The 5G Mobile Network standard is built from the ground up to be cloud-native. Over the years, and thanks to new standards, not only the legacy architectures have been decoupled (CUPS), but even more flexible initiatives (O-RAN) are now taking over the market.
Many Telcos are moving to containerized architectures and ditching for good the legacy, which historically is built on layers of proprietary and specialized solutions.
During the past decade, many Telcos have looked at OpenStack for their 4G Virtualized Network Functions needs as the solution for the NFVi. While many succeeding and also some failing, OpenStack was never truly build to orchestrate containers. Put that together with the community's current status, you'll get that 5G represents an opportunity to do things differently and hopefully better.
The 5G standard allows decoupling the various components into literally thousands of micro-services to embrace a containerized architecture. The following diagram represents the mobile network (2G, 3G, 4G, 5G ) (available on NetX, IMO best independente source to learn the 3GPP mobile standards)
Even considering only 5G, orchestrating these massive applications without something like Kubernetes would be impossible.
- OpenShift 5G Telco Lab
- 1 - Introduction
- 2 - 5G is Containers
- 3 - About this document
- 4 - Lab High-Level
- 5 - vSphere Architecture
- 6 - Red Hat OpenShift Architecture
- 7 - Deployment
- 7.1 - RootCA, Router, NFS Server and Provisioner VMs
- 7.2 - Router
- 7.3 - NFS Server
- 7.4 - Provisioner
- 7.5 - OpenShift deployment
- 7.6 - Adding Physical OpenShift Nodes
- 7.7 - Verify Jumbo Frame
- 7.8 - NFS Storage Class and OCP internal Registry
- 7.9 - Service Type LoadBalancer
- 7.10 - Basic HelloWorld
- 7.11 - PAO
- 7.12 - Kernel Modules
- 7.13 - NMState
- 7.14 - SR-IOV
From Ericsson to Nokia, from Red Hat to VMware, and with leading examples like Verizon and Rakuten, there is absolutely no douth that 5G means containers, and as everybody knows, containers mean Kubernetes. There are many debates whether the more significant chunk of the final architecture would be virtualized or natively running on bare-metal (there are still some cases where hardware virtualization is a fundamental need) but, in all instances, Kubernetes is the dominant and de-facto standard to build applications.
Operating in a containerized cloud-native world represents such a significant shift for all Telco operators that the NFVi LEGO approach seems easy now.
For those who have any doubts about the capability of Kubernetes to run an entire mobile network, I encourage you to watch:
To answer this question, you need to keep in mind the target workloads: Cloud-native Network Function (CNF) such as UPF for 5G Core and vDU in RAN. Red Hat has a great whitepaper talking about all the details, especially how performance is negatively affected by a hardware virtualization layer. Yet other examples from Red Hat in the Radio context. But if Red Hat is not enough, well, let's look at Ericsson talking about the advantages of cloud-native on bare-metal.
The primary aim for this document is deploying a 5G Telco Lab using mix of virtual and physical components. Several technical choices - combination of virtual/physical, NFS server, limited resources for the OpenShift Master, some virtual Worker nodes, etc - are just compromises to cope with the Lab resources. As a reference, all this stuff runs at my home.
Everything that is built on top of the virtualization stack (in my case VMware vSphere) is explained in greater detail, but the vSphere environment itself is only lightly touched and a reference Host Profile is also provided.
In the near future the following topics will also be covered
- FD.IO VPP App
- Use an external CA for the entire platform
- MetalLB BGP
- Contour
- CNV
- Rook
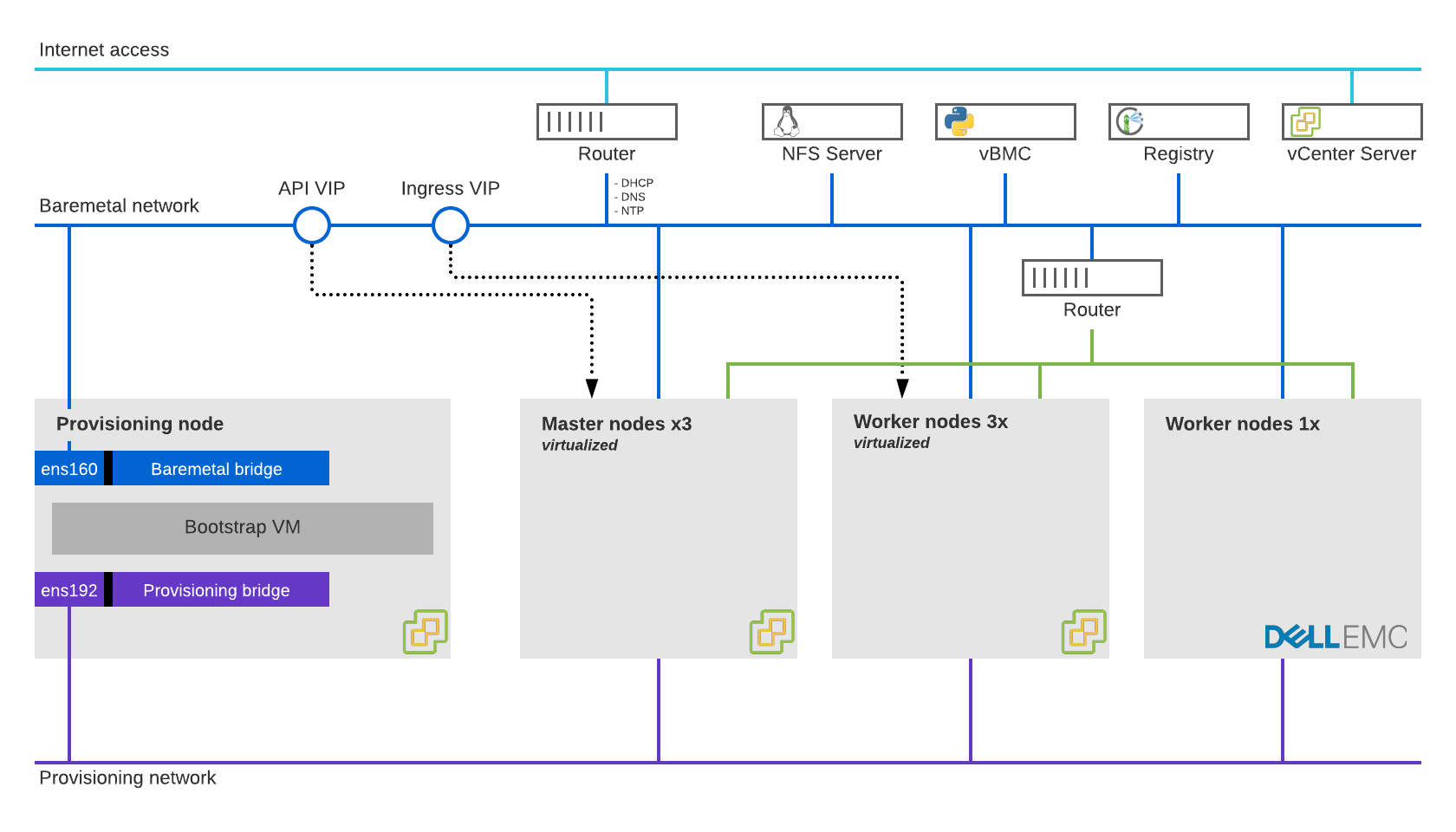
The lab is quite linear. Fundamentally there are three PowerEdge Server and a Brocade Fabric made of two ICX Switch:
- A management Brocade ICX 6610 mainly for 1Gbps
- 1Gbps on copper for all PXE/Baremetal interfaces
- Still 1Gbps on copper for the local home connection
- 10Gbps on DAC for the ESXi node
- The ICX 6610 runs the latest FastIron 08.0.30u using the routing firmware
- A core Brocade ICX 7750 mainly for 10Gbps and 40Gbps
- 10Gbps on DAC for all the physical interfaces (X520s, XXV710s, E810, CX5s etc)
- The ICX 7750 run the latest FastIron 08.0.95ca using the routing firmware
- The 7750 also acts as a BGP router for MetalLB
- For the server hardware, three PowerEdge server G13 from Dell-EMC
- The ESXi node is an R630 with 2x Xeon E5-2673 v4 (40 cores/80 threads) and 256GB of memory
- The physical OCP Worker node is also an R630 with 2x Xeon E5-2678 v3 (24 cores/48 threads) and 64GB of memory
- There 3rd node, an R730xd (2x Xeon E5-2673 v4 + 128GB of memory) currently used only as a traffic generator
More information about the hardware physical layout:
- Lab Low-Level Design
- Brocade ICX 6610 config
- Brocade ICX 7750 config
Software-wise, things are also very linear:
- As the generic OS to provide all sort of functions (Routing, NAT, DHCP, DNS, NTP etc): CentOS Stream 8
- CentOS Stream 8 is also used for NFS (the Kubernetes SIG NFS Client is deployed to have the NFS Storage Class) and OCP moving to the RHEL 8.3 kernel with OCP 4.7,
NFS session trunkingbecomes available - OpenShift Container Platform version 4.7 (but the aim here is to have something entirely usable for future major releases)
Let's address the elephant in the room: why VMware vSphere? Well, there are a couple of reasons, but before that let me state loud and clear, everything achived in this document can absolutely be done on plain Linux KVM. VMware vSphere is my choise and doesn't have to be yours:
- While OpenShift supports many on-premise platforms (OpenStack, oVirt, pure bare-metal, and vSphere), the power of an indeed Enterprise Virtualization Platform could play an essential role in how the lab evolves, and it could also act as a reference (for example, today real production on bare-metal has a minimum footprint of 7 nodes: 3x Master + 3x Infra + 1x Provisioner)
- In general, VMware is just better at hardware virtualization and there might be some edge cases where it becomes instrumental. Last year my OpenStack NFVi Lab moved to vSphere because I wanted to expose virtual NVMe devices to my Ceph Storage nodes (of course, not everything is better, tip: if you're interested, compare CPU & NUMA Affinity and the SMP topology capability of ESXi and KVM)
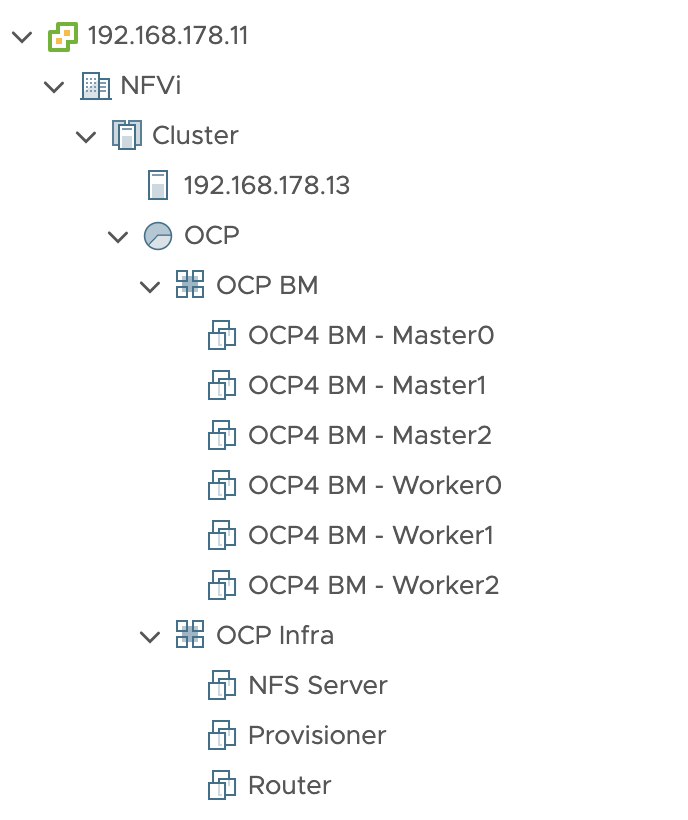
The vSphere architecture is also very lean. Its usually as updated as possible, generally running the latest version plus the DellEMC Bundle.
- ESXi 7.0 Update 2a (
17867351) - vCenter Server deployed through vCSA 7.0 Update 2a (
17920168) - The vSphere topology has a single DC (
NFVi) and a single cluster (Cluster) - DRS in the cluster is enabled (but having a single ESXi, it won't make any migration)
- DRS's CPU over-commit ratio is not configured
- A Storage Cluster with SDRS enabled using two local NVMe
- Samsung 970 Evo Plus of 2TB
- Samsung 970 Evo of 1TB
- On the network side of the house, a single vDS called
DVS01- Virtual Distributed Switch version 7.0.2 (which finally adds support for LACP
fast) - A single upstream
lag1with two Intel X710 ports, bonded together using LACP - Several
Distributed Port Groupsfor my House network (replacing the defaultVM Networkon vSS withDPG178 - Home), Batemetal and Provisioning network, etc - MTU set to 9000 to allow Jumbo Frames
- Virtual Distributed Switch version 7.0.2 (which finally adds support for LACP

A quick note about the Distributed Port Groups Security configuration:
Promiscuous modeconfigured toAccept(defaultReject)MAC address changesconfigured toAccept(defaultReject)Forged transmitsconfigured toAccept(defaultReject)
I personally found that the above configuration only works with ESXi 7 (tested with both U1 and U2) and the latest minors of ESXi 6.7u3 17700523. Early 6.7u3 builds have a different behavior of learning (or not actually) the MAC Address. When such behavior/bug happens, the Bootstrap VM running on top of the Provisioner node, won't have a fully functional networking stack.
VMware seems not very transparent regarding these vDS capabilities (the entire vSphere Networking library doesn't mention anything about MAC Learning) and reading online ESXi 6.7 introduced a major change in how vDS natively learn MAC Address.
Regarding the VMs configuration:
- All the VM use the latest vHW 19
- The VM Guest OS Profile is configured for RHEL8 (the firmware is set to
EFIandSecure Bootis disabled). The OpenShift installer has only recently gained the SecureBoot capability, which will be probably available with OCP 4.8 vNUMAis disabled, exposing a single socket (aka equal number ofvCPUandCores per socket)I/O MMUandHardware virtualization(akaNested Virtualization) are both enabled- VMware VMXNET 3 v4 is the network para-virtualized driver for all interfaces. VMware has known poor support for PXE. The result is a slower PXE boot phase which sometimes also fails (BTW, from this point of view KVM just works)
- VMware NVMe v1.3 is the storage controller for all VMs (for who's asking about PVSCSI vs. NVMe, see the comparison)
- In the
install-config.yamlthe Root device hints is specified referring todeviceName: "/dev/nvme0n1"
- In the
The only real peculiarity in this environment is that OpenShift is deployed using IPI for Bare-metal on a mix vSphere and physical hardware. VMware doesn't have something like a virtual IPMI device; hence a vBMC solution is used.
- For this environment, virtualbmc-for-vsphere is the vBMC solution managing the power management of the VMs. HUGE Thanks to @kurokobo for his massive work on virtualbmc-for-vsphere and effectively setting the foundation of this lab (in case the blog disappear, link to web archive)
- As an alternative option, a combination of python-virtualbmc plus libvirt is also possible (this is how my OpenStack NFVi Lab works)
- Something else worth keeping an eye on is sushy-tools. The
sushy-toolsproject already supports advanced RedFish features such as Virtual Media throughLibvirton QEMU/KVM, and there are indications that VMware support may come at some point
Besides Sushy, I personally tested both virtual BMC methods and they work very well. Moreover, for about a year now, the pure python-virtualbmc plus libvirt approach has been rock solid in my NFVi OpenStack Lab, but there is a caveat: while with python-virtualbmc the VM's boot order must be manually configured (PXE always first) @kurokobo made a specific implementation to solve this problem effectively making virtualbmc-for-vsphere superior.
