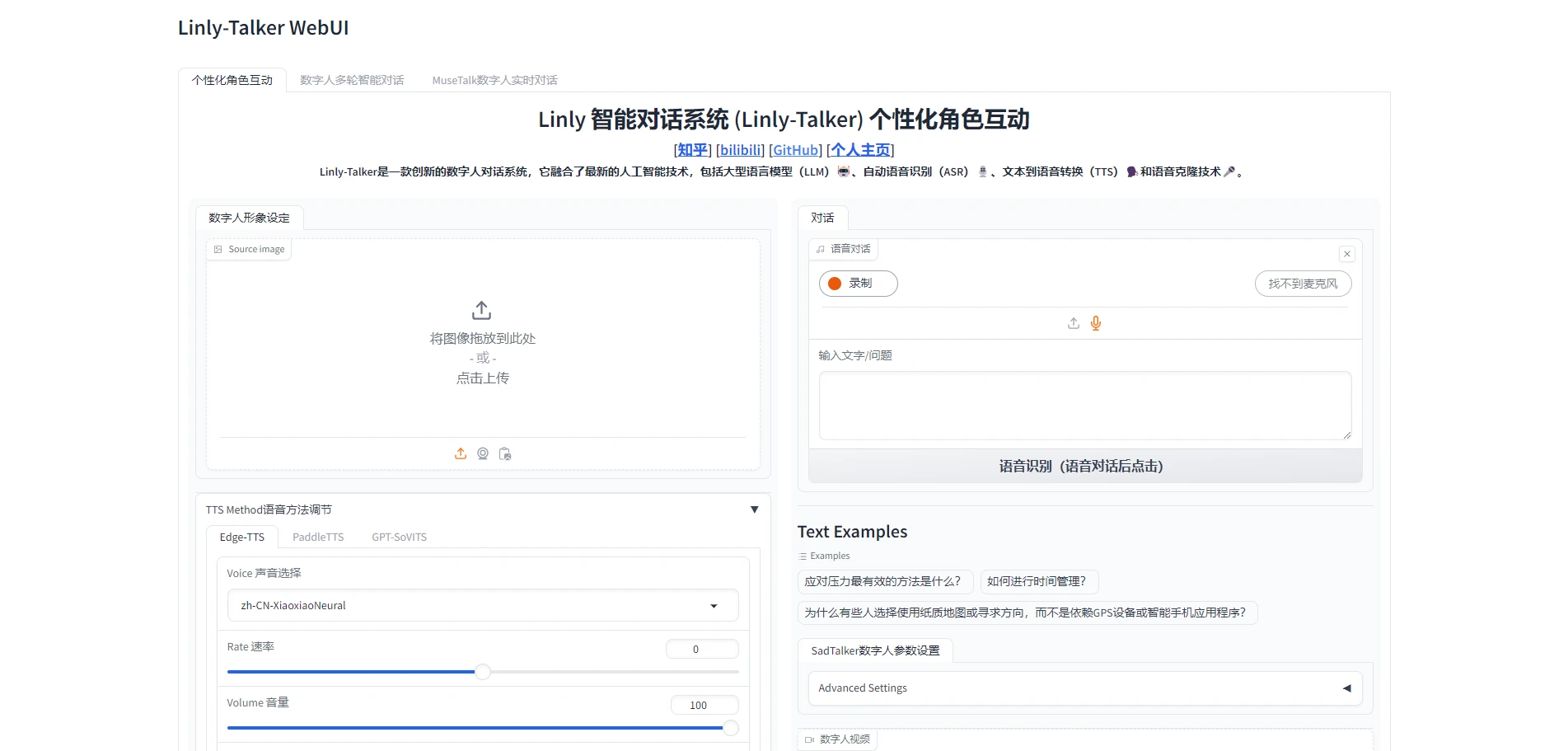
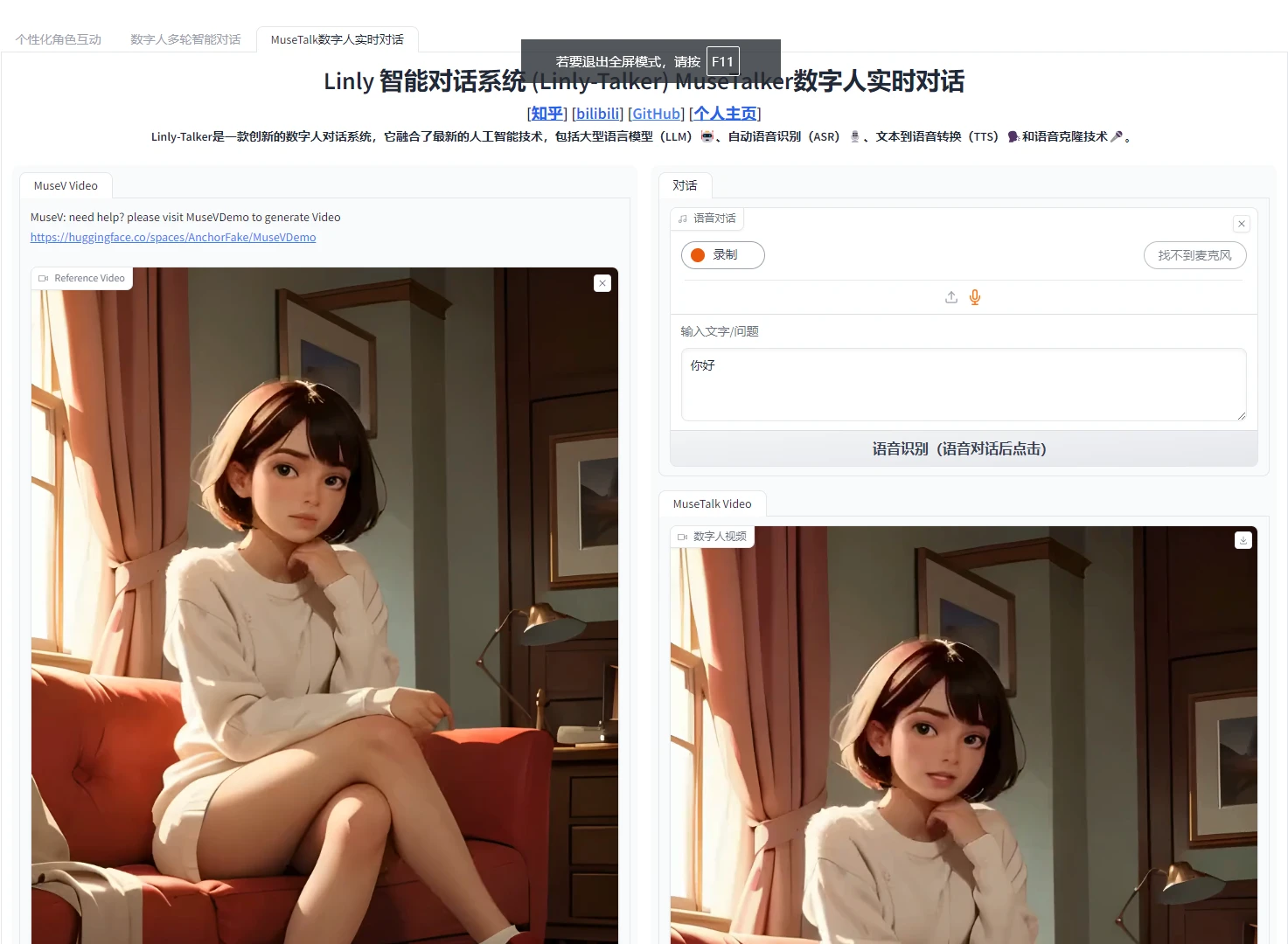
Deployment
若使用我设定好的镜像,可以直接运行即可,不需要安装环境,直接运行webui.py或者是app_talk.py即可体验,不需要安装任何环境,可直接跳到4.4即可
访问后在自定义设置里面打开端口,默认是6006端口,直接使用运行即可!
