The last enterprise web architecture pattern you'll ever need. Until the next one.
The goal is to optimize the developer experience by being able to:
- Develop locally as if it's a monolith
- Deploy as separate microservices
- Simulate the production environment locally using docker
Project Omega Proof of Concept - Microservices Monolith Hybrid
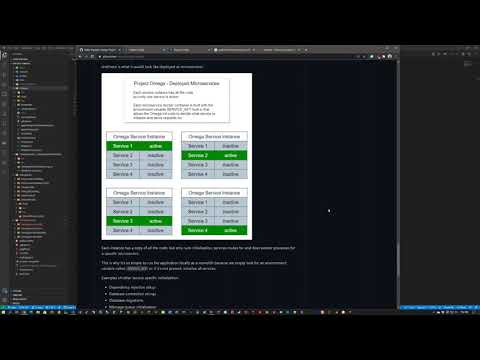
Project Omega Demo - Kubernetes Microserves and Standalone Container Deployment
I want to prove that we don't have to sacrifice developer efficiency to get scalability. More discussion on pros and cons of microservices and monoliths here: Microservices and Monoliths.
My impression is that many industry experts would have us believe that these are our main 3 options:
- Monolith
- Microservices
- "Hybrid" (not really a hybrid, both a monolith and also some microservices)
I want to show that we don't have to pick any of these options. With a little creativity we can have a true "hybrid" that is both a monolith and a set of microservices. With my current strategy I don't think we can eliminate all the downsides of monolith and microservices, but we can get rid of many of the pain points of both.
- I'm not trying to create a framework (not yet at least...). I'm just putting together all the legos I have into a different configuration as an experiment.
- This is not meant to be a community project. I intend to make frequent dramatic breaking changes without notice. If this concept seems interesting to you and you'd like to contribute, contact me first.
- Create a pattern that will work for projects as small single developer hobby projects and also scale to dozens or even hundreds of developers working on large and complex enterprise web applications.
- Be able to develop locally as if it's a monolith:
- One repository. For all the same reasons companies choose a monorepo approach.
- Maximum 3 processes to run (client ui, server, docker dependencies with database, message queue, etc). We don't want pages of setup docs to get up and running.
- Be able to deploy as microservices.
- Be able to simulate a production environment with microservices running in docker containers.
- Extremely fast setup time. All dependencies other than Node and .NET should be included as docker dependencies (database, message queue, etc). New users should be able to install .NET, Node, clone the repo and then execute install and run commands.
- Extremely fast hot reload for both the client and the server in the development environment.
- Be able to develop and run the application on Windows, Linux and Mac.
- Be able to rapidly spin up a new service.
The tech stack is mostly irrelevant for the high level concept I'm attempting to prove, but for this project I'm going to be using:
- .NET 5 for services
- React front-end (basic create-react-app with typescript)
- Docker
Companies with large application are being pushed more and more towards microservices so that they can scale horizontally (among other reasons). So, to accomplish that we're looking at something like the following:

Here is another version showing one way the horizontal scaling might be implemented:

Once we go down this route, we end up with a real problem with local development. It really depends on what the product is like, how many developers there are, and who works on what, how often. That being said, a large portion of companies that choose microservices are going to end up in a situation where developers have to make some hard choices about how to do their day to day development. With project omega, the goal is to show that we can eliminate the overhead of running a service locally by combining them all into one application while running locally:

Here is the folder structure:

And here is what it would look like deployed as microservices:

