YOLOv4 Implementation in tensorflow 2.6.
The arch is divided in three (3) modules/stages. Backbone -> Head -> Neck, which describes the entire pipeline from an 416x416 RGB input image to a 3-scaled detection tensor, with the predicted classified bounding boxes for each element within the image.
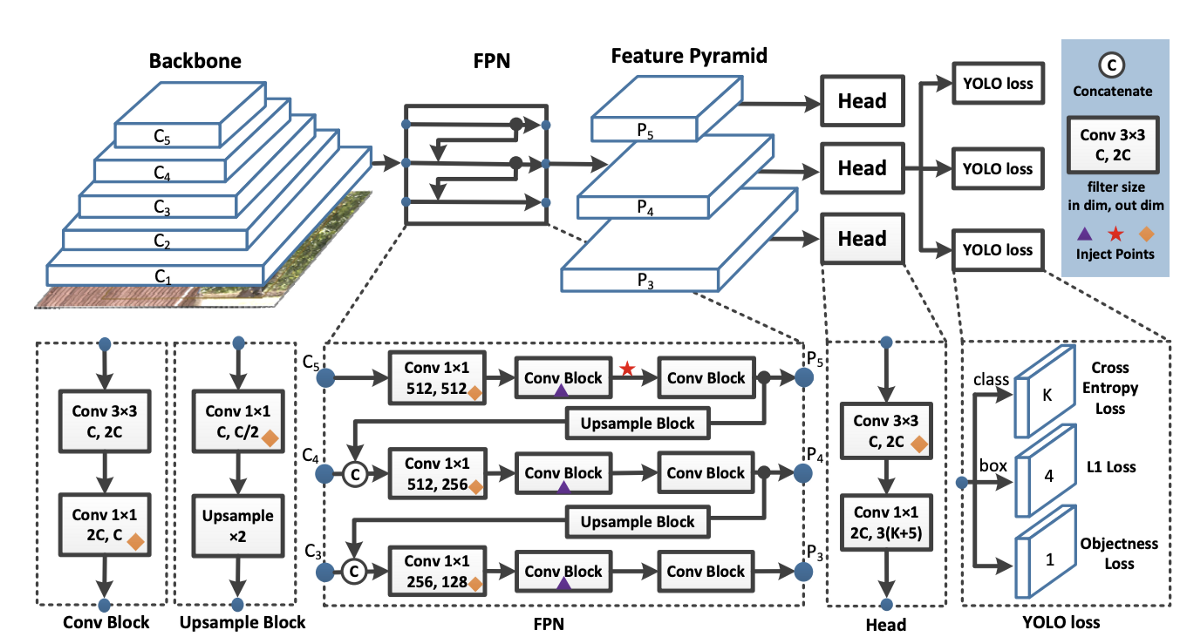
It takes the input image an extract the feature maps from a 53 layered shortcut based (residual block) convolutional pyramid. Each convolution is a convbn block, build up from 2d convolution, batch normalization and a Mish activation function (Bag of Specials).
Along the convolutional chain, some intermediate activation maps are stored, for the stage ouputs. The backbone returns a three scaled array, with 2 intermediate maps and the final one. This structure is then, used by the PANet.
It takes the last activation map and passes through a SPP additional block, concatenating the origin map, with three maxpoolings of different scales, but equal padding. This allows a fixed output sized and a major generalization of the extracted features.
This final tensor is used by the PANet to extract more features with convbn blocks and concatenated them with the prior intermediate layers from the backbone stage. This maintains the fine grain details of the image for larger scales, as well as a higher abstraction for complex patterns, due to the additional convolutions block over the backbone ouput. (Inverse Convolutional Pyramid)
From the thre mixed outputs from the PANet, it creates a 1 + 4 + classes depth tensor for each image scale, in order to identify the object scoreness in each cell of the "image grid", wheter in that cell is probable to find an element of interest, the bounding box parameters (x1, y1, x2, y2) and the one hot encoding vector for multiclass classification of the object enclosed by the boundingbox.