There are mainly two ways (besides buying a complete subscription)
- 60-days VMware evaluation most (all?) VMware products come with a trial of 60 days.
- VMUG Learning Program is basically the must-have solution to learn all VMware solutions. With 200$/year, one gets access to NRF subscriptions for all VMware software + offline training.
Similar to VMware vSphere, why OpenShift and not pure Kubernetes? Also here, many reasons:
- As with all Red Hat Products, one gets a well-integrated and well-tested plateau of open source solutions that greatly expand the final value. See the official architectural notes about what OpenShift includes.
- Performance: Telcos have some of the most bizarre performance requirements in the entire industry: network latency, packet-per-second rate, packet-drop rate, scheduling latency, fault detection latency, NUMA affinity, dedicated resources (CPU, L3 cache, Memory bandwidth, PCI devices) etc. Red Hat has been working for many years now to achieve deterministic performance (you can read more on my posts at Tuning for Zero Packet Loss in OpenStack Part1, Part2, and Part3 and also Going full deterministic using real-time in OpenStack). That work, which started with RHEL and eventually included also OpenStack, is now covering OpenShift as well with PAO (or Performance Addon Operator).
- Security: in February 2019, to date, the major vulnerability of RunC (CVE-2019-5736) allowed malicious containers to literally take control of the host. This made people literally scramble, and yet OpenShift, thanks to SELinux, was protected from the start. Even further, I strongly recommend reading about the Security Context Constraints and how is managed in OpenShift
- Usability: honestly, the OpenShift Console and the features in the OC (OpenShift Client) CLI are nothing less than spectacular.
- Immutability: CoreOS makes the entire upgrade experience, finally, trivial.
- Observability: OpenShift ships with pre-configured Alarms and Performance Monitoring (based on Prometheus), and additionally fully supported Logging Operator (based on EFK) is also available.
- Virtualization: Well it might sound odd but having around virtualization capability within the same platform actually can be very handy. For cloud-native develop because maybe there is a monolith not cloud-native yet, for Telco because perhaps they have e.g. a QNX appliance which, for apparent reason, won't become Linux-base any time soon.
- RHEL: RHCOS (Red Hat CoreOS) uses the same RHEL Kernel and userland as a regular RHEL 8 (albeit the userland utilities are minimal). People may say stuff like "the RHEL kernel is outdated" but I dear you to check the amounts of backports Red Hat does (
rpm -q --changelog kernel) plus all the stability and scalability testing and, of course, upstream improvements. Latest doesn't necessarily mean most excellent. In RHEL, the versioning number is fricking meaningless. A couple of examples to dig more details about the Networking stack of RHEL and the Linux kernel virtualization limits and how using a tested version is essential.
Much more is available in OpenShift (Argo CI, Istio, a vast ecosystem of certified solutions, etc), but it won't be cover here.
About the OpenShift Architecture, as the diagram above shows:
- Standard OpenShift control-plane architecture made out of three Master (with highly available ETCD)
- Three virtualized Worker nodes to run internal services (e.g. console, oauth, monitoring etc) and anything non-performance intensive
- One physical Worker node to run Pods with SR-IOV devices
- The deployment is Bare-metal IPI (installer-provisioned infrastructure), but the VMware VMs are created manually
- Being a bare-metal deployment, a LoadBalancer solution is required and for this, MetalLB is the go-to choice
- A Linux router is available to provide the typical network services such as DHCP, DNS, and NTP as well Internet access
- A Linux NFS server is installed and, later on, the Kubernetes SIG NFS Client is deployed through
Helm OVNKubernetesis the choosen CNI Network provider. OVN has some serious advantages in regards to networking and usingOpenShiftSDNwon't really make sense for Telco use-cases.- The entire platform is configured with Jumbo Frames. This grately helps any communications, especially internal pod-to-pod ones and storage.
To reassume the VMs configuration
| VM Name | vHW | vCPU | vMemory | Root vDisk | Data vDisk | vNIC1 (ens160) | vNIC2 (ens192) | Storage Device | Ethernet Device |
|---|---|---|---|---|---|---|---|---|---|
| Router | 19 | 4 | 16 GB | 20GiB | n/a | DPG178 - Home | DPG110 - Baremetal | NVMe v1.3 | VMXNET 3 v4 |
| Provisioner | 19 | 4 | 16 GB | 70GiB | n/a | DPG110 - Baremetal | DPG100 - PXE | NVMe v1.3 | VMXNET 3 v4 |
| Master-0 | 19 | 4 | 16 GB | 70GiB | n/a | DPG100 - PXE | DPG110 - Baremetal | NVMe v1.3 | VMXNET 3 v4 |
| Master-1 | 19 | 4 | 16 GB | 70GiB | n/a | DPG100 - PXE | DPG110 - Baremetal | NVMe v1.3 | VMXNET 3 v4 |
| Master-2 | 19 | 4 | 16 GB | 70GiB | n/a | DPG100 - PXE | DPG110 - Baremetal | NVMe v1.3 | VMXNET 3 v4 |
| Worker-0 | 19 | 8 | 32 GB | 70GiB | n/a | DPG100 - PXE | DPG110 - Baremetal | NVMe v1.3 | VMXNET 3 v4 |
| Worker-1 | 19 | 8 | 32 GB | 70GiB | n/a | DPG100 - PXE | DPG110 - Baremetal | NVMe v1.3 | VMXNET 3 v4 |
| Worker-2 | 19 | 8 | 32 GB | 70GiB | n/a | DPG100 - PXE | DPG110 - Baremetal | NVMe v1.3 | VMXNET 3 v4 |
| NFS Server | 19 | 2 | 16 GB | 70GiB | 300GiB | DPG110 - Baremetal | n/a | NVMe v1.3 | VMXNET 3 v4 |
Also available in Google Spreadsheet the Low-Level Design of the lab in much greater detail.
The OpenShift Domain configuration
- Base Domain:
bm.nfv.io - Cluster Name:
ocp4

If you don't know what PAO is, I strongly encourage you to read the official documentation. In short, a Tuned CPU-Partitioning on steroid includes additional profiles and specific tuning for a containerization platform and takes into account also the K8s Topology Manager. Of course, PAO is applied only to the real physical worker nodes.
- CPU: One
reservedfull core (aka 2 threads) per NUMA node, all the othersisolatedfor the applications - Memory: 16GB available for the OS and Pods while all the rest configured as 1GB HugePages
- Topology Manager: set to
single-numa-nodeto ensure the NUMA Affinity of the Pods (well, actually each Container in the Pod). As of K8s 1.20/OCP 4.7, Topology Manager doesn't have the ability to exclude the SMT sibling threads (HyperThreading is the Intel name). A PR has been opended upstream but the community would like to solve this problem more elegantly with a pluggable Topology Manager. To work around this limitation, there are two main ways:- Disable SMT either through the BIOS or using the
nosmtKernel command line in GRUB - Assign even number of cores to a container keeping in mind half will be siblings (if an odd number is used, you won't be able to predict which is what)
- In both cases, one can check the assigned cores using
cat /sys/fs/cgroup/cpuset/cpuset.cpus
- Disable SMT either through the BIOS or using the
- Kernel: the standard, low-latency, non-RealTime kernel is used. Not every single CNF will benefit from a RealTime Kernel. RealTime always requires a RTOS and a RT application. When is not, thing will be slower without any deterministic benefit. Additionally, the RHEL Real-Time Kernel in OCP 4.6 and 4.7 has a known issue in combination with Open vSwitch, degrading the RT latency performance.
Also available in Google Spreadsheet a table view Low-Level Design of the partitioning.
This section aims to provide the configuration needed to deploy all the components.
The Router, NFS Server and Provisioner VMs are created manually in vSphere (refer to the VMware section for the details). Follows a list of configurations common to all of them:
- CentOS Stream 8
- Minimal Install + Guest Agents
- UTC Timezone
- LVM, no swap, XFS file-system
- Static IP Addresses (see the LLD for the details)
A set of common steps are applied to all the VM
After the CentOS Stream 8 is installed, all the packages are updated
- Install the Advanced-Virtualization Repos
- Disable the standard RHEL Virtualization module
- Enable the Container-tool module (by default enabled)
- Update all the packages
dnf install -y centos-release-advanced-virtualization
dnf makecache
dnf module enable -y container-tools:rhel8
dnf module disable -y virt
dnf upgrade -yOnce concluded, several packages are installed (the list is self-explanatory)
dnf install -y bash-completion bind-utils cockpit cockpit-storaged \
chrony git jq lsof open-vm-tools \
podman-docker tcpdump tmux vim
dnf module -y install container-toolsRun the Open VM-Tools at boot
systemctl enable --now vmtoolsd vgauthdBeing this CentOS 8 Stream we already have available Podman 3.0 which supports the Docker REST API so let's start it and also install docker-compose
systemctl enable --now podman.socket
curl -L "https://github.com/docker/compose/releases/download/1.29.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
ln -s /usr/local/bin/docker-compose /usr/bin/docker-composeFinally run the RHEL Cockpit web interface
systemctl enable --now cockpit.socket
firewall-cmd --permanent --zone=external --add-service=cockpit
firewall-cmd --reloadIt's quite handy having around a certification autority to later sign OCP traffic, Registry etc.
Let's create a self-signed RootCA. I'm gonna do it on the router, the CRT needs to be copied and installed everywhere.
_DIR=/root/certs
mkdir -p /root/certs
openssl req \
-new \
-newkey rsa:2048 \
-days 3650 \
-nodes \
-x509 \
-subj "/CN=nfv.io" \
-keyout "${_DIR}/ca.key" \
-out "${_DIR}/ca.crt"To verify the content openssl x509 -in "${_DIR}/ca.crt" -noout -text
To ensure any system will trust certificates issued by the RootCA, simply copy the ca.crt and run
cp /root/ca.crt /etc/pki/ca-trust/source/anchors/
update-ca-trust extractFirst off, let's deploy DNSMasq. Being originally an OpenStack guy, DNSMasq feels home (back in my old public-cloud days, I remember experiencing a DoS caused by the log-queries facility when malicious users generate many 1000s of DNS queries per second)
Instead of installing whatever CentOS Stream provides, let's run it inside a container. Follows you can find the Dockerfile. It's really simple and does the following
- The base image is Alpine Linux 3.13
- Takes latest DNSMasq available (2.85)
- Enable DNSMasq and ignore the local
resolv.conf
FROM alpine:3.13
# Install DNSMasq
# https://git.alpinelinux.org/aports/tree/main/dnsmasq/APKBUILD?h=3.13-stable
RUN apk update \
&& apk --no-cache add dnsmasq=2.85-r2
# Configure DNSMasq
RUN mkdir -p /etc/default/
RUN printf "ENABLED=1\nIGNORE_RESOLVCONF=yes" > /etc/default/dnsmasq
# Run it!
ENTRYPOINT ["dnsmasq","--no-daemon"]And also here the docker-compose file to run our DNSMasq container. It does the following:
- The container uses Host network
- The configuration file are under
/opt/dnsmasq/ journaldlogging driver (runningjournalctl -f CONTAINER_NAME=dnsmasqyou will see all the logs)
version: '3.8'
services:
dnsmasq:
network_mode: host
cap_add:
- NET_ADMIN
volumes:
- '/opt/dnsmasq/dnsmasq.d:/etc/dnsmasq.d:Z'
- '/opt/dnsmasq/dnsmasq.conf:/etc/dnsmasq.conf:Z'
- '/opt/dnsmasq/hosts.dnsmasq:/etc/hosts.dnsmasq:Z'
- '/opt/dnsmasq/resolv.dnsmasq:/etc/resolv.dnsmasq:Z'
dns:
- 1.1.1.1
- 8.8.8.8
logging:
driver: journald
restart: unless-stopped
image: dnsmasq:2.85
container_name: dnsmasqTo build the image, simply run podman image build --tag dnsmasq:2.85 . in the directory where the Dockerfile is available
Let's create our directory to store all DNSMasq files and also the generic config
mkdir -p /opt/dnsmasq/dnsmasq.d
cat > /opt/dnsmasq/dnsmasq.conf << 'EOF'
conf-dir=/etc/dnsmasq.d
EOFBefore actually doing the DNS configuration, if you come across some DNS issues, I strongly suggest reading the nothing less than amazing @rcarrata DNS deep-dive. Additionally, also Red Hat has a nice DNS Troubleshooting guide.
Now on the DNS configuration:
- Internal DNS Resolution
- Basic DNSMasq configuration with the local domain
ocp4.bm.nfv.ioand name resolution caching - If running, restart the service
- If not configured to start at boot, enable it and start it now
cat > /opt/dnsmasq/hosts.dnsmasq << 'EOF'
10.0.11.1 diablo diablo.ocp4.bm.nfv.io
10.0.11.2 openshift-master-0 openshift-master-0.ocp4.bm.nfv.io
10.0.11.3 openshift-master-1 openshift-master-1.ocp4.bm.nfv.io
10.0.11.4 openshift-master-2 openshift-master-2.ocp4.bm.nfv.io
10.0.11.5 openshift-worker-0 openshift-worker-0.ocp4.bm.nfv.io
10.0.11.6 openshift-worker-1 openshift-worker-1.ocp4.bm.nfv.io
10.0.11.7 openshift-worker-2 openshift-worker-2.ocp4.bm.nfv.io
10.0.11.11 openshift-worker-cnf-1 openshift-worker-cnf-1.ocp4.bm.nfv.io
10.0.11.18 api api.ocp4.bm.nfv.io
10.0.11.28 provisioner provisioner.ocp4.bm.nfv.io
10.0.11.29 nfs-server nfs-server.ocp4.bm.nfv.io
10.0.11.30 router router.ocp4.bm.nfv.io
EOF
cat > /opt/dnsmasq/resolv.dnsmasq << 'EOF'
nameserver 1.1.1.1
nameserver 8.8.8.8
EOF
cat > /opt/dnsmasq/dnsmasq.d/dns.dnsmasq << 'EOF'
domain-needed
bind-dynamic
bogus-priv
domain=ocp4.bm.nfv.io
interface=ens160,ens192
no-dhcp-interface=ens160
no-hosts
addn-hosts=/etc/hosts.dnsmasq
resolv-file=/etc/resolv.dnsmasq
expand-hosts
cache-size=500
address=/.apps.ocp4.bm.nfv.io/10.0.11.19
EOFDHCP Time
- Set the DHCP Range (from 10.0.11.2 to 10.0.11.17)
- Define the default route to 10.0.11.30 (config
serverand more commonlyoption 6) - Define the DNS to 10.0.11.30 (
option 3) - Define the NTP to 10.0.11.30 (
option 42) - Define the MTU size to 9000 (
option 26) - Instruct DNSMasq always to send the DHCP options even when not requested (
dhcp-option-force)
cat > /opt/dnsmasq/dnsmasq.d/dhcp.dnsmasq << 'EOF'
domain-needed
bind-dynamic
bogus-priv
dhcp-range=10.0.11.2,10.0.11.17
dhcp-option-force=3,10.0.11.30
dhcp-option-force=42,10.0.11.30
dhcp-option-force=26,9000
server=10.0.11.30
dhcp-host=00:50:56:8e:56:31,openshift-master-0.ocp4.bm.nfv.io,10.0.11.2
dhcp-host=00:50:56:8e:8e:6d,openshift-master-1.ocp4.bm.nfv.io,10.0.11.3
dhcp-host=00:50:56:8e:66:b0,openshift-master-2.ocp4.bm.nfv.io,10.0.11.4
dhcp-host=00:50:56:8e:16:11,openshift-worker-0.ocp4.bm.nfv.io,10.0.11.5
dhcp-host=00:50:56:8e:c9:8e,openshift-worker-1.ocp4.bm.nfv.io,10.0.11.6
dhcp-host=00:50:56:8e:f2:26,openshift-worker-2.ocp4.bm.nfv.io,10.0.11.7
dhcp-host=ec:f4:bb:dd:96:29,openshift-worker-cnf-1.ocp4.bm.nfv.io,10.0.11.11
EOFLet's start our DNSMasq Container (make sure to be in the directory where the docker-compose.yaml is available)
docker-compose up --build --detachLast but not least, let's ensure the DNSMasq container will be presistent after reboot
podman generate systemd dnsmasq > /etc/systemd/system/dnsmasq-container.service
systemctl daemon-reload
systemctl enable --now dnsmasq-container.serviceNow that we have it, we can also use DNSMasq for local resolution
nmcli connection modify ens160 ipv4.dns 127.0.0.1
nmcli connection modify ens160 ipv4.dns-search ocp4.bm.nfv.ioLet's move then to the configuration of NTP through Chrony
- Allow Chrony to provide NTP to any host in the
DPG110 - BaremetalNetwork - If running, restart the service
- If not configured to start at boot, enable and start it now
echo "allow 10.0.11.0/27" | tee -a /etc/chrony.conf
systemctl is-active chronyd && systemctl restart chronyd
systemctl is-enabled chronyd || systemctl enable --now chronydLet's configure routing capability
- Associate the
Externalzone toens160(connected toDPG178 - Homewith Internet access) - Associate the
Internalzone toens192(connected to OSP Baremetal) - Allow Masquerade between Internal to External (effectively NAT)
nmcli connection modify ens160 connection.zone external
nmcli connection modify ens192 connection.zone internal
firewall-cmd --permanent --zone=internal --add-masquerade
firewall-cmd --reloadLet's open the firewall for all relevant services
- Internal Zone: NTP, DNS, and DHCP
- External Zone: DNS and Cockpit
firewall-cmd --permanent --zone=internal --add-service=ntp
firewall-cmd --permanent --zone=internal --add-service=dns
firewall-cmd --permanent --zone= external --add-service=dns
firewall-cmd --permanent --zone=internal --add-service=dhcp
firewall-cmd --reloadThe final step, after all the updates and config changes, let's reboot the VM
rebootThe virtualbmc effectively runs off the router in my lab but it can be executed anywhere else (like in a container)
I might take a somehow outdated way of managing python packages, would definitely be cool running in a container :-P but I'll leave this for the future. At least I'm NOT BADLY doing pip install on the live system but inside a sane and safe virtualenv
Let's, first of all, install Python virtual environments
dnf install -y ipmitool OpenIPMI python3-virtualenv python3-pyvmomi gcc makeThen we can proceed with the installation of virtualbmc-for-vsphere from @kurokobo - Thanks again!