python webui.py
python app_talk.py环境模型都安装好了,直接使用即可,镜像地址在:https://www.codewithgpu.com/i/Kedreamix/Linly-Talker/Kedreamix-Linly-Talker,感谢大家的支持
AutoDL官网 注册账户好并充值,自己选择机器,我觉得如果正常跑一下,5元已经够了
这一部分实际上我觉得12g都OK的,无非是速度问题而已
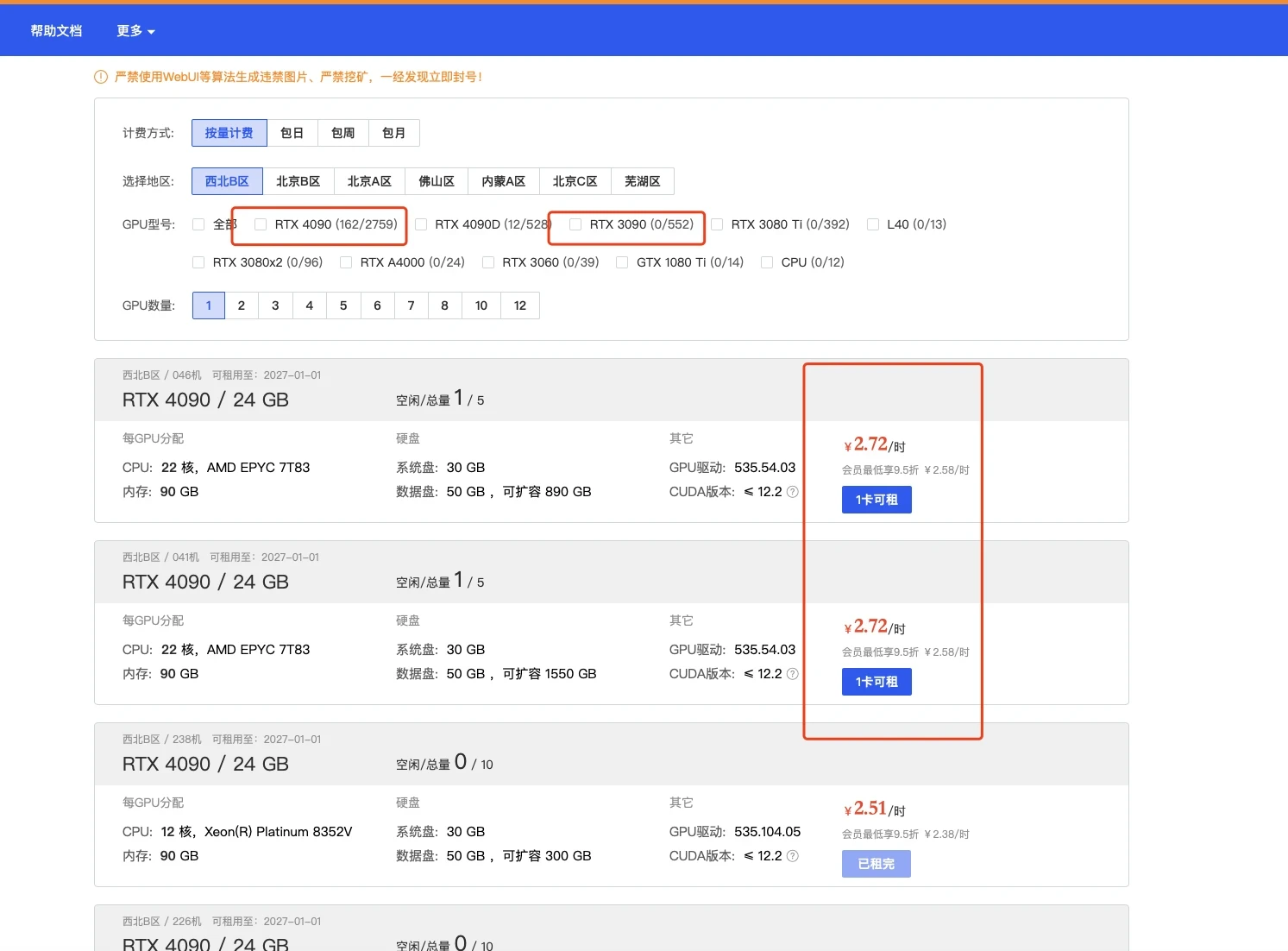
选择镜像,最好选择2.0以上可以体验克隆声音功能,其他无所谓
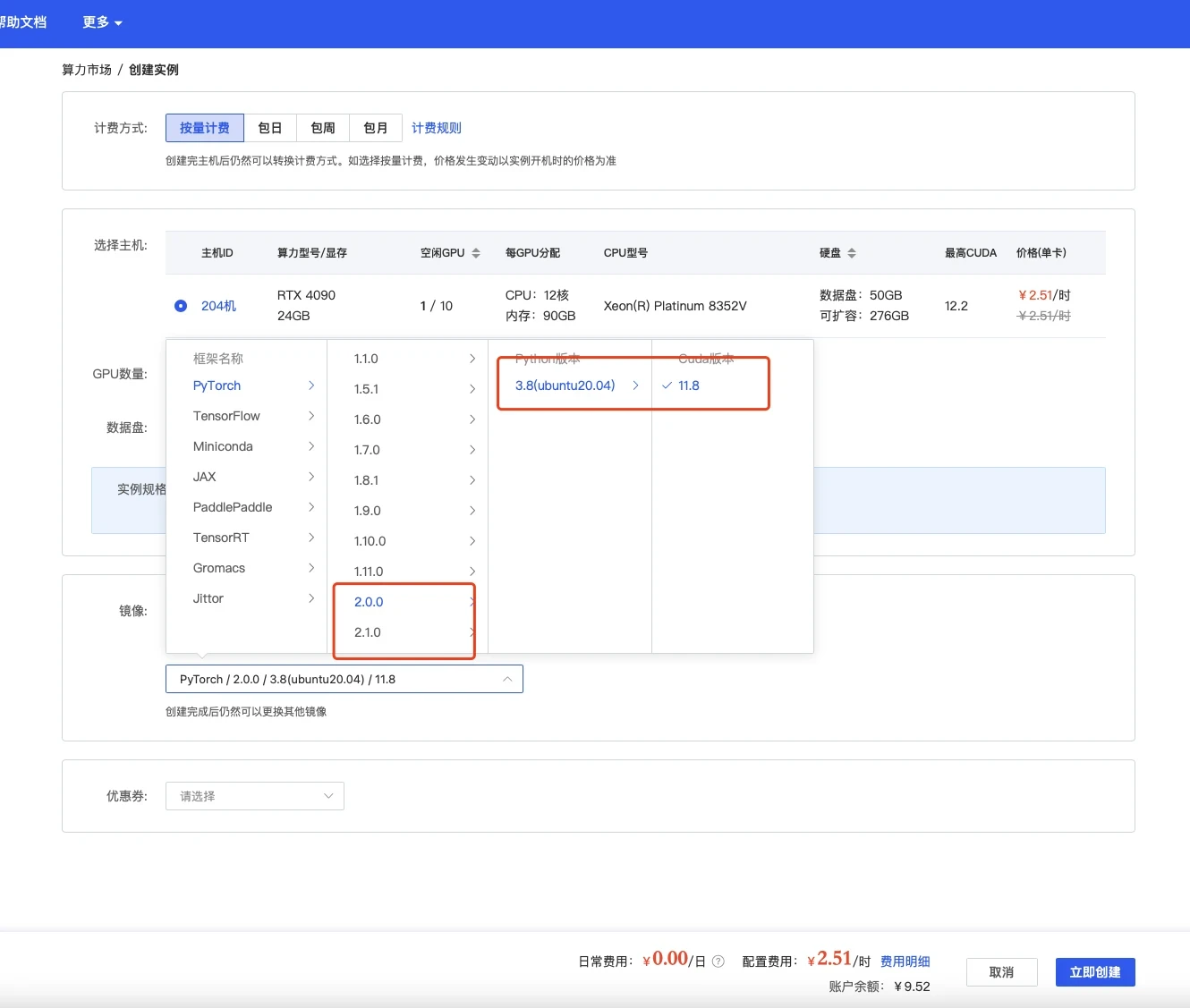
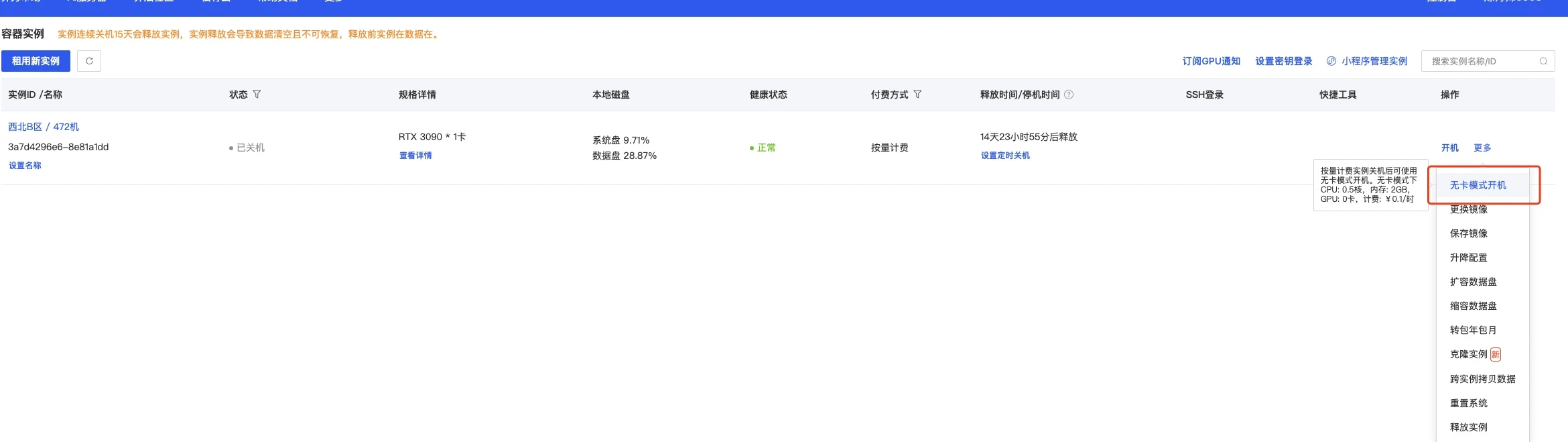
