Author: Michael Wirtz
After gathering a base of data from Kaggle, I used natural language processing to analyze attributes of the tweets in the dataset in order to to classify them as either -1 (tweet indicates that climate change is not man-made), 0 (tweet is neutral on whether or not climate change is man-made), 1 (tweet indicates that climate change is man-made), or 2 (tweet is for news). The focus, however, was on the 'Anti' and 'Man' classes. That said, the addition of the 'Neutral' and 'News' classes serve to make the classifier more accurate. Therefore, the classifier will be used to predict on all four classes.
Throught the process of text manipulation and exploration, I was able to better understand the attributes that make up each class of tweets. Based off of findings in that step, I was able to create features to help in the predictive modeling process. Once created, I trained predictive models in an attempt to successfully classify each given tweet in one of the four categories listed above.
After iterative modeling, I created a model using TF-IDF Vectorization and logistic regression that yielded the following f1 scores:
| F1 Scores |
|---|
|
Using the above f1 scores, the classifier was applied. In this application, both the 'Neutral' and 'News' classes were given a score of 0. The values used in the time series and geographic analysis were comprised by taking the average of 'Anti' and 'Man' scores for either a given state or time period.
With a central focus of climate change action, The Environmental Defense Fund (EDF) is one of the world’s leading environmental organizations. As with any non-profit, the EDF requires donations to fuel its mission. Donations and membership from individuals, specifically, make up 68% of annual support and contributions for the EDF. Unfortunately, increasing donations can often come at a cost. According to its form 990 annual tax filings, the EDF saw a staggering 23% increase in their advertising and promotion expenses for its most recently reported year. In an effort to decrease this growth rate in the future, the EDF would like to target potential donors that are most likely to contribute. To do this, the EDF wants to know where and when its promotional efforts would yield the best results.
- Explore the difference between classes of tweets
- Engineer features based of the findings during exploration
- Build a classification model to successfully predict the climate change class of a tweet
- Do time series analysis to find out when the EDF would yield the best results moving forward
- Do geographic analysis to find out where the EDF would yield the best results moving forward
The data exploration process yielded many differences that can be seen between the classes. To see these differences, check out the notebook comprising the whole exploration process here. Furthermore, you can see how this analysis was translated into features here. But, because the engineered features ended up producing a worse model, we will not go into detail on those features here.
Instead, the best model was produced from unigram tf-idf vectorization without the engineered features. Therefore, the data finding that proved to be the most impactful was the class imbalance.
The class imbalance can quickly be understood as stark. With a focus on the 'Man' and 'Anti' classes, this margin of class imbalance is at its highest. Because of this, accuracy was out of the question for the performance metric of the models. Instead, this finding emphasized the need to use f1 score to test the model's ability to differentiate between classes. Check ou the distribution below:

In order to find the best f1 score through modeling, I implemented TF-IDF Vectorizer as well as Doc2Vec. After modeling with both tactics, the best performing model was tuned to optimize its f1 score for application.
The logistic regression TF-IDF model without added features performed the best on the 'Man' and 'Anti' classes for f1. Therefore, I chose that model to tune its hyperparameters. After a few iterations of RandomSearchCV, the model achieved the following results:
| F1 Scores |
|---|
|
Here is the confusion matrix for this model:

The objective here is to find the time of year at which the Environmental Defense Fund (EDF) will receive the highest level of donations relative to advertising and promotional efforts. The assumption for this analysis is that donations will rise proportionately with climate change sentiment. Therefore, the EDF will want to do the most advertising during months with the highest climate change sentiment and the least advertising during months with the lowest climate change sentiment.

Time series analysis indicated that climate change sentiment goes down during the warmer months of the year, whilte rising during the colder months of the year. Additionally, climate change sentiment, and therefore EDF donations, are due to grow year-over-year at a rate of 3.84%.