virtualenv /root/vBMC
source /root/vBMC/bin/activate
pip install --upgrade pip
pip install vbmc4vsphereOnce done, we allow the IPMI connections in the firewall
firewall-cmd --permanent --zone=internal --add-port=623/udp
firewall-cmd --reloadLastly, we can start our virtualbmc-for-vsphere. I've created a simple wrapper:
- Activate the Python virtualenv
- Retrieve the password for the vSphere connection
- Add local IP Address (one per vBMC instance)
- Start the
vbmcddaemon - Verify if the vBMC instance exist and eventually add it
- Start the IPMI service
- Check the IPMI status
- It's important to note that the vBMC name MUST match the VM's name in vSphere
Additionally, being a lab, during a cold OCP start if vBMC is not already running, Metal3 will lose the ability to manage the nodes until the power status is reset (indeed, this is something to report upstream, losing connectivity with the BMC is relatively common: firmware upgrade, OoB upgrade, network outage etc)
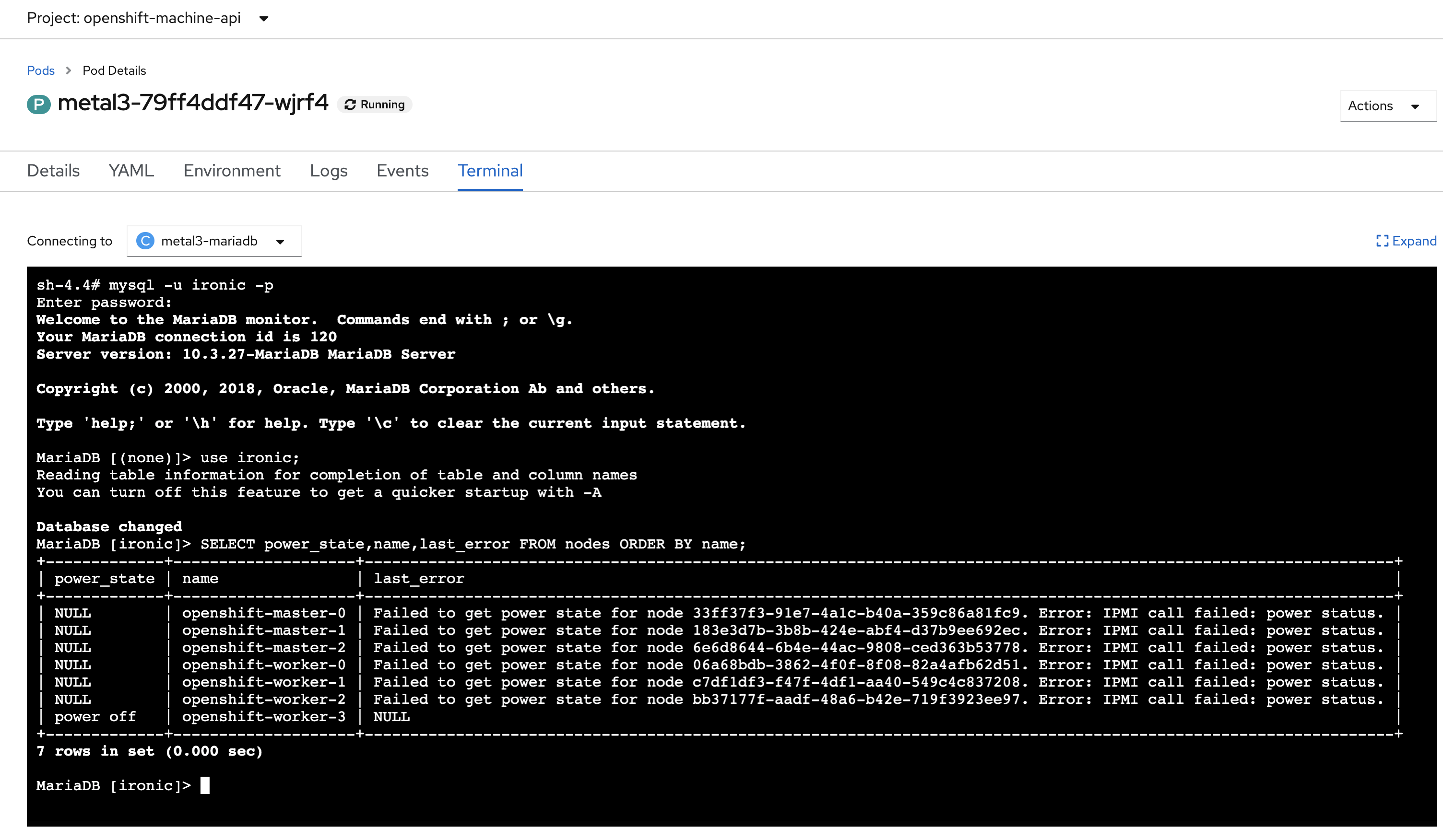
cat > /root/vBMC.sh << 'EOF'
#!/bin/bash
echo -n "vCenter Administrator Password: "
read -s _PASSWORD
echo
_vCSACONNECTION="--viserver 192.168.178.12 --viserver-username [email protected] --viserver-password ${_PASSWORD}"
source /root/vBMC/bin/activate
ip addr show ens160 | grep -q "192.168.178.25/24" || ip addr add 192.168.178.25/24 dev ens160
ip addr show ens160 | grep -q "192.168.178.26/24" || ip addr add 192.168.178.26/24 dev ens160
ip addr show ens160 | grep -q "192.168.178.27/24" || ip addr add 192.168.178.27/24 dev ens160
ip addr show ens160 | grep -q "192.168.178.28/24" || ip addr add 192.168.178.28/24 dev ens160
ip addr show ens160 | grep -q "192.168.178.29/24" || ip addr add 192.168.178.29/24 dev ens160
ip addr show ens160 | grep -q "192.168.178.30/24" || ip addr add 192.168.178.30/24 dev ens160
pkill -15 vbmcd
rm -f /root/.vbmc/master.pid
vbmcd
vbmc show "OCP4 BM - Master0" 2>/dev/null || vbmc add --username root --password calvin --address 192.168.178.25 --port 623 ${_vCSACONNECTION} "OCP4 BM - Master0"
vbmc show "OCP4 BM - Master1" 2>/dev/null || vbmc add --username root --password calvin --address 192.168.178.26 --port 623 ${_vCSACONNECTION} "OCP4 BM - Master1"
vbmc show "OCP4 BM - Master2" 2>/dev/null || vbmc add --username root --password calvin --address 192.168.178.27 --port 623 ${_vCSACONNECTION} "OCP4 BM - Master2"
vbmc show "OCP4 BM - Worker0" 2>/dev/null || vbmc add --username root --password calvin --address 192.168.178.28 --port 623 ${_vCSACONNECTION} "OCP4 BM - Worker0"
vbmc show "OCP4 BM - Worker1" 2>/dev/null || vbmc add --username root --password calvin --address 192.168.178.29 --port 623 ${_vCSACONNECTION} "OCP4 BM - Worker1"
vbmc show "OCP4 BM - Worker2" 2>/dev/null || vbmc add --username root --password calvin --address 192.168.178.30 --port 623 ${_vCSACONNECTION} "OCP4 BM - Worker2"
vbmc show "OCP4 BM - Master0" | grep status | grep -q running || vbmc start "OCP4 BM - Master0"
vbmc show "OCP4 BM - Master1" | grep status | grep -q running || vbmc start "OCP4 BM - Master1"
vbmc show "OCP4 BM - Master2" | grep status | grep -q running || vbmc start "OCP4 BM - Master2"
vbmc show "OCP4 BM - Worker0" | grep status | grep -q running || vbmc start "OCP4 BM - Worker0"
vbmc show "OCP4 BM - Worker1" | grep status | grep -q running || vbmc start "OCP4 BM - Worker1"
vbmc show "OCP4 BM - Worker2" | grep status | grep -q running || vbmc start "OCP4 BM - Worker2"
ipmitool -H 192.168.178.25 -U root -P calvin -p 623 -I lanplus power status
ipmitool -H 192.168.178.26 -U root -P calvin -p 623 -I lanplus power status
ipmitool -H 192.168.178.27 -U root -P calvin -p 623 -I lanplus power status
ipmitool -H 192.168.178.28 -U root -P calvin -p 623 -I lanplus power status
ipmitool -H 192.168.178.29 -U root -P calvin -p 623 -I lanplus power status
ipmitool -H 192.168.178.30 -U root -P calvin -p 623 -I lanplus power status
EOFAt this point, to run our vBMC server, just execute the following
chmod +x /root/vBMC.sh
/root/vBMC.shThis time around, the number of steps is way less. Make sure the interface has an MTU 9000 to allow Jumbo Frames also for NFS.
Let's install the NFS packages
dnf install nfs-utils nfs4-acl-tools sysstat -yLet's enable the NFS Server
systemctl enable --now nfs-serverLet's make NFS is fully accessible, restart the NFS client services and export it
chown -R nobody: /nfs
chmod -R 777 /nfs
cat > /etc/exports << 'EOF'
/nfs 10.0.11.0/27(rw,sync,no_all_squash,root_squash)
EOF
systemctl restart nfs-utils
exportfs -arvAnd indeed open up the firewall
firewall-cmd --permanent --add-service=nfs
firewall-cmd --permanent --add-service=rpc-bind
firewall-cmd --permanent --add-service=mountd
firewall-cmd --reloadOnce all done, the system can be rebooted to also pick up the newer Kernel
rebootWell, if the Router was kinda hard and the NFS Server definitely lighter, the Provisioner has more manual activities than what I'd personally expect from OCP. I guess that's due to the version 1.0 effect. In short, we need to reconfigure the networking (adding two Linux bridge) and also install and configure Libvirt (and later download a special installer packer).
Let's start creating the provisioning bridge connected to our DPG100 - PXE network. In this lab ens192 is our device. What we're going to do is the following
- Delete the
ens192connection details in NetworkManager - Create the
provisioningbridge and connect it toens192 - Re-add its own Network settings
- IPv6 only link-local
- Disable STP (otherwise the connection takes 30 seconds to establish)
- Jumbo Frames
nmcli connection down ens192
nmcli connection delete ens192
nmcli connection add ifname provisioning type bridge con-name provisioning
nmcli con add type bridge-slave ifname ens192 master provisioning
nmcli connection modify provisioning ipv4.addresses 10.0.10.28/27 ipv4.method manual
nmcli connection modify provisioning ethernet.mtu 9000
nmcli connection modify bridge-slave-ens192 ethernet.mtu 9000
nmcli connection modify provisioning ipv6.method link-local
nmcli connection modify provisioning bridge.stp no
nmcli connection modify provisioning connection.autoconnect yes
nmcli connection down provisioning
nmcli connection up provisioningThe second bridge to create is the baremetal connected to our DPG110 - Baremetal. Our SSH session is going through this link. Looks like NetworkManager doesn't support performing a group of atomic operation at once (I may be wrong of course), so we're going to execute an entire block of NetworkManager commands in an uninterruptible manner through nohup. Same as before
- Delete the
ens160connection details in NetworkManager - Create the
baremetalbridge and connect it toens160 - Re-add its own Network settings
- IPv6 only link-local
- Disable STP (otherwise the connection takes 30 seconds to establish)
- Jumbo Frames
nohup bash -c "
nmcli connection down ens160
nmcli connection delete ens160
nmcli connection add ifname baremetal type bridge con-name baremetal
nmcli con add type bridge-slave ifname ens160 master baremetal
nmcli connection modify baremetal ipv4.addresses 10.0.11.28/27 ipv4.method manual
nmcli connection modify baremetal ipv4.dns 10.0.11.30
nmcli connection modify baremetal ipv4.gateway 10.0.11.30
nmcli connection modify baremetal ethernet.mtu 9000
nmcli connection modify bridge-slave-ens160 ethernet.mtu 9000
nmcli connection modify baremetal ipv6.method link-local
nmcli connection modify baremetal bridge.stp no
nmcli connection modify baremetal connection.autoconnect yes
nmcli connection down baremetal
nmcli connection up baremetal
"If the connection dropped, inspect the nohup.out file, it may reveal what went wrong :-D. Otherwise, that file can be deleted and we can install libvirt and start the service
dnf install -y libvirt qemu-kvm mkisofs python3-devel jq ipmitool OpenIPMI cockpit-machines
systemctl enable --now libvirtdOnce done, let's add the a privilaged kni user, which ultimately kickstart the deployment
- Add the
kniuser - No password
- Allow it to become root without prompting for password
- Add
knito thelibvirtgroup
useradd kni
passwd --delete kni
echo "kni ALL=(root) NOPASSWD:ALL" | tee -a /etc/sudoers.d/kni
chmod 0440 /etc/sudoers.d/kni
usermod --append --groups libvirt kniLet's finish the KNI user configuration. Connect to the KNI user first
- Create an SSH Key (optionally, you can import your own)
- Define the default Libvirt storage pool
- Remove the default Libvirt network
sudo su - kni
ssh-keygen -b 2048 -t rsa -f ~/.ssh/id_rsa -q -N ""
sudo virsh pool-define-as --name default --type dir --target /var/lib/libvirt/images
sudo virsh pool-start default
sudo virsh pool-autostart default
sudo virsh net-destroy default
sudo virsh net-undefine defaultLastly, let's reboot the system to also pick up the newer Kernel
rebootOnce all the above is done, it's finally time to perform the deployment of OCP. As the official procedure clearly hint, there are many manual steps needed before we can truly start. Hopefully, in the future, the product will require fewer human interactions.