创建成功后为了省钱先关机,然后使用无卡模式开机。 无卡模式一个小时只需要0.1元,比较适合部署环境。
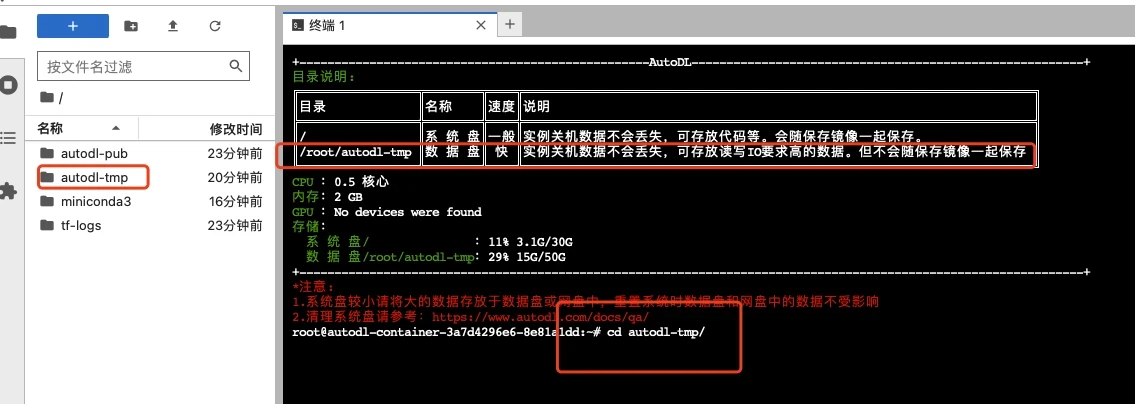
打开jupyterLab,进入数据盘(autodl-tmp),打开终端,将Linly-Talker模型下载到数据盘中。
Install the latest CUDA Toolkit which is compatible with PyTorch.