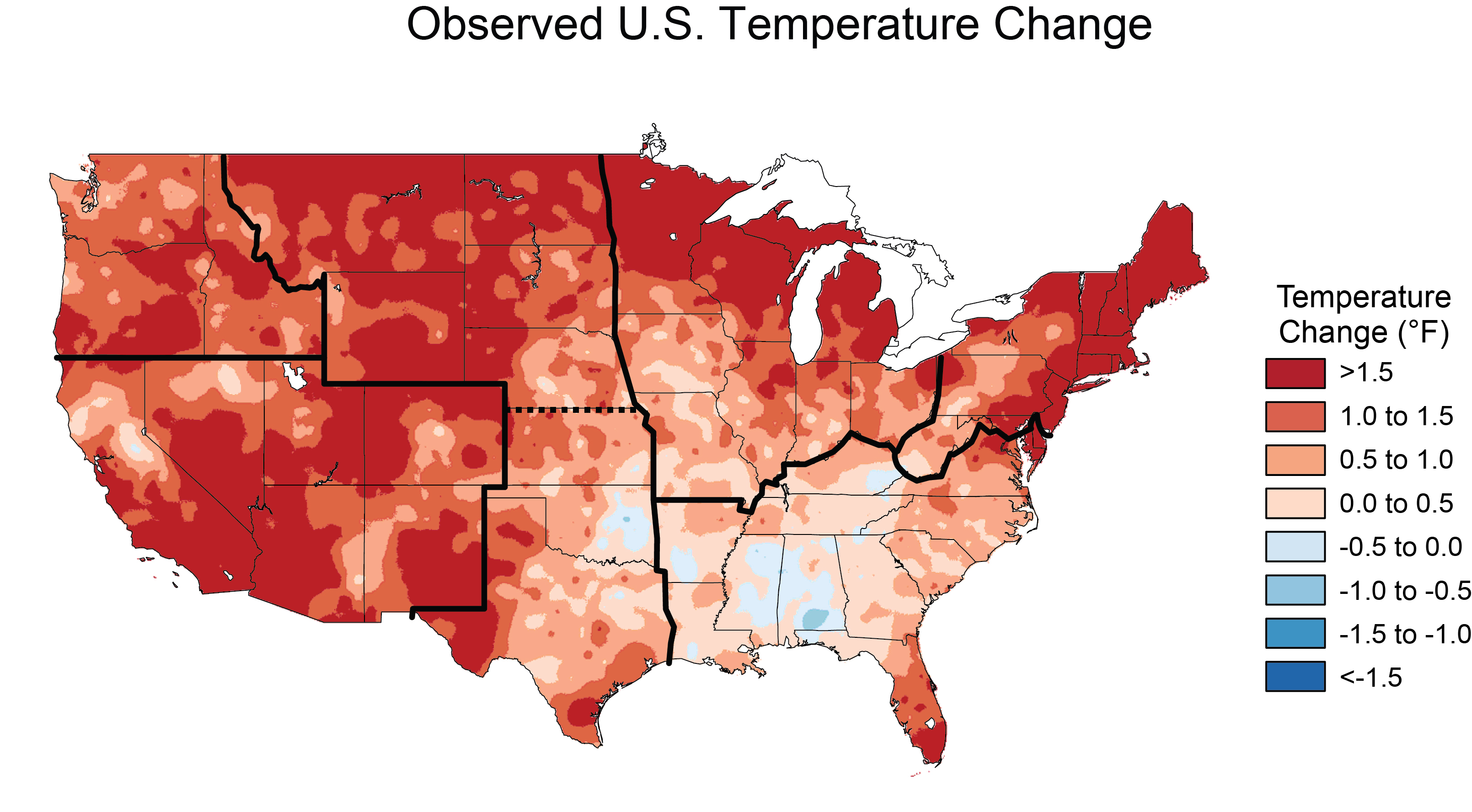
The location breakdown is by state. The objective of this notebook is to find out the states in which the Environmental Defense Fund (EDF) will receive the highest level of donations relative to advertising and promotional efforts. The assumption here, just like for the time series analysis, is that donations per state will rise proportionately with climate change sentiment.

The above graph of the US shows the relative breakdown of a custom composite score. This score is a combination of climate change sentiment, average income, cost of living and charitability rating for each state. The top 5 scoring states are:
- Minnesota
- Maryland
- Oregon
- North Dakota
- Washington
Combining all sections together, the following conclusions can be drawn:
- The classifier is far from perfect. Therefore, the time series and geographic conclusions need to be accepted with caution.
- The EDF has the opportunity to receive the most donations during March in Minnesota. Therefore, the EDF should heavily consider deploying their advertising and promotion campaings to that location at that time. Apart from that, the EDF will get the most donations during the warm months of the year in the following states:
- Minnesota
- Maryland
- Oregon
- North Dakota
- Washington
- Alaska
- Vermont
- Massachusetts
- New York
- Maine
- Create a custom scoring metric that penalizes models more for incorrectly categorizing 'Anti' as 'Man' and vice versa.
- Create a pipline that allows for the time series and geographic analysis to update automatically
- Get location data by county instaead of just by state in order to optimize the geographic analysis
See the full analysis in the final notebook or check out the presentation to see a more detailed explanation of the project above.
For additional info, contact Michael Wirtz at [email protected].
All notebooks, excluding the data_collection notebook, can be run from top to bottom.