As a first step, we need to install a different kind of openshift-install client, which includes the baremetal Metal3 provider. It's called openshift-baremetal-install. Honestly, I don't even understand why there is a dedicated client-specific for baremetal, anyways ... to download it you need your Pull Secret. You can download it manually or create a neat showpullsecret CLI command following this KCS. In both ways, ensure you have it locally available at ~/pull-secret.json. With that out of the way, we can finally download the baremetal client
_CMD=openshift-baremetal-install
_PULLSECRETFILE=~/pull-secret.json
_DIR=/home/kni/
_VERSION=stable-4.7
_URL="https://mirror.openshift.com/pub/openshift-v4/clients/ocp/${_VERSION}"
_RELEASE_IMAGE=$(curl -s ${_URL}/release.txt | grep 'Pull From: quay.io' | awk -F ' ' '{print $3}')
curl -s ${_URL}/openshift-client-linux.tar.gz | tar zxvf - oc kubectl
sudo mv -f oc /usr/local/bin
sudo mv -f kubectl /usr/local/bin
oc adm release extract \
--registry-config "${_PULLSECRETFILE}" \
--command=${_CMD} \
--to "${_DIR}" ${_RELEASE_IMAGE}
sudo mv -f openshift-baremetal-install /usr/local/binLet's also install the bash Completion for all CLIs.
mkdir -p ~/.kube/
oc completion bash > ~/.kube/oc_completion.bash.inc
kubectl completion bash > ~/.kube/kubectl_completion.bash.inc
openshift-baremetal-install completion bash > ~/.kube/oc_install_completion.bash.inc
grep -q "oc_completion.bash.inc" ~/.bash_profile || echo "source ~/.kube/oc_completion.bash.inc" >> ~/.bash_profile
grep -q "kubectl_completion.bash.inc" ~/.bash_profile || echo "source ~/.kube/kubectl_completion.bash.inc" >> ~/.bash_profile
grep -q "oc_install_completion.bash.inc" ~/.bash_profile || echo "source ~/.kube/oc_install_completion.bash.inc" >> ~/.bash_profileOptionally you could configure a local image cache and in case of slow Internet connection, you should. I'm personally not going to explain it now in this first release. In the next follow-up, local cache and local OCI mirror will be both included (in the lab diagram, a local registry is already present).
Now the next major task is writing down the install-config.yaml file, on the official document you have examples and also all the options, there are only two thing to keep in mind:
provisioningNetworkInterfacerappresents the name of the interface in the Master which is connected to Provisioning Network (in my caseens160)- In case you don't have enough resources to run 3 Workers, you can adjust down
compute.replicas, see the official indications
Follows you can find my working install-config. The initial deployment goes without the physical Worker Node(s). They are included later together with a custom MachineSet.
apiVersion: v1
baseDomain: bm.nfv.io
metadata:
name: ocp4
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineCIDR: 10.0.11.0/27
serviceNetwork:
- 172.30.0.0/16
networkType: OVNKubernetes
compute:
- name: worker
replicas: 3
controlPlane:
name: master
replicas: 3
platform:
baremetal: {}
platform:
baremetal:
apiVIP: 10.0.11.18
ingressVIP: 10.0.11.19
provisioningBridge: provisioning
provisioningNetworkInterface: ens160
provisioningNetworkCIDR: 10.0.10.0/27
provisioningDHCPRange: 10.0.10.5,10.0.10.17
externalBridge: baremetal
bootstrapProvisioningIP: 10.0.10.3
clusterProvisioningIP: 10.0.10.4
hosts:
- name: openshift-master-0
role: master
bmc:
address: ipmi://192.168.178.25
username: root
password: calvin
bootMACAddress: 00:50:56:8e:3b:92
rootDeviceHints:
deviceName: "/dev/nvme0n1"
- name: openshift-master-1
role: master
bmc:
address: ipmi://192.168.178.26
username: root
password: calvin
bootMACAddress: 00:50:56:8e:81:cf
rootDeviceHints:
deviceName: "/dev/nvme0n1"
- name: openshift-master-2
role: master
bmc:
address: ipmi://192.168.178.27
username: root
password: calvin
bootMACAddress: 00:50:56:8e:50:a1
rootDeviceHints:
deviceName: "/dev/nvme0n1"
- name: openshift-worker-0
role: worker
bmc:
address: ipmi://192.168.178.28
username: root
password: calvin
bootMACAddress: 00:50:56:8e:b5:6e
rootDeviceHints:
deviceName: "/dev/nvme0n1"
- name: openshift-worker-1
role: worker
bmc:
address: ipmi://192.168.178.29
username: root
password: calvin
bootMACAddress: 00:50:56:8e:11:9f
rootDeviceHints:
deviceName: "/dev/nvme0n1"
- name: openshift-worker-2
role: worker
bmc:
address: ipmi://192.168.178.30
username: root
password: calvin
bootMACAddress: 00:50:56:8e:72:bf
rootDeviceHints:
deviceName: "/dev/nvme0n1"
fips: false
pullSecret: '{"auths":{<SNIP>}}'
additionalTrustBundle: |
-----BEGIN CERTIFICATE-----
<SNIP>
-----END CERTIFICATE-----
sshKey: 'ssh-rsa <SNIP>'The initial deployment may fail due to multiple reasons:
- Timeout due to slow Internet speed -> enable RHCOS image cache and/or local OCI registry
- DHCP issues (wrong IP, wrong Hostname, no DHCP) -> Check DNSMasq (if there is matching between
dns.dnsmasqandhosts.dnsmasqno weird issues should happen - No Internet -> Check the Router and specifically the Firewalld's Masquerade
- Not able to provide DHCP from the Provisioner -> You didn't disable the security features in vDS
- VMware VMs stuck in boot loop -> Disable
Secure Bootor switch toBIOS - Not able to boot the Bastion VM on the provisioner ->
Nested Virtualizationnot enabled
To deploy, let's copy the install-config.yaml into a new folder and then run the installation
mkdir ~/manifests
cp ~/install-config.yaml ~/manifests/
openshift-baremetal-install create cluster --dir ~/manifests --log-level debugFollows the vSphere events during the worker nodes deployment

Follows a worker node console during the PXE boot

Follows the installation logs
DEBUG OpenShift Installer 4.7.0
DEBUG Built from commit 98e11541c24e95c864328b9b35c64b77836212ed
<SNIP>
DEBUG Generating Cluster...
INFO Creating infrastructure resources...
<SNIP>
DEBUG module.masters.ironic_node_v1.openshift-master-host[2]: Creating...
DEBUG module.masters.ironic_node_v1.openshift-master-host[1]: Creating...
DEBUG module.masters.ironic_node_v1.openshift-master-host[0]: Creating...
DEBUG module.bootstrap.libvirt_pool.bootstrap: Creating...
DEBUG module.bootstrap.libvirt_ignition.bootstrap: Creating...
<SNIP>
DEBUG module.bootstrap.libvirt_volume.bootstrap-base: Creation complete after 4m59s
DEBUG module.bootstrap.libvirt_ignition.bootstrap: Creation complete after 4m59s
<SNIP>
DEBUG module.masters.ironic_node_v1.openshift-master-host[1]: Creation complete after 24m30s
DEBUG module.masters.ironic_node_v1.openshift-master-host[2]: Creation complete after 25m20s
DEBUG module.masters.ironic_node_v1.openshift-master-host[0]: Creation complete after 26m11s
<SNIP>
DEBUG module.masters.ironic_deployment.openshift-master-deployment[1]: Creating...
DEBUG module.masters.ironic_deployment.openshift-master-deployment[0]: Creating...
DEBUG module.masters.ironic_deployment.openshift-master-deployment[2]: Creating...
<SNIP>
DEBUG module.masters.ironic_deployment.openshift-master-deployment[0]: Creation complete after 1m32s
DEBUG module.masters.ironic_deployment.openshift-master-deployment[2]: Creation complete after 2m2s
DEBUG module.masters.ironic_deployment.openshift-master-deployment[1]: Creation complete after 2m2s
<SNIP>
DEBUG Apply complete! Resources: 14 added, 0 changed, 0 destroyed.
DEBUG OpenShift Installer 4.7.0
DEBUG Built from commit 98e11541c24e95c864328b9b35c64b77836212ed
INFO Waiting up to 20m0s for the Kubernetes API at https://api.ocp4.bm.nfv.io:6443...
INFO API v1.20.0+bd9e442 up
INFO Waiting up to 30m0s for bootstrapping to complete...
DEBUG Bootstrap status: complete
INFO Destroying the bootstrap resources...
<SNIP>
INFO Waiting up to 1h0m0s for the cluster at https://api.ocp4.bm.nfv.io:6443 to initialize...
<SNIP>
DEBUG Still waiting for the cluster to initialize: Working towards 4.7.0: downloading update
DEBUG Still waiting for the cluster to initialize: Working towards 4.7.0: 662 of 668 done (99% complete)
DEBUG Cluster is initialized
INFO Waiting up to 10m0s for the openshift-console route to be created...
<SNIP>
INFO Install complete!
INFO To access the cluster as the system:admin user when using 'oc', run 'export KUBECONFIG=/home/kni/manifests/auth/kubeconfig'
INFO Access the OpenShift web-console here: https://console-openshift-console.apps.ocp4.bm.nfv.io
INFO Login to the console with user: "kubeadmin", and password: "VnQXV-dCVm2-bU9ZJ-pv3Pr"
DEBUG Time elapsed per stage:
DEBUG Infrastructure: 28m22s
DEBUG Bootstrap Complete: 14m19s
DEBUG Bootstrap Destroy: 14s
DEBUG Cluster Operators: 25m54s
INFO Time elapsed: 1h8m58sOnce the deployment is over, we can proceed with the first step: the authentication. To make things simple, we will rely upon HTPasswd. Single admin user with password admin, later this will give the flexibility to add additional users with fewer privileges.
podman run \
--rm \
--entrypoint htpasswd \
docker.io/httpd:2.4 -Bbn admin admin > /home/kni/htpasswdLet's then create a secret with the admin's user credential
export KUBECONFIG=~/manifests/auth/kubeconfig
oc create secret generic htpasswd-secret \
--from-file=htpasswd=/home/kni/htpasswd \
-n openshift-configWe're now going to create a config file for OAuth where we say to use HTPasswd as another Identity Provider and to take the htpasswd file from the secret. Follows my working file
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: ocp4.bm.nfv.io
mappingMethod: claim
type: HTPasswd
htpasswd:
fileData:
name: htpasswd-secretThen, as usual, let's apply it and then grant role cluster-admin and registry-editor to the admin user.
oc apply -f <path/to/oauth/yaml>`
oc adm policy add-cluster-role-to-user cluster-admin admin
oc policy add-role-to-user registry-editor adminLast step, let's first test the new login credentials and IF SUCCESFUL delete the kubeadmin user
unset KUBECONFIG
oc login https://api.ocp4.bm.nfv.io:6443 \
--username=admin --password=admin \
--insecure-skip-tls-verify=true
oc delete secrets kubeadmin -n kube-system --ignore-not-found=trueIt's time to connect to the OpenShift Console. The router already allows the communication both ways. Simply add a static route and also use the router as your DNS.

Now let's add some real physical nodes to the cluster. It's important to create a new MachineSet in this way, we have a clear demarcation mark between real physical nodes and virtual ones. This is gonna be instrumental later on for PAO. Happening through the hostSelector.matchLabels who looks for node-role.kubernetes.io/worker-cnf
Follows a sample MachineSet template to later manage real baremetal nodes. I'm calling it worker-cnf. Be aware, you will need to customize:
- RHCOS image URL
spec.template.spec.providerSpec.value.url - RHCOS image checksum
spec.template.spec.providerSpec.value.checksum - The infrastructure_id
Follows a handy script that does everything
_URL="$(oc get MachineSet -n openshift-machine-api -o jsonpath='{.items[0].spec.template.spec.providerSpec.value.image.url}')"
_CHECKSUM="$(oc get MachineSet -n openshift-machine-api -o jsonpath='{.items[0].spec.template.spec.providerSpec.value.image.checksum}')"
_INFRAID="$(oc get Infrastructure cluster -o jsonpath='{.status.infrastructureName}')"
cat > ~/worker-cnf_machineSet.yaml << EOF
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: ${_INFRAID}
name: ${_INFRAID}-worker-cnf
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: ${_INFRAID}
machine.openshift.io/cluster-api-machineset: ${_INFRAID}-worker-cnf
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: ${_INFRAID}
machine.openshift.io/cluster-api-machine-role: worker-cnf
machine.openshift.io/cluster-api-machine-type: worker-cnf
machine.openshift.io/cluster-api-machineset: ${_INFRAID}-worker-cnf
spec:
taints:
- effect: NoSchedule
key: node-function
value: cnf
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/worker-cnf: ""
providerSpec:
value:
apiVersion: baremetal.cluster.k8s.io/v1alpha1
kind: BareMetalMachineProviderSpec
hostSelector:
matchLabels:
node-role.kubernetes.io/worker-cnf: ""
image:
checksum: >-
${_CHECKSUM}
url: >-
${_URL}
metadata:
creationTimestamp: null
userData:
name: worker-user-data
EOFThe template can be deployed with a simple oc apply -f <path/to/machine/set/yaml> (BTW, about create vs. apply).
Once that's done, we can also provision a new node, follows again a sample template. Ensure the same labels between the MachineSet's hostSelector.matchLabels and metadata.labels here. Same goes for the authentication credentails and the mac-address.
One additional comment, instead of going for a traditional deployment, you could opt for Virtual Media. If you do that, you need to have both ways IP connectivity between the Metal3 and the BMC device
- The
Ironic-Conductorin Metal3 needs to speak with the BMC over RedFish for power management, set the boot device, and configure the virtual media - The BMC device needs to reach the
httpdMetal3 container (clusterProvisioningIPon port6180/TCP) to mount the RHCOS ISO
---
apiVersion: v1
kind: Secret
metadata:
name: openshift-worker-cnf-1-bmc-secret
namespace: openshift-machine-api
type: Opaque
data:
username: cm9vdA==
password: Y2Fsdmlu
---
apiVersion: metal3.io/v1alpha1
kind: BareMetalHost
metadata:
name: openshift-worker-cnf-1
namespace: openshift-machine-api
labels:
node-role.kubernetes.io/worker-cnf: ""
spec:
online: true
bootMACAddress: ec:f4:bb:dd:96:28
bmc:
address: redfish://192.168.178.232/redfish/v1/Systems/System.Embedded.1
credentialsName: openshift-worker-cnf-1-bmc-secret
disableCertificateVerification: TrueAlso this time an oc apply -f <path/to/node/yaml> gets the job done.