nvidia-smi
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb -O ~/cuda-keyring_1.1-1_all.deb
sudo dpkg -i ~/cuda-keyring_1.1-1_all.deb
sudo apt update
sudo apt install -y cuda-toolkit
sudo apt install -y ffmpeg libffi-dev libbz2-dev liblzma-dev libssl-dev portaudio19-dev
sudo reboothttps://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=deb_network
https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#environment-setup
Build the latest Python.
wget https://www.python.org/ftp/python/3.12.6/Python-3.12.6.tgz -O ~/Python-3.12.6.tgz
cd ~ && tar -xvzf ~/Python-3.12.6.tgz
cd ~/Python-3.12.6/
./configure
make
sudo make altinstallwget https://www.python.org/ftp/python/3.11.9/Python-3.11.10.tgz -O ~/Python-3.11.10.tgz
cd ~ && tar -xvzf Python-3.11.10.tgz
cd ~/Python-3.11.10/
./configure
make
sudo make altinstall
wget https://www.python.org/ftp/python/3.10.15/Python-3.10.15.tgz -O ~/Python-3.10.15.tgz
cd ~ && tar -xvzf Python-3.10.15.tgz
cd ~/Python-3.10.15/
./configure
make
sudo make altinstall
https://docs.python.org/3/using/unix.html#building-python
Clone the GitHub repository and activate a virtual environment.
cd ~ && git clone https://github.com/pergyz/Linly-Talker.git
cd ~/Linly-Talker/ && git submodule update --init --recursive && python3.12 -m venv .venv312
source .venv312/bin/activate
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
