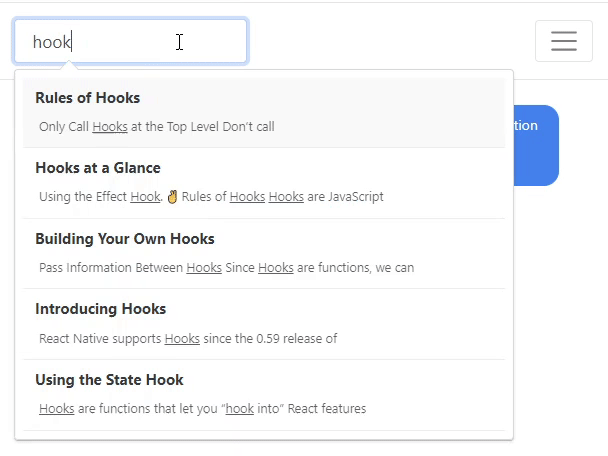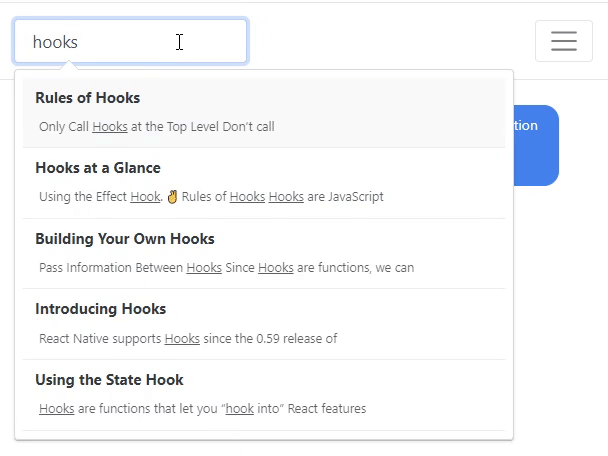
BlogSearch is a blogging tool that enables a search engine without any external services.
This is like DocSearch but for blogs.
More technically, BlogSearch is a pure client-side, full-text search engine for static websites, powered by SQLite compiled to WebAssembly.
-
Purely client-side search
-
No server to maintain. No service cost.
-
Easy. It’s built for blogs and static websites in mind.
-
Supports popular blog frameworks:
-
sqlite-wasm: Run SQLite on the web, using WebAssembly. This project is made for blogsearch’s needs.
The workflow is consist of two steps: 1. You build an index file |
|
1. Build an index file |
2. Enable the search |
The index file
Then you copy the generated |
Your webpage should load the blogsearch engine. There is only one engine available:
Load the engine using <script> tag or in JavaScript file.
Once the engine fetch the |
|
ℹ️
|
Throughout the project, the terms "index" and "database" are often mixed, but they mean same SQLite .db.wasm file in the most of the case.
|
-
Jekyll (jekyll-blogsearch)
-
Gatsby (gatsby-plugin-blogsearch)
-
Hugo (blogsearch-crawler)
-
Generic crawler (blogsearch-crawler)
Users should configure an index building tool to collect the value of fields in order to work the search engine properly.
The index building tool should collect the following default fields for each posts:
- fields
-
-
title: The title of the post. -
body: The content of the post. -
url: The URL link to the post. -
categories: A comma-separated (,) list of categories that the post belongs to. -
tags: A comma-separated (,) list of tags that the post has.
-
Users can configure every fields using the following properties:
| Example | Result |
|---|---|
|
|
{
...other field options...
categories: {
+ disabled: true,
},
} |
|
In the following example, the size of the index file |
|
{
...other field options...
body: {
+ hasContent: false,
},
} |
|
|
|
{
...other field options...
url: {
+ indexed: false,
},
} |
|
|
ℹ️
|
Your index building tool may has tool-specific options for the field (e.g. parser option for blogsearch-crawler). See the documentation of your index building tool for details.
|
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/[email protected]/dist/basic.css" />
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/blogsearch.umd.js"></script>
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/worker.umd.js"></script>
<input id="blogsearch_input_element" type="search" placeholder="Search Text" class="form-control" />
<script>
blogsearch({
dbPath: 'your_index_file.db.wasm',
inputSelector: '#blogsearch_input_element',
});
</script>For the further details and options, go to the subdirectory of blogsearch.
The search engine basically is SQLite with the FTS5 extension, compiled to WebAssembly. The SQLite FTS5 offers the built-in BM25 ranking algorithm for the search functionality. As SQLite is the most portable database engine, you can open any SQLite database files on the web too! Thanks to SQLite, we can easily write plugins for BlogSearch with just a few SQL queries in different programming languages.
Why .db.wasm is recommended file extension index? It’s not a WebAssembly binary file. Why not just .db?
I tried to make it .db but there is a big problem: the index file is not
gzip-compressed by the web server.
Popular blog web services (especially GitHub Pages) usually serve a .db file as
application/octet-stream and do not compress the file. By lying that it is
a WebAssembly binary file .wasm, the servers recognize it as application/wasm and ship it compressed.
Compression is important because it significantly reduces the file size. I saw the size is reduced up to 1/3.
To avoid “But it works on my machine” problem, it is strongly recommended to use Docker for building tasks.
Although this repository is a monorepo where each subprojects has own build scripts, you can easily run tasks in the root directory.
|
💡
|
If you want to build a specific subproject only, go to the subdirectory and run yarn commands. |
The required tools are the following:
-
GNU Make (v4.2 or higher is recommended, be warned for macOS users!)
-
docker
-
docker-compose
-
yarn
Although it is a JS project Makefile is used because it is much more configuratble and supports building in parallel.
For specific NodeJS versions used in the project, please look at the Dockerfile.
# Or make test, without docker
make test-in-docker
# Run it in parallel
make test-in-docker -j4 --output-sync=target|
|
This will take a lot of time! (~30 mintues) |
# It is highly recommended to use docker here
make examples-in-docker && make demo-in-docker|
|
This will take a lot of time! (~30 mintues) |
# Or make all, without docker
make all-in-docker
# Or
# Parallel builds. This reduces the build time almost an half on my machine.
make all-in-docker -j4 --output-sync=target