July 2020
tl;dr: Use detector for predict object bbox and tracklet. A detector is all you need.
It should be compared with Detect to track and track to detect. The offset regression method proposed in Tracktor directly inspired CenterTrack.
It beats Detect to track and track to detect by almost 10 MOTA on MOT17 challenge.
However it is still based on 2-stage method (Faster RCNN) on region proposal and bbox refinement (regression). In comparison, CenterTrack moved this to single stage domain, and with anchor-free as a bonus point.
Video object detection is essentially multi-object tracking without frame to frame identity prediction.
The paper is not easy to understand.
- Tracktor exploit bbox regression of an object detector to predict the position of an object in the next frame.
- Uses bbox from last frame (or with motion model in Tracktor++) to do RoI Pooling, then regress offset to predict detection in the next frame.
- This assumes large overlap of bbox between frames (high framerate)
- Tracktor performance degrades with low framerates on MOT17.
- Tracktor++ extends Tracktor by introducing motion model and ReID components.
- Motion model. Camera motion and object motion.
- Camera motion compensation (CMC): image registration to compensate for camera rotation and translaton by ECC (enchanced correlation coefficient).
- Bbox motion: most common one is constant velocity (CVM). Shift bbox from previous frame with velocity first, then regress offset.
- ReID: uses Siamese network to extract embedded features.
- Color based models are very common. Detector features not necessarily learn such features and this has to be learned separately.
- Trained on tracking GT data.
- Motion model. Camera motion and object motion.
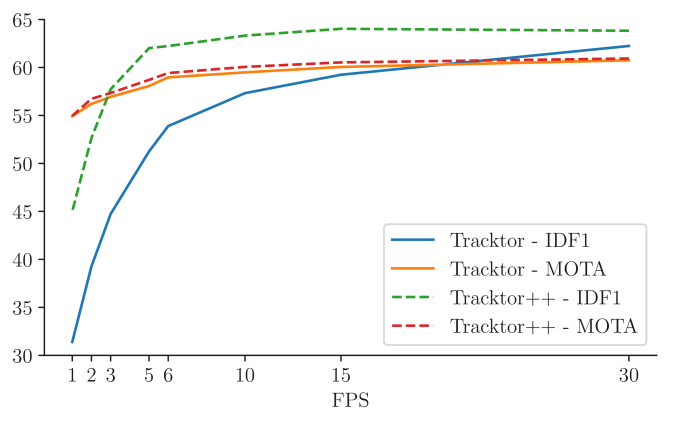
- Tracktor performs equally well or better than all previous methods for hard cases (small object and for highly occluded objects).
- Oracle tracker (upper bound): Motion model and ReID oracle tracker performs the best. This means we can improve Tracktor's performance by introducing a more complicated motion model and a better ReID module,
- Does the model takes in two consecutive frames at the same time?