This project offers three key benefits:
- Cross LLM/SLM Generative AI Operations!
- Currently openai, google's gemini, ... more soon.
- Cross Programming Language Generative AI Operations!
- Currently Java, Python ... more soon.
- Standardized APIs across the Complete Ecosystem of Generative AI Operations!
Here is the LLM Ecosystem diagram from my article entitled What is the LLM Ecosystem?.
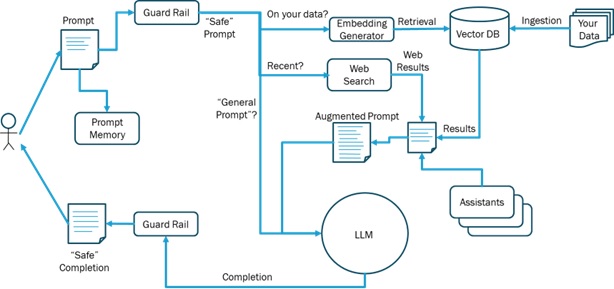
In order to fulfill the objectives cited above (Cross-Language model, Cross-Programming-Language and Complete Ecosystem Services), we will use a gRPC client-server architecture as depicted in this

This project is under active development and will change considerably over the next several months so make sure you check back to get the latest.
Here is the Feature Roadmap:
- Chat API
- Synchronous Completion
- Asynchronous/Streaming Completion
- LM Metadata
- Provider Name
- Model name
- Type (LLM, SLM, etc.)
- Max Prompt Size
- Knowledge Cutoff Date
- LM Capabilities/Profile
- Max Completion Token Limit
- Conversation API
- Shared chats
- Chat History
- Chat IDs
- Chat encryption/Security
- Chat labels
- Chat Owner
- Group Chats?
- System Message
- Completion Format
- Code
- Markdown
- HTML
- Formulas
- Image
- Tables
- JSON
- Shared chats
- LM Customization API
- Token Probabilities API
- LM Parameters API
- Temperature - Controls the randomness or creativity of the model’s output.
- Max tokens - Specifies the maximum number of tokens the model can return in its output.
- Frequency Penalty - Penalizes the model for using words that have already appeared frequently in the text.
- Presence Penalty - Encourages the model to avoid repeating the same tokens or phrases that have already been used in the conversation, promoting more diverse responses.
- Omni-Model API
- Personas API
- Persona metadata
- System text
- Name
- Description
- Type
- Owner
- Persona metadata
- Embeddings API
- Embedding model
- Embedding metadata
- Vector size
- Embedding type
- RAG API
- Index metadata
- Embedding model
- Index labels
- Index Owner
- Index Sharing
- Index Security
- Document metadata
- Images
- OCR
- Tables
- Code
- Chunk metadata
- Vector DB API
- Citations
- Index metadata
- Prompt Memory API
- Prompt Classification API
- Guardrails API
- Prompt Guardrails
- Completion Guardrails
- Custom Functions API
- Web Search API
- Assistants API
- Code Interpretation/Execution
- Code Generation API
- Validation API
- Agent Framework API
To build this software you will first have to insure you have the following pre-requisites:
- Latest Version of Java. You can download it here.
- Latest Version of Python. You can download it here.
- Latest Version of NodeJS. You can download it here.
- gRPC. You can download it here.
- Maven. The project has a pom file. The two key POM lifecycle commands are Compile and Package. The package command creates a runnable Jar file that you can use to run both the client and the server.
- Get Accounts and API keys with all the major LLM/SLM providers.
- Set up the configuration file (copy src/main/resources/config.properties.template to config.properties).
Then add the following.
- OPENAI_API_KEY
- GEMINI_PROJECT_ID (working on getting the gemini api key working. Will have the provider updated soon). NOTE: NEVER push up the config.properties file with any api keys (the .gitignore file should prevent that).
To run the gRPC server you type:
java -jar ./target/xlm-eco-api-1.0-SNAPSHOT.jarNote: under src/main/resources there is a config.properties file that currently has the port to run the server on. The clients will now also accept a host/port instead of having those values hardcoded. The format of the config.properties file is currently only one property:
server.port=50052
To run the java test gRPC client you type:
java -cp ./target/xlm-eco-api-1.0-SNAPSHOT.jar us.daconta.xlmeco.GrpcXlmClient 127.0.0.1 50052 openai "gpt-4o-mini" "Who is FDR?"The python grpc stubs are created via maven and stored in the python_client/generated directory. To run the python client, there is a simple bash script to setup the path.
./run_client.sh --host 127.0.0.1 --port 50052 --provider openai --model_name gpt-4o-mini --prompt "Tell me about space exploration."The node grpc stubs will be created dynamically during runtime.
node ./node_client/app.js --host 127.0.0.1 --port 50052 --provider openai --model_name gpt-4o-mini --prompt "Would you say I have a plethora of pinatas?"
Note: there will be a client created for every language supported by gRPC (Python, C#, C, Go, Rust, etc.)
Feedback on the project is welcome. You can contact me via the contact form here.