├── README.md ├── applying_classifier │ ├── location │ │ ├── data │ │ │ ├── data_prep.ipynb │ │ │ ├── geographic_plotting_data.csv │ │ │ ├── location_functions.py │ │ │ ├── raw_data │ │ │ │ ├── date_tweets_day_1.csv │ │ │ │ ├── date_tweets_day_2.csv │ │ │ │ ├── date_tweets_day_3.csv │ │ │ │ ├── date_tweets_day_4.csv │ │ │ │ └── date_tweets_day_5.csv │ │ │ └── us-states.json │ │ └── geographic_analysis.ipynb │ └── time_series │ ├── data │ │ ├── data_prep.ipynb │ │ ├── raw_data │ │ │ ├── daily_tweets │ │ │ │ ├── collecting_daily_tweets.ipynb │ │ │ │ ├── tweets_2010_1.csv │ │ │ │ ├── tweets_2010_2.csv │ │ │ │ ├── tweets_2010_3.csv │ │ │ │ ├── tweets_2010_4.csv │ │ │ │ ├── tweets_2010_5.csv │ │ │ │ ├── tweets_2011_1.csv │ │ │ │ ├── tweets_2011_2.csv │ │ │ │ ├── tweets_2011_3.csv │ │ │ │ ├── tweets_2011_4.csv │ │ │ │ ├── tweets_2011_5.csv │ │ │ │ ├── tweets_2012_1.csv │ │ │ │ ├── tweets_2012_2.csv │ │ │ │ ├── tweets_2012_3.csv │ │ │ │ ├── tweets_2012_4.csv │ │ │ │ ├── tweets_2012_5.csv │ │ │ │ ├── tweets_2013_1.csv │ │ │ │ ├── tweets_2013_2.csv │ │ │ │ ├── tweets_2013_3.csv │ │ │ │ ├── tweets_2013_4.csv │ │ │ │ ├── tweets_2013_5.csv │ │ │ │ ├── tweets_2014_1.csv │ │ │ │ ├── tweets_2014_2.csv │ │ │ │ ├── tweets_2014_3.csv │ │ │ │ ├── tweets_2014_4.csv │ │ │ │ ├── tweets_2014_5.csv │ │ │ │ ├── tweets_2015_1.csv │ │ │ │ ├── tweets_2015_2.csv │ │ │ │ ├── tweets_2015_3.csv │ │ │ │ ├── tweets_2015_4.csv │ │ │ │ ├── tweets_2015_5.csv │ │ │ │ ├── tweets_2016_1.csv │ │ │ │ ├── tweets_2016_2.csv │ │ │ │ ├── tweets_2016_3.csv │ │ │ │ ├── tweets_2016_4.csv │ │ │ │ ├── tweets_2016_5.csv │ │ │ │ ├── tweets_2017_1.csv │ │ │ │ ├── tweets_2017_2.csv │ │ │ │ ├── tweets_2017_3.csv │ │ │ │ ├── tweets_2017_4.csv │ │ │ │ ├── tweets_2017_5.csv │ │ │ │ ├── tweets_2018_1.csv │ │ │ │ ├── tweets_2018_2.csv │ │ │ │ ├── tweets_2018_3.csv │ │ │ │ ├── tweets_2018_4.csv │ │ │ │ ├── tweets_2018_5.csv │ │ │ │ ├── tweets_2019_1.csv │ │ │ │ ├── tweets_2019_2.csv │ │ │ │ ├── tweets_2019_3.csv │ │ │ │ ├── tweets_2019_4.csv │ │ │ │ ├── tweets_2019_5.csv │ │ │ │ ├── tweets_2020_1.csv │ │ │ │ ├── tweets_2020_2.csv │ │ │ │ ├── tweets_2020_3.csv │ │ │ │ ├── tweets_2020_4.csv │ │ │ │ ├── tweets_2020_5.csv │ │ │ │ ├── twitter_dates_since.csv │ │ │ │ └── twitter_dates_until.csv │ │ │ └── temp_data.csv │ │ ├── time_series_daily_data.csv │ │ └── time_series_functions.py │ └── timeseries_analysis.ipynb ├── building_classifier │ ├── baseline_model.ipynb │ ├── best_model.pickle │ ├── building_classifier_functions.py │ ├── data │ │ ├── prepared_twitter_sentiment_data.csv │ │ └── twitter_sentiment_data.csv │ ├── data_understanding.ipynb │ ├── eda.ipynb │ ├── feature_engineering_and_cleaning.ipynb │ └── modeling.ipynb ├── final_notebook.ipynb ├── functions.py ├── images │ ├── Doc2Vec_rf_confusion_matrix.png │ ├── TFIDF_lr_confusion_matrix.png │ ├── baseline_model.png │ ├── better_lr_image.png │ ├── better_rf_image.png │ ├── class_imbalance.png │ ├── climate_change.png │ ├── colon.png │ ├── cover_image_us.jpeg │ ├── cover_image_us2.jpeg │ ├── daily_time_series.png │ ├── democratic_party.png │ ├── dollar_sign.png │ ├── edf_score_map.png │ ├── exclamation_point.png │ ├── final_model_confusion.png │ ├── hashtag_present.png │ ├── hyperlink_present.png │ ├── mention_present.png │ ├── news_words.png │ ├── number_of_hashtags.png │ ├── number_of_mentions.png │ ├── percent_symbol.png │ ├── question_mark.png │ ├── republican_party.png │ ├── retweet_present.png │ ├── semi_colon.png │ ├── sentiment_comparison.png │ ├── tweet_length.png │ ├── uppercase_words.png │ └── wordclouds_by_class.png └── tweet_climate_change_classification.pdf