To check the status use oc get BareMetalHost -n openshift-machine-api once it goes into provisioning's state ready, the MachineSet will automatically enroll it.

This is how it looks once all done

At this point we should have an OCP cluster up and running and is the perfect time to verify the platform is fully Jumbo Frames.
First, let's check the Network CRD
$ oc describe network cluster
Name: cluster
Namespace:
Labels: <none>
Annotations: <none>
API Version: config.openshift.io/v1
Kind: Network
Metadata:
Creation Timestamp: 2021-04-17T07:21:41Z
Generation: 2
Managed Fields:
<SNIP>
Spec:
Cluster Network:
Cidr: 10.128.0.0/14
Host Prefix: 23
External IP:
Policy:
Network Type: OVNKubernetes
Service Network:
172.30.0.0/16
Status:
Cluster Network:
Cidr: 10.128.0.0/14
Host Prefix: 23
Cluster Network MTU: 8900
Network Type: OVNKubernetes
Service Network:
172.30.0.0/16
Events: <none>Then let's check a master node and our CNF worker node status
$ oc debug node/openshift-master-0 -- chroot /host ip link show ens192
3: ens192: <BROADCAST,MULTICAST,ALLMULTI,UP,LOWER_UP> mtu 9000 qdisc mq master ovs-system state UP mode DEFAULT group default qlen 1000
link/ether 00:50:56:8e:56:31 brd ff:ff:ff:ff:ff:ff
$ oc debug node/openshift-master-0 -- chroot /host ovs-vsctl get interface br-ex mtu
9000
$ oc debug node/openshift-worker-cnf-1 -- chroot /host ip link show eno2
3: eno2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq master ovs-system state UP mode DEFAULT group default qlen 1000
link/ether ec:f4:bb:dd:96:29 brd ff:ff:ff:ff:ff:ff
$ oc debug node/openshift-worker-cnf-1 -- chroot /host ovs-vsctl get interface br-ex mtu
9000Next step is to lavarage the RHEL NFS Server for persistent storage. Luckly this is uber easy (don't forget to install the helm CLI). See the official documentation for all the supported options by the Helm Chart (such as storageClass.accessModes, nfs.mountOptions, storageClass.reclaimPolicy, etc)
- Create the
nfs-external-provisionernamespace - Grant the Service Accounts
nfs-subdir-external-provisionerwith thehostmount-anyuidrole - Add NFS SIG Repo in Helm
- Install the NFS SIG
_NAMESPACE="nfs-external-provisioner"
oc new-project ${_NAMESPACE}
oc adm policy add-scc-to-user hostmount-anyuid \
-n ${_NAMESPACE} \
-z nfs-subdir-external-provisioner
helm repo add nfs-subdir-external-provisioner \
https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner/
helm install nfs-subdir-external-provisioner \
nfs-subdir-external-provisioner/nfs-subdir-external-provisioner \
--set nfs.server=nfs-server \
--set nfs.path=/nfs \
--set storageClass.defaultClass=true \
--namespace ${_NAMESPACE}If both your NFS Server supports NConnect (CentOS 8 Stream does) and you use minimum OCP 4.7 (which includes the RHEL 8.3 NFS client bits), you can also add the following to the helm install command and enjoy much higher NFS speeds
--set nfs.mountOptions="{nconnect=16}"To verify the result, check the events and verify that the nfs-subdir-external-provisioner Pod is running
# oc get events -n nfs-external-provisioner --sort-by='lastTimestamp'
LAST SEEN TYPE REASON OBJECT MESSAGE
59s Normal CreatedSCCRanges namespace/nfs-external-provisioner created SCC ranges
57s Normal Scheduled pod/nfs-subdir-external-provisioner-7b75766446-6cmdc Successfully assigned nfs-external-provisioner/nfs-subdir-external-provisioner-7b75766446-6cmdc to openshift-worker-1
57s Normal SuccessfulCreate replicaset/nfs-subdir-external-provisioner-7b75766446 Created pod: nfs-subdir-external-provisioner-7b75766446-6cmdc
57s Normal ScalingReplicaSet deployment/nfs-subdir-external-provisioner Scaled up replica set nfs-subdir-external-provisioner-7b75766446 to 1
54s Normal LeaderElection endpoints/cluster.local-nfs-subdir-external-provisioner nfs-subdir-external-provisioner-7b75766446-6cmdc_b5caecc3-df22-4e69-b621-f73689aa1974 became leader
54s Normal AddedInterface pod/nfs-subdir-external-provisioner-7b75766446-6cmdc Add eth0 [10.131.0.29/23]
54s Normal Pulled pod/nfs-subdir-external-provisioner-7b75766446-6cmdc Container image "gcr.io/k8s-staging-sig-storage/nfs-subdir-external-provisioner:v4.0.0" already present on machine
54s Normal Created pod/nfs-subdir-external-provisioner-7b75766446-6cmdc Created container nfs-subdir-external-provisioner
54s Normal Started pod/nfs-subdir-external-provisioner-7b75766446-6cmdc Started container nfs-subdir-external-provisioner
# oc get all -n nfs-external-provisioner
NAME READY STATUS RESTARTS AGE
pod/nfs-subdir-external-provisioner-7b75766446-6cmdc 1/1 Running 0 58s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nfs-subdir-external-provisioner 1/1 1 1 58s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nfs-subdir-external-provisioner-7b75766446 1 1 1 58sInstalling the NFS Storage Class was very easy, now let's ensure the internal OCP Registry will user it
- Set the Registry status as
managed - Define the storage to claim a PVC (and by default the system will make a claim from the default
StorageClass) - Expose the Registry to the outside
oc patch configs.imageregistry.operator.openshift.io/cluster --type merge --patch '{"spec":{"managementState":"Managed"}}'
oc patch configs.imageregistry.operator.openshift.io/cluster --type merge --patch '{"spec":{"storage":{"pvc":{"claim":""}}}}'
oc patch configs.imageregistry.operator.openshift.io/cluster --type merge -p '{"spec":{"defaultRoute":true}}'
oc get pvc -n openshift-image-registryLet's check the status, first logging in to the registry and then pushing an alpine
_HOST=$(oc get route default-route -n openshift-image-registry --template='{{ .spec.host }}')
sudo podman login -u $(oc whoami) -p $(oc whoami -t) --tls-verify=false ${_HOST}
sudo podman image pull docker.io/library/alpine:latest
sudo podman image tag docker.io/library/alpine:latest ${_HOST}/default/alpine:latest
sudo podman image push ${_HOST}/default/alpine:latest --tls-verify=false
sudo podman search ${_HOST}/ --tls-verify=falseSomething currently missing in OpenShift Baremetal is a Service type LoadBalancer. We're going to use MetalLB here. In this initial release, the focus is L2 and BGP will follow later. On Medium you can find a simple yet effective description of all K8s service types.
So we're gonna do the following:
- Create the
metallb-systemnamespace - Grant SCC
privilagedstatus for bothspeakerandcontrollerServiceAccounts in themetallb-systemnamespace - Deploy MetalLB
- Generate a
genericsecret key that the speak will later use
_VER="v0.9.6"
oc create -f https://raw.githubusercontent.com/metallb/metallb/${_VER}/manifests/namespace.yaml
oc adm policy add-scc-to-user privileged \
-n metallb-system \
-z speaker \
-z controller
oc create -f https://raw.githubusercontent.com/metallb/metallb/${_VER}/manifests/metallb.yaml
oc create secret generic memberlist \
-n metallb-system \
--from-literal=secretkey="$(openssl rand -base64 128)"Once done, we need to write the MetalLB L2 configuration (BGP will be covered in a future update of this document). In my lab, I've dedicated these 5 IPs from the Baremetal Network range.
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 10.0.11.20-10.0.11.24As usual oc create -f <path/to/meltallb/config/yaml> and the MetalLB configuration is done.
To prove that the setup is working, let's deploy a simple HelloWorld.
git clone https://github.com/paulbouwer/hello-kubernetes
helm install --create-namespace \
--namespace hello-kubernetes \
hello-world \
~/hello-kubernetes/deploy/helm/hello-kubernetes/Let's verify the Deployment, Pods, and Service
oc project hello-kubernetes
helm list --all
oc get deployment,pods,servicesWith my Baremetal network, I have the following output
$ helm list --all
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
hello-world hello-kubernetes 1 2021-04-16 15:32:11.344953691 +0000 UTC deployed hello-kubernetes-1.0.0 1.10
$ oc get deployment,pods,services
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/hello-kubernetes-hello-world 2/2 2 2 5m13s
NAME READY STATUS RESTARTS AGE
pod/hello-kubernetes-hello-world-74dd85ddc4-4pvlm 1/1 Running 0 5m12s
pod/hello-kubernetes-hello-world-74dd85ddc4-fblls 1/1 Running 0 5m12s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/hello-kubernetes-hello-world LoadBalancer 172.30.52.210 10.0.11.20 80:30960/TCP 5m13sConnecting to the LoadBalancer External-IP, the HelloWorld should be available.

Let's now ensure the Pods will be running on the worker-cnf node. First let's change the tolerations matching the taints. This can be done using the patch command over the deployment command or directly editing it
oc patch deployment hello-kubernetes -p '{
"spec": {
"template": {
"spec": {
"tolerations": [
{
"key": "node-function",
"operator": "Equal",
"value": "cnf"
}
]
}
}
}
}'Now, this is a bit ugly, but to have all 3 Pods on the same node, we've gotta define a nodeAffinity to the worker hostname.
oc patch deployment hello-kubernetes -p '{
"spec": {
"template": {
"spec": {
"affinity": {
"nodeAffinity": {
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{
"matchExpressions": [
{
"key": "node-role.kubernetes.io/worker-cnf",
"operator": "In",
"values": [
""
]
}
]
}
]
}
}
}
}
}
}
}'The Pods are now all running on the same Worker node.
oc get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hello-kubernetes-5cb945f5f5-8g74v 1/1 Running 0 4m24s 10.130.2.9 openshift-worker-cnf-1 <none> <none>
hello-kubernetes-5cb945f5f5-94vqx 1/1 Running 0 4m27s 10.130.2.8 openshift-worker-cnf-1 <none> <none>
hello-kubernetes-5cb945f5f5-t52hc 1/1 Running 0 4m31s 10.130.2.7 openshift-worker-cnf-1 <none> <none>Reaching this point wasn't that easy :-) Assuming everything went well, now our OCP cluster is deployed with at least one physical worker node and we can start taking care of the PAO which is fundamental for any deterministic workloads
To deploy PAO effectively we need to do three things:
- Install the
performance-addon-operatorfrom OperatorHub - Deploy a
MachineConfigPoolwith theworker-cnfnodeSelector - Deploy a
PerformanceProfilestill using theworker-cnfnodeSelector
For more details check out the official OpenShift documentation. For more details, there is also another extremely good deep-dive on Medium.
Let's create the following YAML containing the basic steps to install PAO from OperatorHub
- Create the
openshift-performance-addon-operatornamespace - Define the PAO Operator
- Subscribe to the 4.7 PAO channel with consequential installation of the CRDs
To apply, as usual, oc create -f <path/to/pao/install/yaml>
apiVersion: v1
kind: Namespace
metadata:
name: openshift-performance-addon-operator
labels:
openshift.io/run-level: "1"
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: openshift-performance-addon-operator
namespace: openshift-performance-addon-operator
---
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: openshift-performance-addon-operator-subscription
namespace: openshift-performance-addon-operator
spec:
channel: "4.7"
name: performance-addon-operator
source: redhat-operators
sourceNamespace: openshift-marketplaceNext, let's create the MachineConfigPool ensuring to match the worker-cnf nodeSelector.
In a production situation, dealing with different hardware type, you can replace worker-cnf with something more specific like embedding the hardware type/version/revision and/or the scope (which usually comes from the CNF requirements)
To apply, as usual, oc create -f <path/to/worker-cnf/mcp/yaml>
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfigPool
metadata:
name: worker-cnf
labels:
machineconfiguration.openshift.io/role: worker-cnf
spec:
machineConfigSelector:
matchExpressions:
- {
key: machineconfiguration.openshift.io/role,
operator: In,
values: [worker-cnf, worker]
}
paused: false
nodeSelector:
matchLabels:
node-role.kubernetes.io/worker-cnf: ""Now, the last step is to deploy PAO on our worker-cnf node. The following template is very specific for my hardware. You shouldn't just copy it but instead create a system partitioning design.
In my case, as good practice, the first full physical core per NUMA node is available to Kernel, hardware interrupts, and any userland/housekeeper components while all the others are fully isolated and reserved for my deterministic and high-performance workloads.
Memory wise, same story, a portion of the memory is available to kernel, userland/housekeeper component, and for any running Pods while the majority available for my workloads in form of 1GB hugepages. Out of 64GB of memory (32GB per NUMA), 48 are pre-allocated in HugePages.
Fun fact HugePages must be allocated at boot time prior to the Linux kernel is initiated otherwise the memory gets fragmented and:
- It's not possible to allocate the maximum value of HugePages
- As a result of the fragmentation, the memory is not anymore continuous and the deterministic aspects are affected
To apply, as usual, oc create -f <path/to/pao/worker-cnf/profile/yaml> and after a little bit the worker-cnf will reboot.
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: pao-worker-cnf
spec:
realTimeKernel:
enabled: false
globallyDisableIrqLoadBalancing: true
numa:
topologyPolicy: "single-numa-node"
cpu:
reserved: 0,1,24,25
isolated: 2-23,26-47
additionalKernelArgs:
- nmi_watchdog=0
- audit=0
- mce=off
- processor.max_cstate=1
- idle=poll
- intel_idle.max_cstate=0
- module_blacklist=ixgbevf,iavf
- default_hugepagesz=1G
- hugepagesz=1G
- hugepages=48
machineConfigPoolSelector:
machineconfiguration.openshift.io/role: worker-cnf
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""If you still want to deploy using the RT-Kernel, for example, when testing a radio vDU, set the flag (pre or even post PAO deployment) spec.realTimeKernel.enabled to true.
Additionally, you should really disable SMT with the RT-Kernel. You can do that using the nosmt facility in the Kernel command line. Doing so, make sure to exclude the sibling threads from both Reserved and Isolated CPU; otherwise, Kubelet will fail to start. It's worth pointing out that you should study the following content made by Frank Zdarsky (Red Hat) and Raymond Knopp (Eurecom) if you're after deterministic truly scheduling latency.
Build Your Own Private 5G Network on Kubernetes - Slides
To check the installation status
oc describe PerformanceProfile pao-worker-cnf
oc get MachineConfigPool worker-cnf -w
oc get Nodes openshift-worker-cnf-1 -wOnce is done, connect to the worker-cnf node and check
- The
GRUBcmdline - The
Tunedprofile - The
KubeletCPU reserved core and CPU Manager configuration
# cat /proc/cmdline
BOOT_IMAGE=(hd0,gpt3)/ostree/rhcos-8db996458745a61fa6759e8612cc44d429af0417584807411e38b991b9bcedb9/vmlinuz-4.18.0-240.10.1.el8_3.x86_64 random.trust_cpu=on console=tty0 console=ttyS0,115200n8 ostree=/ostree/boot.1/rhcos/8db996458745a61fa6759e8612cc44d429af0417584807411e38b991b9bcedb9/0 ignition.platform.id=openstack root=UUID=a72ff11d-83fc-4ebe-a8fe-b7de1817dbf9 rw rootflags=prjquota skew_tick=1 nohz=on rcu_nocbs=2-23,26-47 tuned.non_isolcpus=03000003 intel_pstate=disable nosoftlockup tsc=nowatchdog intel_iommu=on iommu=pt isolcpus=managed_irq,2-23,26-47 systemd.cpu_affinity=0,1,24,25 + nmi_watchdog=0 audit=0 mce=off processor.max_cstate=1 idle=poll intel_idle.max_cstate=0 module_blacklist=ixgbevf,iavf default_hugepagesz=1G hugepagesz=1G hugepages=48
# crictl exec -it $(crictl ps --quiet --name tuned) tuned-adm active
Current active profile: openshift-node-performance-pao-worker-cnf
# cat /etc/kubernetes/kubelet.conf | grep -E "reservedSystemCPUs|cpuManager"
"reservedSystemCPUs": "0,1,24,25",
"cpuManagerPolicy": "static",
"cpuManagerReconcilePeriod": "5s",If you also want to verify the fixed CPU clock speed, let's first create a little awk program
cat > /root/checkClock.sh << 'EOF'
cat /proc/cpuinfo | awk '/processor/{CPU=$3; next} /^[c]pu MHz/{print "CPU"CPU " -> " $4" MHz"}'
EOFAnd then execute it
watch -n.1 -d bash /root/checkClock.shHere you have a correctly tuned system on the left and then a untuned system on the right.