pip install --upgrade pipcd ~ && git clone https://github.com/pergyz/Linly-Talker.git
cd ~/Linly-Talker/ && git submodule update --init --recursive && python3.11 -m venv .venv311
source .venv311/bin/activate
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
pip install --upgrade pipcd ~ && git clone https://github.com/pergyz/Linly-Talker.git
cd ~/Linly-Talker/ && git submodule update --init --recursive && python3.10 -m venv .venv310
source .venv310/bin/activate
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
pip install --upgrade pipInstall the PyTorch.
pip install -r requirements_webui.txt
pip install -r TFG/requirements_nerf.txt
# pip install torch torchvision torchaudio
# pip install av basicsr curl_cffi edge_tts facexlib face_alignment gfpgan gradio g4f imageio joblib kornia librosa lpips ninja numba numpy openai PyAudio pydub PyMCubes PyYAML resampy safetensors scikit-image scipy tensorboardX torch_ema tqdm transformers trimesh ultralytics yacs zhconv
cd ~ && git clone https://github.com/facebookresearch/pytorch3d.git
cd ~/pytorch3d/ && python setup.py installhttps://pytorch.org/
https://github.com/facebookresearch/pytorch3d/blob/main/INSTALL.md#building--installing-from-source
我制作一个脚本可以完成下述所有模型的下载,无需用户过多操作。这种方式适合网络稳定的情况,并且特别适合 Linux 用户。对于 Windows 用户,也可以使用 Git 来下载模型。如果网络环境不稳定,用户可以选择使用手动下载方法,或者尝试运行 Shell 脚本来完成下载。脚本具有以下功能。