Each instance has a copy of all the code but only runs initialization, service endpoint routes and worker processes for a specific microservice.
This is why it's so simple to run the application locally as a monolith because we simply look for an environment variable called SERVICE_KEY or if it's not present, initialize all services.
Examples of other service specific initialization:
- Dependency injection setup
- Database connection strings
- Database migrations
- Message queue initialization
- Setup distributed cache connectivity
- Other cloud resource connectivity setup
- Third party API initialization
When Startup is called it scans assemblies for types that inherit ProjectOmegaService, creates an instance and runs that service's initialization logic. When running locally it will run them all.
Install pre-requisites:
- .NET 5
- Node
- Yarn
- Docker
Note that getting the latest version of docker running on windows may require some extra steps if you haven't done this in a while, like installing WSL 2 and refreshing your WSL distro. Follow any instructions on Docker's website.
Steps:
- Clone this repo
- In a terminal from repo root, run
yarn run installAll - If you want to run SQL server on a port other than 1434:
- Run
yarn run syncEnvFiles - Change
OMEGA_DEFAULT_DB_PORTandOMEGA_MSSQL_HOST_PORTin.env.server
- Run
- Start the dependencies using the command
yarn run dockerDepsUpDetached - Run DB migrations the first time you run, or when you get someone elses changes with database updates:
yarn run dbMigrate - Run the app in local development mode using one of these options:
- Option 1: in a terminal from repo root run
yarn run both(this uses concurrently to run the commands from options 2) - Option 2: use 2 separate terminals. In one terminal run
yarn run clientand in the other runyarn run server
- Option 1: in a terminal from repo root run
- Access https://localhost:3000 (click past https warning)
Before running unit tests with dotnet test the first time or after adding unit tests on new DB schema:
- Start dependencies if not already running with
yarn run dockerDepsUpDetached - Run
yarn run testDbMigrate - Then run
dotnet test
To simulate production and microservices in docker:
- Ensure docker dependencies are running with
yarn run dockerDepsUpDetached - In a terminal from repo root, run
yarn run dockerRecreateFull - Access https://localhost:3000 (click past https warning)
- Logging changes
- Experiment with Serilog json formatter
- Add correlation ID and other contextual info to log entries
- Add additional documentation
- Diagrams of how docker simulation works
- Docker dependencies
- Text description of what it is, how it works
- Diagrams of how docker deps fits into development process
- Routing/proxy documentation
- DB migrations
- RPC test between services instead of http rest calls (maybe with something like this: https://github.com/aspnet/AspLabs/tree/main/src/GrpcHttpApi)
- Add to inter-service client base class to abstract error handling and logging
- Auth implementation
- Front-end site registration
- Service to service auth (OAuth?)
- Automatic documentation generation (swagger and html xml documentation output)
- Queue setup and worker process services
- Abstract queue definition (to allow using cloud services as an option)
- Basic worker process type service with an event loop looking for messages
- RabbitMQ in docker-compose.deps.yml
- RabbitMQ basic implementation wired up to worker process service
- Additional local kubernetes demo work
- Database will probably require learning how to use a kubernetes persistent volume, unless I can figure out how to adjust networking to expose the host DB
- Add Seq or make Seq functionality optional and don't use it when running in kubernetes
- Meta project/script to analyze solution
- Analyze affected services based on files changed (for granularity of deployment)
- Project scaffolding:
- Ability to spin up a new copy of the project using some other project "key" besides Omega for all the project/directory names
- Ability to have a new project spin up docker containers and do effectively integration tests to ensure successful new project creation
If you're developing on linux, you may run into this error when starting the server:
System.AggregateException: One or more errors occurred. (The configured user limit (128) on the number of inotify instances has been reached, or the per-process limit on the number of open file descriptors has been reached.)
This is likely caused by too many file watches being used up by vscode. You can increase your inotify instances limit (not just watches limit, which is probably already set very high in your /etc/sysctl.conf file) by running this command:
echo fs.inotify.max_user_instances=524288 | sudo tee -a /etc/sysctl.conf && sudo sysctl -p
Design pattern cost benefit analysis: DesignPatternCostBenefit.md
Design pattern variations: DesignPatternVariations.md
Decisions: Decisions.md
Software Development Philosophies and Rants: https://gist.github.com/mikey-t/3d5d6f0f5316abf9e74fb553be9fdef3