CPU0 -> 2900.285 MHz | CPU0 -> 1308.149 MHz
CPU1 -> 2900.285 MHz | CPU1 -> 3100.653 MHz
CPU2 -> 2900.285 MHz | CPU2 -> 2115.782 MHz
CPU3 -> 2900.284 MHz | CPU3 -> 2968.766 MHz
CPU4 -> 2900.284 MHz | CPU4 -> 1892.121 MHz
CPU5 -> 2900.285 MHz | CPU5 -> 1732.151 MHz
CPU6 -> 2900.285 MHz | CPU6 -> 1698.550 MHz
CPU7 -> 2900.285 MHz | CPU7 -> 2900.237 MHz
CPU8 -> 2900.285 MHz | CPU8 -> 1678.674 MHz
CPU9 -> 2900.286 MHz | CPU9 -> 2903.886 MHz
CPU10 -> 2900.285 MHz | CPU10 -> 1913.110 MHz
CPU11 -> 2900.285 MHz | CPU11 -> 2901.674 MHz
CPU12 -> 2900.285 MHz | CPU12 -> 2901.752 MHz
CPU13 -> 2900.285 MHz | CPU13 -> 2904.997 MHz
CPU14 -> 2900.285 MHz | CPU14 -> 2191.431 MHz
CPU15 -> 2900.285 MHz | CPU15 -> 2900.850 MHz
CPU16 -> 2900.285 MHz | CPU16 -> 1791.175 MHz
CPU17 -> 2900.284 MHz | CPU17 -> 1915.617 MHz
CPU18 -> 2900.285 MHz | CPU18 -> 2914.917 MHz
CPU19 -> 2900.285 MHz | CPU19 -> 2915.453 MHz
CPU20 -> 2900.285 MHz | CPU20 -> 1638.926 MHz
CPU21 -> 2900.285 MHz | CPU21 -> 2929.577 MHz
CPU22 -> 2900.284 MHz | CPU22 -> 2953.707 MHz
CPU23 -> 2900.284 MHz | CPU23 -> 2959.193 MHz
CPU24 -> 2900.285 MHz | CPU24 -> 2018.582 MHz
CPU25 -> 2900.284 MHz | CPU25 -> 2909.077 MHz
CPU26 -> 2900.284 MHz | CPU26 -> 2808.746 MHz
CPU27 -> 2900.286 MHz | CPU27 -> 2922.110 MHz
CPU28 -> 2900.284 MHz | CPU28 -> 2524.442 MHz
CPU29 -> 2900.285 MHz | CPU29 -> 2738.436 MHz
CPU30 -> 2900.285 MHz | CPU30 -> 1812.347 MHz
CPU31 -> 2900.283 MHz | CPU31 -> 2906.919 MHz
CPU32 -> 2900.286 MHz | CPU32 -> 1380.267 MHz
CPU33 -> 2900.283 MHz | CPU33 -> 2913.820 MHz
CPU34 -> 2900.286 MHz | CPU34 -> 1314.901 MHz
CPU35 -> 2900.286 MHz | CPU35 -> 2905.483 MHz
CPU36 -> 2900.286 MHz | CPU36 -> 2906.041 MHz
CPU37 -> 2900.286 MHz | CPU37 -> 2905.755 MHz
CPU38 -> 2900.285 MHz | CPU38 -> 1338.634 MHz
CPU39 -> 2900.284 MHz | CPU39 -> 2900.354 MHz
CPU40 -> 2900.285 MHz | CPU40 -> 2645.661 MHz
CPU41 -> 2900.286 MHz | CPU41 -> 1968.130 MHz
CPU42 -> 2900.284 MHz | CPU42 -> 2822.730 MHz
CPU43 -> 2900.284 MHz | CPU43 -> 2918.735 MHz
CPU44 -> 2900.284 MHz | CPU44 -> 1596.694 MHz
CPU45 -> 2900.285 MHz | CPU45 -> 2932.137 MHz
CPU46 -> 2900.286 MHz | CPU46 -> 2953.630 MHz
CPU47 -> 2900.285 MHz | CPU47 -> 2957.103 MHzFor more hardware details, assuming you have an Intel platform, you best weapon is Intel PCM. You can run it using the handy debug facility
oc debug node/openshift-worker-cnf-1 --image=docker.io/opcm/pcmThe Pod has all PCM tools pre-compiled and available. Follows a simple example of pcm.x

You should also check the worker-cnf node from Kubernetes
# oc get KubeletConfig performance-pao-worker-cnf -o yaml|grep -E "reservedSystemCPUs|cpuManager"
cpuManagerPolicy: static
cpuManagerReconcilePeriod: 5s
reservedSystemCPUs: 0,1,24,25
# oc describe Nodes openshift-worker-cnf-1
Name: openshift-worker-cnf-1
Roles: worker,worker-cnf
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=openshift-worker-cnf-1
kubernetes.io/os=linux
node-role.kubernetes.io/worker=
node-role.kubernetes.io/worker-cnf=
node.openshift.io/os_id=rhcos
Annotations: k8s.ovn.org/l3-gateway-config:
{"default":{"mode":"shared","interface-id":"br-ex_openshift-worker-cnf-1","mac-address":"ec:f4:bb:dd:96:29","ip-addresses":["10.0.11.11/27...
k8s.ovn.org/node-chassis-id: 820d2830-c9f3-4f0d-935c-9b4dc4e62a72
k8s.ovn.org/node-local-nat-ip: {"default":["169.254.11.201"]}
k8s.ovn.org/node-mgmt-port-mac-address: a2:98:40:ee:66:40
k8s.ovn.org/node-primary-ifaddr: {"ipv4":"10.0.11.11/27"}
k8s.ovn.org/node-subnets: {"default":"10.128.4.0/23"}
machine.openshift.io/machine: openshift-machine-api/ocp4-d2xs7-worker-cnf-ql878
machineconfiguration.openshift.io/currentConfig: rendered-worker-cnf-592ebb59803b8d407a8c243f37f1b1d6
machineconfiguration.openshift.io/desiredConfig: rendered-worker-cnf-592ebb59803b8d407a8c243f37f1b1d6
machineconfiguration.openshift.io/reason:
machineconfiguration.openshift.io/ssh: accessed
machineconfiguration.openshift.io/state: Done
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Fri, 05 Mar 2021 19:21:39 +0000
Taints: node-function=cnf:NoSchedule
Unschedulable: false
Lease:
HolderIdentity: openshift-worker-cnf-1
AcquireTime: <unset>
RenewTime: Fri, 05 Mar 2021 19:42:33 +0000
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Fri, 05 Mar 2021 19:39:53 +0000 Fri, 05 Mar 2021 19:29:52 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Fri, 05 Mar 2021 19:39:53 +0000 Fri, 05 Mar 2021 19:29:52 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Fri, 05 Mar 2021 19:39:53 +0000 Fri, 05 Mar 2021 19:29:52 +0000 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Fri, 05 Mar 2021 19:39:53 +0000 Fri, 05 Mar 2021 19:29:52 +0000 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 10.0.11.11
Hostname: openshift-worker-cnf-1
Capacity:
cpu: 48
ephemeral-storage: 113886Mi
hugepages-1Gi: 48Gi
hugepages-2Mi: 0
memory: 65843552Ki
pods: 250
Allocatable:
cpu: 44
ephemeral-storage: 106402571701
hugepages-1Gi: 48Gi
hugepages-2Mi: 0
memory: 5996896Ki
pods: 250
System Info:
Machine ID: e9e370f19d5c4b97a8ad553801e71ae2
System UUID: 4c4c4544-0032-3610-8056-b1c04f4d3632
Boot ID: 44a99d25-ce0a-4846-96c3-4662e7ea56ee
Kernel Version: 4.18.0-240.10.1.el8_3.x86_64
OS Image: Red Hat Enterprise Linux CoreOS 47.83.202102090044-0 (Ootpa)
Operating System: linux
Architecture: amd64
Container Runtime Version: cri-o://1.20.0-0.rhaos4.7.git8921e00.el8.51
Kubelet Version: v1.20.0+ba45583
Kube-Proxy Version: v1.20.0+ba45583
ProviderID: baremetalhost:///openshift-machine-api/openshift-worker-cnf-1/f8bc8086-7488-4d65-8152-06185737cbab
Non-terminated Pods: (13 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
openshift-cluster-node-tuning-operator tuned-gdh25 10m (0%) 0 (0%) 50Mi (0%) 0 (0%) 21m
openshift-dns dns-default-dt92d 65m (0%) 0 (0%) 131Mi (2%) 0 (0%) 21m
openshift-image-registry node-ca-vdcdb 10m (0%) 0 (0%) 10Mi (0%) 0 (0%) 21m
openshift-kni-infra coredns-openshift-worker-cnf-1 200m (0%) 0 (0%) 400Mi (6%) 0 (0%) 19m
openshift-kni-infra keepalived-openshift-worker-cnf-1 200m (0%) 0 (0%) 400Mi (6%) 0 (0%) 20m
openshift-kni-infra mdns-publisher-openshift-worker-cnf-1 100m (0%) 0 (0%) 200Mi (3%) 0 (0%) 20m
openshift-machine-config-operator machine-config-daemon-q64fc 40m (0%) 0 (0%) 100Mi (1%) 0 (0%) 21m
openshift-monitoring node-exporter-bqv5b 9m (0%) 0 (0%) 210Mi (3%) 0 (0%) 21m
openshift-multus multus-9dlg4 10m (0%) 0 (0%) 150Mi (2%) 0 (0%) 21m
openshift-multus network-metrics-daemon-5r4b8 20m (0%) 0 (0%) 120Mi (2%) 0 (0%) 21m
openshift-network-diagnostics network-check-target-6bjw4 10m (0%) 0 (0%) 15Mi (0%) 0 (0%) 21m
openshift-ovn-kubernetes ovnkube-node-gxpd8 30m (0%) 0 (0%) 620Mi (10%) 0 (0%) 21m
openshift-ovn-kubernetes ovs-node-hcmcb 15m (0%) 0 (0%) 300Mi (5%) 0 (0%) 21m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 719m (1%) 0 (0%)
memory 2706Mi (46%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodeNotSchedulable 174m kubelet Node openshift-worker-cnf-1 status is now: NodeNotSchedulable
Normal Starting 169m kubelet Starting kubelet.
Normal NodeHasSufficientPID 169m (x7 over 169m) kubelet Node openshift-worker-cnf-1 status is now: NodeHasSufficientPID
Normal NodeAllocatableEnforced 169m kubelet Updated Node Allocatable limit across pods
Normal NodeHasSufficientMemory 169m (x8 over 169m) kubelet Node openshift-worker-cnf-1 status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 169m (x8 over 169m) kubelet Node openshift-worker-cnf-1 status is now: NodeHasNoDiskPressure
Normal NodeNotSchedulable 61m kubelet Node openshift-worker-cnf-1 status is now: NodeNotSchedulable
Normal NodeNotSchedulable 16m kubelet Node openshift-worker-cnf-1 status is now: NodeNotSchedulable
Normal Starting 13m kubelet Starting kubelet.
Normal NodeHasSufficientPID 13m (x7 over 13m) kubelet Node openshift-worker-cnf-1 status is now: NodeHasSufficientPID
Normal NodeAllocatableEnforced 13m kubelet Updated Node Allocatable limit across pods
Normal NodeHasSufficientMemory 13m (x8 over 13m) kubelet Node openshift-worker-cnf-1 status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 13m (x8 over 13m) kubelet Node openshift-worker-cnf-1 status is now: NodeHasNoDiskPressureFollows a couple of logs with an early PAO profile about the HugePages fragmentation I talked above define through the spec.hugepages
hugepages:
defaultHugepagesSize: 1G
pages:
- count: 28
node: 0
size: 1G
- count: 28
node: 1
size: 1GThis is even the Red Hat way described in the documentation, but as usual, blindly following the documentation like a monkey ain't any good :-P
# journalctl -u hugepages-allocation-1048576kB-NUMA0.service -u hugepages-allocation-1048576kB-NUMA1.service
Mar 05 16:57:46 localhost systemd[1]: Starting Hugepages-1048576kB allocation on the node 0...
Mar 05 16:57:46 localhost systemd[1]: Starting Hugepages-1048576kB allocation on the node 1...
Mar 05 16:58:47 localhost.localdomain hugepages-allocation.sh[1836]: ERROR: /sys/devices/system/node/node0/hugepages/hugepages-1048576kB/nr_hugepages does not have the expected number of hugepages 28
Mar 05 16:58:47 localhost.localdomain hugepages-allocation.sh[1951]: ERROR: /sys/devices/system/node/node1/hugepages/hugepages-1048576kB/nr_hugepages does not have the expected number of hugepages 28
Mar 05 16:58:47 localhost.localdomain systemd[1]: hugepages-allocation-1048576kB-NUMA0.service: Main process exited, code=exited, status=1/FAILURE
Mar 05 16:58:47 localhost.localdomain systemd[1]: hugepages-allocation-1048576kB-NUMA0.service: Failed with result 'exit-code'.
Mar 05 16:58:47 localhost.localdomain systemd[1]: hugepages-allocation-1048576kB-NUMA1.service: Main process exited, code=exited, status=1/FAILURE
Mar 05 16:58:47 localhost.localdomain systemd[1]: hugepages-allocation-1048576kB-NUMA1.service: Failed with result 'exit-code'.
Mar 05 16:58:47 localhost.localdomain systemd[1]: Failed to start Hugepages-1048576kB allocation on the node 0.
Mar 05 16:58:47 localhost.localdomain systemd[1]: Failed to start Hugepages-1048576kB allocation on the node 1.
# tail /sys/devices/system/node/node*/hugepages/hugepages-1048576kB/*
==> /sys/devices/system/node/node0/hugepages/hugepages-1048576kB/free_hugepages <==
20
==> /sys/devices/system/node/node0/hugepages/hugepages-1048576kB/nr_hugepages <==
20
==> /sys/devices/system/node/node0/hugepages/hugepages-1048576kB/surplus_hugepages <==
0
==> /sys/devices/system/node/node1/hugepages/hugepages-1048576kB/free_hugepages <==
24
==> /sys/devices/system/node/node1/hugepages/hugepages-1048576kB/nr_hugepages <==
24
==> /sys/devices/system/node/node1/hugepages/hugepages-1048576kB/surplus_hugepages <==
0
# free -h
total used free shared buff/cache available
Mem: 62Gi 45Gi 16Gi 2.0Mi 257Mi 16Gi
Swap: 0B 0B 0BNext let's load a few kernel modules:
sctpwhich stand for Stream Control Transmission Protocol is actually heavily used in 5G for signalingxt_u32to allow dynamic inspection of message payloads. See the upstream commit for more information
To have this modules loaded, we can use MCO (MachineConfigOperator). Ensure to match the correct label.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker-cnf
name: load-sctp-modules
spec:
config:
ignition:
version: 3.1.0
storage:
files:
- contents:
source: data:,
mode: 420
overwrite: true
path: /etc/modprobe.d/sctp-blacklist.conf
- contents:
source: data:,
mode: 420
overwrite: true
path: /etc/modprobe.d/sctp_diag-blacklist.conf
- contents:
source: data:text/plain;charset=utf-8,sctp
mode: 420
overwrite: true
path: /etc/modules-load.d/sctp-load.conf
- contents:
source: data:text/plain;charset=utf-8,sctp_diag
mode: 420
overwrite: true
path: /etc/modules-load.d/sctp_diag-load.conf
---
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker-cnf
name: load-xt-u32-module
spec:
config:
ignition:
version: 3.1.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8,xt_u32
mode: 420
overwrite: true
path: /etc/modules-load.d/xt_u32-load.confTo apply, as usual, oc create -f <path/to/module/load/yaml> and after a little bit the worker-cnf will reboot.
To verify the status, upon reboot you can simply use lsmod.
# lsmod | grep -E "xt_u32|sctp"
xt_u32 16384 0
sctp_diag 16384 0
inet_diag 24576 1 sctp_diag
sctp 405504 3 sctp_diag
libcrc32c 16384 5 nf_conntrack,nf_nat,openvswitch,xfs,sctpFrom OCP 4.7 we have NMState Operator which is instrumental to configure the network interfaces (as the name suggests, is NetworkManager driven).
If you are on an older/different version, you can always consume upstream bits (don't forget to deploy the SCC too).
In the near future, NMState will also manage the Link Aggregation with OVN-Kubernetes, but for the time being, this won't be possible :-(
Meanwhile NMState and OCP get ready, check-out the network-bonding folder to have a workaround.
The high-level process for NMState is as following
- Create a namespace for the NMState operator
- Install the
openshift-nmstatefrom OperatorHub - Deploy a NMState instance to collect all the networking details
- Patch the
DaemonSetto have NMState running also on the worker-cnf node
So going low-level, let's create the following YAML containing the basic steps to install NMState from OperatorHub
- Create the
openshift-nmstatenamespaces - Define the NMState Operator
- Subscribe to NMState Operator in the 4.7 channel with the consequential installation of the CRDs
To apply, as usual, oc create -f <path/to/sriov/install/yaml>
apiVersion: v1
kind: Namespace
metadata:
name: openshift-nmstate
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: nmstate-operator
namespace: openshift-nmstate
spec:
targetNamespaces:
- kubernetes-nmstate-operator
---
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: nmstate-operator-subsription
namespace: openshift-nmstate
spec:
channel: "4.7"
name: kubernetes-nmstate-operator
source: redhat-operators
sourceNamespace: openshift-marketplaceTo verify the result, you can use the CLI ...
$ oc get ClusterServiceVersions -n openshift-nmstate
NAME DISPLAY VERSION REPLACES PHASE
kubernetes-nmstate-operator.v4.7.0 Kubernetes NMState Operator 4.7.0-202102110027.p0 Succeeded... Or use the OpenShift Console :-)

At this point, let's conclude with NMState to have a global view of the cluster networking. Create the following instance
apiVersion: nmstate.io/v1beta1
kind: NMState
metadata:
name: nmstate
spec:
nodeSelector:
beta.kubernetes.io/arch: amd64Due to the taints on the worker-cnf node, NMState won't be installed there by default. The simplest option is patching the NMState DaemonSet.
oc patch -n openshift-nmstate DaemonSet nmstate-handler -p '{
"spec": {
"template": {
"spec": {
"tolerations": [{
"key": "node-role.kubernetes.io/master",
"operator": "Exists"
},
{
"key": "node-function",
"operator": "Equal",
"value": "cnf"
}
]
}
}
}
}'After a few seconds, NMState will be fully functional
# oc get NodeNetworkStates
NAME AGE
openshift-master-0 17m
openshift-master-1 17m
openshift-master-2 17m
openshift-worker-0 17m
openshift-worker-1 17m
openshift-worker-2 17m
openshift-worker-cnf-1 17mFollows an example inspecting the worker-cnf node
# oc get NodeNetworkStates openshift-worker-cnf-1 -o yaml
apiVersion: nmstate.io/v1beta1
kind: NodeNetworkState
metadata:
<SNIP>
name: openshift-worker-cnf-1
<SNIP>
status:
currentState:
dns-resolver:
config:
search: []
server: []
running:
search:
- ocp4.bm.nfv.io
server:
- 10.0.11.30
interfaces:
- ipv4:
enabled: false
ipv6:
enabled: false
lldp:
enabled: false
mac-address: 86:E8:20:DA:23:6D
mtu: 1400
name: 2735c4a3d86e4b5
state: down
type: ethernet
- bridge:
options:
fail-mode: ""
mcast-snooping-enable: false
rstp: false
stp: false
port:
- name: br-ex
- name: eno2
ipv4:
address:
- ip: 10.0.11.11
prefix-length: 27
auto-dns: true
auto-gateway: true
auto-routes: true
dhcp: true
enabled: true
ipv6:
address:
- ip: fe80::607:f388:b6ae:358f
prefix-length: 64
auto-dns: true
auto-gateway: true
auto-routes: true
autoconf: true
dhcp: true
enabled: true
lldp:
enabled: false
mac-address: EC:F4:BB:DD:96:29
mtu: 9000
name: br-ex
state: up
type: ovs-interface
- bridge: {}
ipv4:
enabled: false
ipv6:
enabled: false
lldp:
enabled: false
mac-address: E6:6C:88:AC:8F:11
mtu: 1400
name: br-int
state: down
type: ovs-interface
- bridge: {}
ipv4:
enabled: false
ipv6:
enabled: false
lldp:
enabled: false
mac-address: F2:E4:63:2C:30:44
mtu: 1400
name: br-local
state: down
type: ovs-interface
- ipv4:
enabled: false
ipv6:
enabled: false
lldp:
enabled: false
mac-address: 1E:1D:9F:95:40:33
mtu: 1400
name: defc676d6a60042
state: down
type: ethernet
- ethernet:
auto-negotiation: true
duplex: full
speed: 1000
sr-iov:
total-vfs: 0
vfs: []
ipv4:
address:
- ip: 10.0.10.9
prefix-length: 27
auto-dns: true
auto-gateway: true
auto-routes: true
dhcp: true
enabled: true
ipv6:
address:
- ip: fe80::e06e:652f:1874:1a8b
prefix-length: 64
auto-dns: true
auto-gateway: true
auto-routes: true
autoconf: true
dhcp: true
enabled: true
lldp:
enabled: false
mac-address: EC:F4:BB:DD:96:28
mtu: 1500
name: eno1
state: up
type: ethernet
- ethernet:
auto-negotiation: true
duplex: full
speed: 1000
sr-iov:
total-vfs: 0
vfs: []
ipv4:
dhcp: false
enabled: false
ipv6:
autoconf: false
dhcp: false
enabled: false
lldp:
enabled: false
mac-address: EC:F4:BB:DD:96:29
mtu: 9000
name: eno2
state: up
type: ethernet
- ethernet:
auto-negotiation: true
duplex: full
speed: 1000
sr-iov:
total-vfs: 0
vfs: []
ipv4:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
dhcp: true
enabled: true
ipv6:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
autoconf: true
dhcp: true
enabled: true
lldp:
enabled: false
mac-address: EC:F4:BB:DD:96:2A
mtu: 1500
name: eno3
state: up
type: ethernet
- ethernet:
auto-negotiation: true
duplex: full
speed: 1000
sr-iov:
total-vfs: 0
vfs: []
ipv4:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
dhcp: true
enabled: true
ipv6:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
autoconf: true
dhcp: true
enabled: true
lldp:
enabled: false
mac-address: EC:F4:BB:DD:96:2B
mtu: 1500
name: eno4
state: up
type: ethernet
- ethernet:
auto-negotiation: true
duplex: full
speed: 10000
sr-iov:
total-vfs: 0
vfs: []
ipv4:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
dhcp: true
enabled: true
ipv6:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
autoconf: true
dhcp: true
enabled: true
lldp:
enabled: false
mac-address: 0C:42:A1:40:08:B4
mtu: 1500
name: enp129s0f0
state: up
type: ethernet
- ethernet:
auto-negotiation: true
duplex: full
speed: 10000
sr-iov:
total-vfs: 0
vfs: []
ipv4:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
dhcp: true
enabled: true
ipv6:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
autoconf: true
dhcp: true
enabled: true
lldp:
enabled: false
mac-address: 0C:42:A1:40:08:B5
mtu: 1500
name: enp129s0f1
state: up
type: ethernet
- ethernet:
auto-negotiation: false
duplex: full
speed: 10000
sr-iov:
total-vfs: 0
vfs: []
ipv4:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
dhcp: true
enabled: true
ipv6:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
autoconf: true
dhcp: true
enabled: true
lldp:
enabled: false
mac-address: 40:A6:B7:05:BD:E0
mtu: 1500
name: enp131s0f0
state: up
type: ethernet
- ethernet:
auto-negotiation: false
duplex: full
speed: 10000
sr-iov:
total-vfs: 0
vfs: []
ipv4:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
dhcp: true
enabled: true
ipv6:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
autoconf: true
dhcp: true
enabled: true
lldp:
enabled: false
mac-address: 40:A6:B7:05:BD:E1
mtu: 1500
name: enp131s0f1
state: up
type: ethernet
- ethernet:
auto-negotiation: false
duplex: full
speed: 10000
sr-iov:
total-vfs: 0
vfs: []
ipv4:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
dhcp: true
enabled: true
ipv6:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
autoconf: true
dhcp: true
enabled: true
lldp:
enabled: false
mac-address: 90:E2:BA:7A:AB:3C
mtu: 1500
name: enp4s0f0
state: up
type: ethernet
- ethernet:
auto-negotiation: false
duplex: full
speed: 10000
sr-iov:
total-vfs: 0
vfs: []
ipv4:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
dhcp: true
enabled: true
ipv6:
address: []
auto-dns: true
auto-gateway: true
auto-routes: true
autoconf: true
dhcp: true
enabled: true
lldp:
enabled: false
mac-address: 90:E2:BA:7A:AB:3D
mtu: 1500
name: enp4s0f1
state: up
type: ethernet
- ipv4:
enabled: false
ipv6:
enabled: false
lldp:
enabled: false
mac-address: BE:CD:8C:8C:60:34
mtu: 1400
name: f5804b6f987188d
state: down
type: ethernet
- ipv4:
enabled: false
ipv6:
enabled: false
lldp:
enabled: false
mac-address: 46:BA:20:E3:F6:1D
mtu: 65000
name: genev_sys_6081
state: down
type: unknown
- ipv4:
address:
- ip: 169.254.0.2
prefix-length: 24
auto-dns: true
auto-gateway: true
auto-routes: true
dhcp: true
enabled: true
ipv6:
address:
- ip: fe80::98f2:d0e2:e66d:54b2
prefix-length: 64
auto-dns: true
auto-gateway: true
auto-routes: true
autoconf: true
dhcp: true
enabled: true
lldp:
enabled: false
mac-address: 74:E6:E2:FC:E3:0F
mtu: 1500
name: idrac
state: up
type: ethernet
- ipv4:
enabled: false
ipv6:
enabled: false
lldp:
enabled: false
mtu: 65536
name: lo
state: down
type: unknown
- ipv4:
enabled: false
ipv6:
enabled: false
lldp:
enabled: false
mac-address: 0A:58:A9:FE:00:01
mtu: 1400
name: ovn-k8s-gw0
state: down
type: ovs-interface
- ipv4:
enabled: false
ipv6:
enabled: false
lldp:
enabled: false
mac-address: 22:3B:31:E9:E8:19
mtu: 1400
name: ovn-k8s-mp0
state: down
type: ovs-interface
route-rules:
config: []
routes:
config: []
running:
- destination: 0.0.0.0/0
metric: 100
next-hop-address: 10.0.11.30
next-hop-interface: br-ex
table-id: 254
- destination: 10.0.11.0/27
metric: 100
next-hop-address: ""
next-hop-interface: br-ex
table-id: 254
- destination: 10.0.10.0/27
metric: 108
next-hop-address: ""
next-hop-interface: eno1
table-id: 254
- destination: 169.254.0.0/24
metric: 105
next-hop-address: ""
next-hop-interface: idrac
table-id: 254
- destination: fe80::/64
metric: 100
next-hop-address: ""
next-hop-interface: br-ex
table-id: 254
- destination: fe80::/64
metric: 108
next-hop-address: ""
next-hop-interface: eno1
table-id: 254
- destination: fe80::/64
metric: 105
next-hop-address: ""
next-hop-interface: idrac
table-id: 254
- destination: ff00::/8
metric: 256
next-hop-address: ""
next-hop-interface: br-ex
table-id: 255
- destination: ff00::/8
metric: 256
next-hop-address: ""
next-hop-interface: eno1
table-id: 255
- destination: ff00::/8
metric: 256
next-hop-address: ""
next-hop-interface: idrac
table-id: 255
lastSuccessfulUpdateTime: "2021-03-12T17:45:35Z"Well, NMState configuration is honestly single-liner. On the other hand, SR-IOV, is a bit more complex because it requires you to know the hardware. Let's get into it.
To have SR-IOV capability in the platform, we will follow a similar approach as we did for PAO and NMState. OpenShift comes with everything:
- SR-IOV Network Operator
- Multus which is pre-installed and pre-configured out of the box. Red Hat wrote an amazing "Demystifying Multus" blog post explaining all bits and pieces
The high-level process for SR-IOV is as following
- Create a namespace for the SR-IOV operator
- Install the
sriov-network-operatorsfrom OperatorHub - Disable the
admission controller webhook - Deploy the SR-IOV configuration for the
worker-cnfto configure the VF
So going low-level, let's create the following YAML containing the basic steps to install the SR-IOV Operator from OperatorHub
- Create the
openshift-sriov-network-operatornamespaces - Define the SR-IOV Operator
- Subscribe to the SR-IOV Operator in the 4.7 channel with the consequential installation of the CRDs
To apply, as usual, oc create -f <path/to/sriov/install/yaml>
apiVersion: v1
kind: Namespace
metadata:
name: openshift-sriov-network-operator
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: sriov-network-operators
namespace: openshift-sriov-network-operator
spec:
targetNamespaces:
- openshift-sriov-network-operator
---
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: sriov-network-operator-subsription
namespace: openshift-sriov-network-operator
spec:
channel: "4.7"
name: sriov-network-operator
source: redhat-operators
sourceNamespace: openshift-marketplaceTo verify the result, you can use the CLI or also the OpenShift Dashboard
# oc get ClusterServiceVersions -n openshift-sriov-network-operator
NAME DISPLAY VERSION REPLACES PHASE
sriov-network-operator.4.7.0-202102110027.p0 SR-IOV Network Operator 4.7.0-202102110027.p0 SucceededIn my case, for SR-IOV, on this specific node, I have an Intel X520, an Intel XXV710, and a Mellanox Nvidia ConnectX-5. Given the X520 is not officially supported by OpenShift, I'm going first to disable the admission controller webhook.
oc patch sriovoperatorconfig default --type=merge \
-n openshift-sriov-network-operator \
--patch '{ "spec": { "enableOperatorWebhook": false } }'The admission controller webhook is 9 out of ten disabled in real life scenarios. When you buy hardware from Dell or HPE, the PCI Vendor and Device ID will be most probably customized by the OEM. You'll ask why in my case all devices have standard IDs: all NICs are bought directly from Intel and Mellanox Nvidia and not by Dell. If you don't disable it, unless your NIC is fully certified, you'll get the following error
Error from server (no supported NIC is selected by the nicSelector in CR worker-cnf-intel-x520-east): error when creating "x520.yaml": admission webhook "operator-webhook.sriovnetwork.openshift.io" denied the request: no supported NIC is selected by the nicSelector in CR worker-cnf-intel-x520-east
Error from server (no supported NIC is selected by the nicSelector in CR worker-cnf-intel-x520-west): error when creating "x520.yaml": admission webhook "operator-webhook.sriovnetwork.openshift.io" denied the request: no supported NIC is selected by the nicSelector in CR worker-cnf-intel-x520-westSee below all my NIC in this specific worker node from lscpi
# lspci -nn -vvv | grep "Ethernet controller" | grep -v "Virtual Function"
01:00.0 Ethernet controller [0200]: Intel Corporation I350 Gigabit Network Connection [8086:1521] (rev 01)
01:00.1 Ethernet controller [0200]: Intel Corporation I350 Gigabit Network Connection [8086:1521] (rev 01)
01:00.2 Ethernet controller [0200]: Intel Corporation I350 Gigabit Network Connection [8086:1521] (rev 01)
01:00.3 Ethernet controller [0200]: Intel Corporation I350 Gigabit Network Connection [8086:1521] (rev 01)
04:00.0 Ethernet controller [0200]: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection [8086:10fb] (rev 01)
04:00.1 Ethernet controller [0200]: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection [8086:10fb] (rev 01)
81:00.0 Ethernet controller [0200]: Mellanox Technologies MT27800 Family [ConnectX-5] [15b3:1017]
81:00.1 Ethernet controller [0200]: Mellanox Technologies MT27800 Family [ConnectX-5] [15b3:1017]
83:00.0 Ethernet controller [0200]: Intel Corporation Ethernet Controller XXV710 for 25GbE SFP28 [8086:158b] (rev 02)
83:00.1 Ethernet controller [0200]: Intel Corporation Ethernet Controller XXV710 for 25GbE SFP28 [8086:158b] (rev 02)One port per NIC also the view from ethtool
# ethtool -i enp4s0f0
driver: ixgbe
version: 5.1.0-k-rh8.2.0
firmware-version: 0x000161c1, 1.2177.0
expansion-rom-version:
bus-info: 0000:04:00.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: yes
supports-register-dump: yes
supports-priv-flags: yes
# ethtool -i enp131s0f0
driver: i40e
version: 2.8.20-k
firmware-version: 7.10 0x800075e6 19.5.12
expansion-rom-version:
bus-info: 0000:83:00.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: yes
supports-register-dump: yes
supports-priv-flags: yes
# ethtool -i enp129s0f0
driver: mlx5_core
version: 5.0-0
firmware-version: 16.27.2008 (MT_0000000080)
expansion-rom-version:
bus-info: 0000:81:00.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: yesThe configuration is somehow simple ...
Each physical NIC has two ports and we create a pool of VF per Port. In this way, redundancy can be managed.
The resourceName embedds the east and west characteristic (respectively first and second port of the NIC).
Below you can find my Intel X520 SriovNetworkNodePolicy
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: worker-cnf-intel-x520-east
namespace: openshift-sriov-network-operator
spec:
resourceName: intel_x520_east
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
mtu: 9100
numVfs: 32
nicSelector:
pfNames:
- enp4s0f0
rootDevices:
- '0000:04:00.0'
vendor: '8086'
deviceType: vfio-pci
isRdma: false
linkType: eth
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: worker-cnf-intel-x520-west
namespace: openshift-sriov-network-operator
spec:
resourceName: intel_x520_west
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
mtu: 9100
numVfs: 32
nicSelector:
pfNames:
- enp4s0f1
rootDevices:
- '0000:04:00.1'
vendor: '8086'
deviceType: vfio-pci
isRdma: false
linkType: ethBelow you can find my Intel XXV710 SriovNetworkNodePolicy
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: worker-cnf-intel-xxv710-east
namespace: openshift-sriov-network-operator
spec:
resourceName: intel_xxv710_east
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
mtu: 9100
numVfs: 32
nicSelector:
pfNames:
- enp131s0f0
deviceType: vfio-pci
isRdma: false
linkType: eth
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: worker-cnf-intel-xxv710-west
namespace: openshift-sriov-network-operator
spec:
resourceName: intel_xxv710_west
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
mtu: 9100
numVfs: 32
nicSelector:
pfNames:
- enp131s0f1
deviceType: vfio-pci
isRdma: false
linkType: ethBelow you can find my Mellanox Nvidia ConnectX-5 SriovNetworkNodePolicy
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: worker-cnf-mellanox-cx5-east
namespace: openshift-sriov-network-operator
spec:
resourceName: mellanox_cx5_east
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
mtu: 9100
numVfs: 32
nicSelector:
pfNames:
- enp129s0f0
deviceType: netdevice
isRdma: true
linkType: eth
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: worker-cnf-mellanox-cx5-west
namespace: openshift-sriov-network-operator
spec:
resourceName: mellanox_cx5_west
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
mtu: 9100
numVfs: 32
nicSelector:
pfNames:
- enp129s0f1
deviceType: netdevice
isRdma: true
linkType: ethTo verify the outcome, keep an eye on the worker-cnf MachineConfigPool, the sriov-device-plugin Pod (in openshift-sriov-network-operator) and of course on the node itself. See below the log of a successful execution.
# oc get pods -l app=sriov-device-plugin -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
sriov-device-plugin-pq772 1/1 Running 0 7m35s 10.0.11.11 openshift-worker-cnf-1 <none> <none>
# oc logs pod/sriov-device-plugin-pq772
I0312 19:37:06.502704 1 manager.go:52] Using Kubelet Plugin Registry Mode
I0312 19:37:06.502809 1 main.go:44] resource manager reading configs
I0312 19:37:06.502918 1 manager.go:86] raw ResourceList: {"resourceList":[{"resourceName":"intel_x520_east","selectors":{"vendors":["8086"],"drivers":["vfio-pci"],"pfNames":["enp4s0f0"],"rootDevices":["0000:04:00.0"],"linkTypes":["ether"],"IsRdma":false,"NeedVhostNet":false},"SelectorObj":null},{"resourceName":"intel_x520_west","selectors":{"vendors":["8086"],"drivers":["vfio-pci"],"pfNames":["enp4s0f1"],"rootDevices":["0000:04:00.1"],"linkTypes":["ether"],"IsRdma":false,"NeedVhostNet":false},"SelectorObj":null},{"resourceName":"intel_xxv710_east","selectors":{"drivers":["vfio-pci"],"pfNames":["enp131s0f0"],"linkTypes":["ether"],"IsRdma":false,"NeedVhostNet":false},"SelectorObj":null},{"resourceName":"intel_xxv710_west","selectors":{"drivers":["vfio-pci"],"pfNames":["enp131s0f1"],"linkTypes":["ether"],"IsRdma":false,"NeedVhostNet":false},"SelectorObj":null},{"resourceName":"mellanox_cx5_east","selectors":{"pfNames":["enp129s0f0"],"linkTypes":["ether"],"IsRdma":true,"NeedVhostNet":false},"SelectorObj":null},{"resourceName":"mellanox_cx5_west","selectors":{"pfNames":["enp129s0f1"],"linkTypes":["ether"],"IsRdma":true,"NeedVhostNet":false},"SelectorObj":null}]}
I0312 19:37:06.502966 1 factory.go:168] net device selector for resource intel_x520_east is &{DeviceSelectors:{Vendors:[8086] Devices:[] Drivers:[vfio-pci] PciAddresses:[]} PfNames:[enp4s0f0] RootDevices:[0000:04:00.0] LinkTypes:[ether] DDPProfiles:[] IsRdma:false NeedVhostNet:false}
I0312 19:37:06.502992 1 factory.go:168] net device selector for resource intel_x520_west is &{DeviceSelectors:{Vendors:[8086] Devices:[] Drivers:[vfio-pci] PciAddresses:[]} PfNames:[enp4s0f1] RootDevices:[0000:04:00.1] LinkTypes:[ether] DDPProfiles:[] IsRdma:false NeedVhostNet:false}
I0312 19:37:06.503006 1 factory.go:168] net device selector for resource intel_xxv710_east is &{DeviceSelectors:{Vendors:[] Devices:[] Drivers:[vfio-pci] PciAddresses:[]} PfNames:[enp131s0f0] RootDevices:[] LinkTypes:[ether] DDPProfiles:[] IsRdma:false NeedVhostNet:false}
I0312 19:37:06.503017 1 factory.go:168] net device selector for resource intel_xxv710_west is &{DeviceSelectors:{Vendors:[] Devices:[] Drivers:[vfio-pci] PciAddresses:[]} PfNames:[enp131s0f1] RootDevices:[] LinkTypes:[ether] DDPProfiles:[] IsRdma:false NeedVhostNet:false}
I0312 19:37:06.503028 1 factory.go:168] net device selector for resource mellanox_cx5_east is &{DeviceSelectors:{Vendors:[] Devices:[] Drivers:[] PciAddresses:[]} PfNames:[enp129s0f0] RootDevices:[] LinkTypes:[ether] DDPProfiles:[] IsRdma:true NeedVhostNet:false}
I0312 19:37:06.503037 1 factory.go:168] net device selector for resource mellanox_cx5_west is &{DeviceSelectors:{Vendors:[] Devices:[] Drivers:[] PciAddresses:[]} PfNames:[enp129s0f1] RootDevices:[] LinkTypes:[ether] DDPProfiles:[] IsRdma:true NeedVhostNet:false}
I0312 19:37:06.503045 1 manager.go:106] unmarshalled ResourceList: [{ResourcePrefix: ResourceName:intel_x520_east DeviceType:netDevice Selectors:0xc000298f80 SelectorObj:0xc0003969c0} {ResourcePrefix: ResourceName:intel_x520_west DeviceType:netDevice Selectors:0xc000298fa0 SelectorObj:0xc000396dd0} {ResourcePrefix: ResourceName:intel_xxv710_east DeviceType:netDevice Selectors:0xc000298fc0 SelectorObj:0xc000397040} {ResourcePrefix: ResourceName:intel_xxv710_west DeviceType:netDevice Selectors:0xc000298fe0 SelectorObj:0xc0003972b0} {ResourcePrefix: ResourceName:mellanox_cx5_east DeviceType:netDevice Selectors:0xc000299020 SelectorObj:0xc000397520} {ResourcePrefix: ResourceName:mellanox_cx5_west DeviceType:netDevice Selectors:0xc000299040 SelectorObj:0xc000397790}]
I0312 19:37:06.503079 1 manager.go:193] validating resource name "openshift.io/intel_x520_east"
I0312 19:37:06.503096 1 manager.go:193] validating resource name "openshift.io/intel_x520_west"
I0312 19:37:06.503106 1 manager.go:193] validating resource name "openshift.io/intel_xxv710_east"
I0312 19:37:06.503126 1 manager.go:193] validating resource name "openshift.io/intel_xxv710_west"
I0312 19:37:06.503134 1 manager.go:193] validating resource name "openshift.io/mellanox_cx5_east"
I0312 19:37:06.503141 1 manager.go:193] validating resource name "openshift.io/mellanox_cx5_west"
I0312 19:37:06.503145 1 main.go:60] Discovering host devices
<SNIP>
I0312 19:37:06.618259 1 main.go:77] All servers started.
I0312 19:37:06.618268 1 main.go:78] Listening for term signals
I0312 19:37:07.594559 1 server.go:106] Plugin: openshift.io_mellanox_cx5_west.sock gets registered successfully at Kubelet
I0312 19:37:07.594560 1 server.go:131] ListAndWatch(mellanox_cx5_west) invoked
I0312 19:37:07.594586 1 server.go:139] ListAndWatch(mellanox_cx5_west): send devices &ListAndWatchResponse{Devices:[]*Device{&Device{ID:0000:81:00.6,Health:Healthy,Topology:&TopologyInfo{Nodes:[]*NUMANode{&NUMANode{ID:1,},},},},&Device{ID:0000:81:00.7,Health:Healthy,Topology:&TopologyInfo{Nodes:[]*NUMANode{&NUMANode{ID:1,},},},},&Device{ID:0000:81:01.0,Health:Healthy,Topology:&TopologyInfo{Nodes:[]*NUMANode{&NUMANode{ID:1,},},},},&Device{ID:0000:81:01.1,Health:Healthy,Topology:&TopologyInfo{Nodes:[]*NUMANode{&NUMANode{ID:1,},},},},},}
I0312 19:37:07.594632 1 server.go:106] Plugin: openshift.io_mellanox_cx5_east.sock gets registered successfully at Kubelet
I0312 19:37:07.594707 1 server.go:131] ListAndWatch(mellanox_cx5_east) invoked
I0312 19:37:07.594724 1 server.go:139] ListAndWatch(mellanox_cx5_east): send devices &ListAndWatchResponse{Devices:[]*Device{&Device{ID:0000:81:00.2,Health:Healthy,Topology:&TopologyInfo{Nodes:[]*NUMANode{&NUMANode{ID:1,},},},},&Device{ID:0000:81:00.3,Health:Healthy,Topology:&TopologyInfo{Nodes:[]*NUMANode{&NUMANode{ID:1,},},},},&Device{ID:0000:81:00.4,Health:Healthy,Topology:&TopologyInfo{Nodes:[]*NUMANode{&NUMANode{ID:1,},},},},&Device{ID:0000:81:00.5,Health:Healthy,Topology:&TopologyInfo{Nodes:[]*NUMANode{&NUMANode{ID:1,},},},},},}On the node itself, you will see the following
# ip link show enp4s0f0
5: enp4s0f0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9100 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 90:e2:ba:7a:ab:3c brd ff:ff:ff:ff:ff:ff
vf 0 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off, query_rss off
vf 1 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off, query_rss off
vf 2 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off, query_rss off
vf 3 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off, query_rss off
# ip link show enp131s0f0
6: enp131s0f0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9100 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 40:a6:b7:05:bd:e0 brd ff:ff:ff:ff:ff:ff
vf 0 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off
vf 1 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off
vf 2 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off
vf 3 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off
# ip link show enp129s0f0
11: enp129s0f0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9100 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 0c:42:a1:40:08:b4 brd ff:ff:ff:ff:ff:ff
vf 0 link/ether 2a:c2:2a:07:fc:54 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state auto, trust off, query_rss off
vf 1 link/ether f6:56:c4:90:c1:ec brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state auto, trust off, query_rss off
vf 2 link/ether f2:21:f0:0b:eb:e4 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state auto, trust off, query_rss off
vf 3 link/ether 36:93:08:83:b3:40 brd ff:ff:ff:ff:ff:ff, spoof checking off, link-state auto, trust off, query_rss offAs a more Operator-driven approach to verify the result, you can query the status of sriovnetworknodestates providing the name of the worker node.
# oc get sriovnetworknodestates -n openshift-sriov-network-operator openshift-worker-cnf-1 -o jsonpath='{.status.syncStatus}'
SucceededNext, we will be looking at some verifications.