- 选择下载方式: 用户可以选择从三种不同的源下载模型:ModelScope、Huggingface 或 Huggingface 镜像站点。
- 下载模型: 根据用户的选择,执行相应的下载命令。
- 移动模型文件: 下载完成后,将模型文件移动到指定的目录。
- 错误处理: 在每一步操作中加入了错误检查,如果操作失败,脚本会输出错误信息并停止执行。
选择使用modelscope来下载会快一点,不需要开学术加速,记得首先需要先安装modelscope库
cd ~/Linly-Talker/
sh scripts/download_models.sh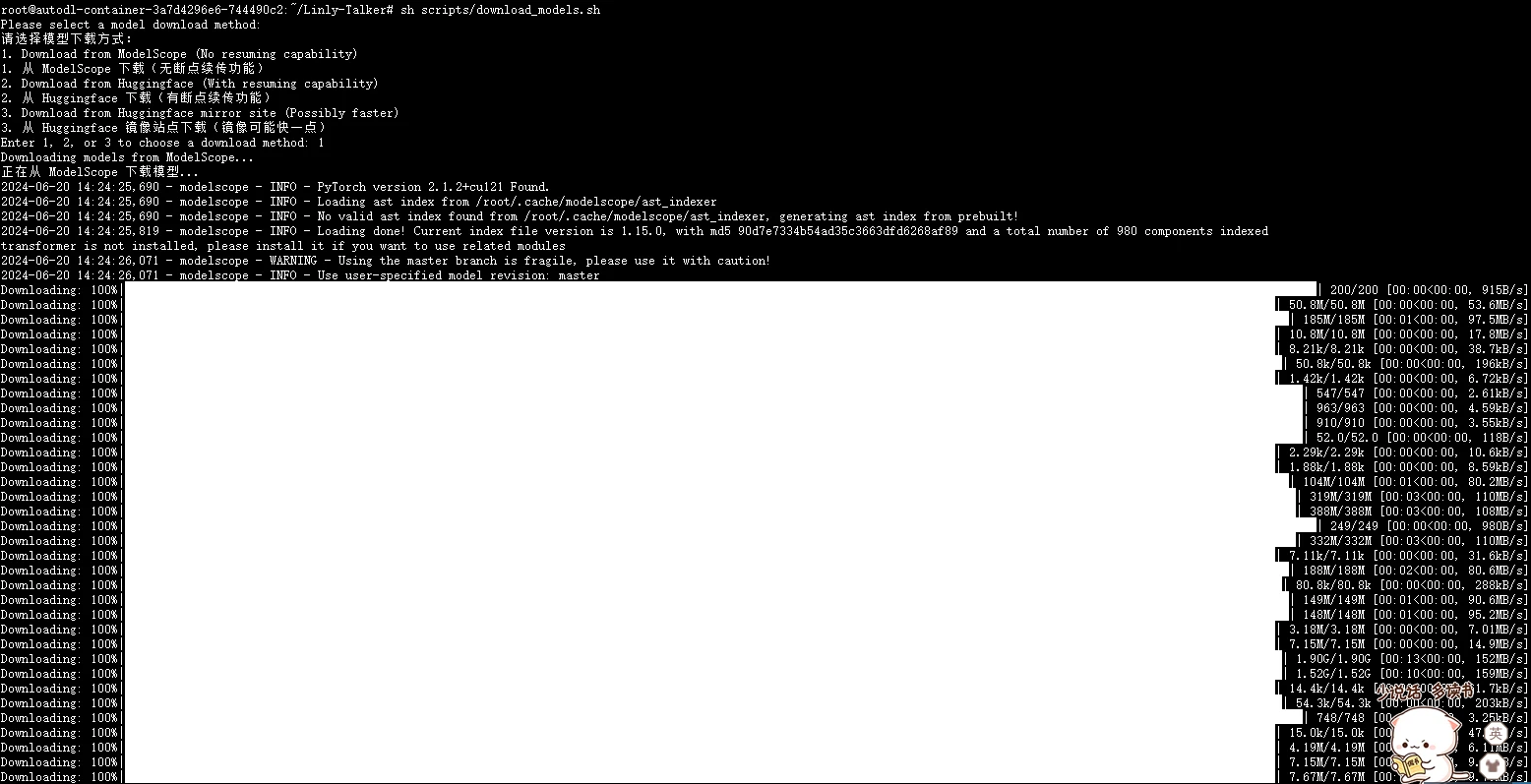
等待一段时间下载完以后,脚本会自动移动到对应的目录
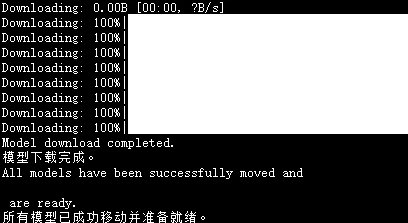
进入代码路径,进行安装环境,由于选了镜像是含有pytorch的,所以只需要进行安装其他依赖即可,可能需要花一定的时间,建议直接使用安装好的镜像
cd /root/autodl-tmp/Linly-Talker
conda install ffmpeg==4.2.2 # ffmpeg==4.2.2
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install tb-nightly -i https://mirrors.aliyun.com/pypi/simple
pip install -r requirements_webui.txt
# 安装有关musetalk依赖
pip install --no-cache-dir -U openmim
mim install mmengine
mim install "mmcv>=2.0.1"
mim install "mmdet>=3.1.0"
mim install "mmpose>=1.1.0"
# 安装NeRF-based依赖,可能问题较多,可以先放弃
# 亲测需要有卡开机后再跑这个pytorch3d,需要一定的内存来编译
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
# 若pyaudio出现问题,可安装对应依赖
sudo apt-get update
sudo apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
pip install -r TFG/requirements_nerf.txt进入autodl容器实例界面,执行关机操作,然后进行有卡开机,开机后打开jupyterLab。
查看配置
nvidia-smi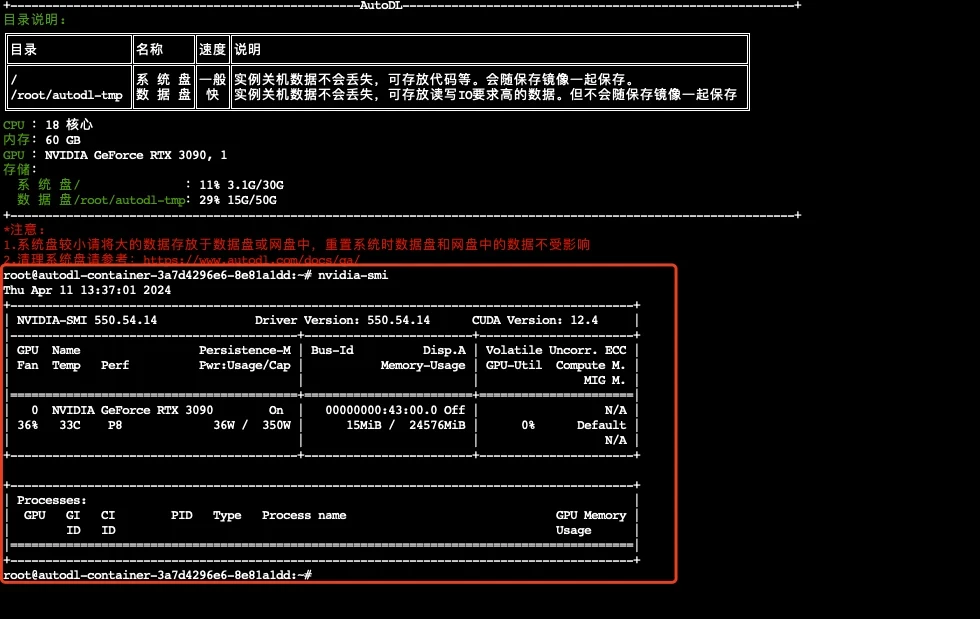
需要有卡模式开机,执行下边命令,这里面就跟代码是一模一样的了
cd /root/autodl-tmp/Linly-Talker
# 第一次运行可能会下载部分nltk,可以使用一下学术加速
source /etc/network_turbo
python webui.py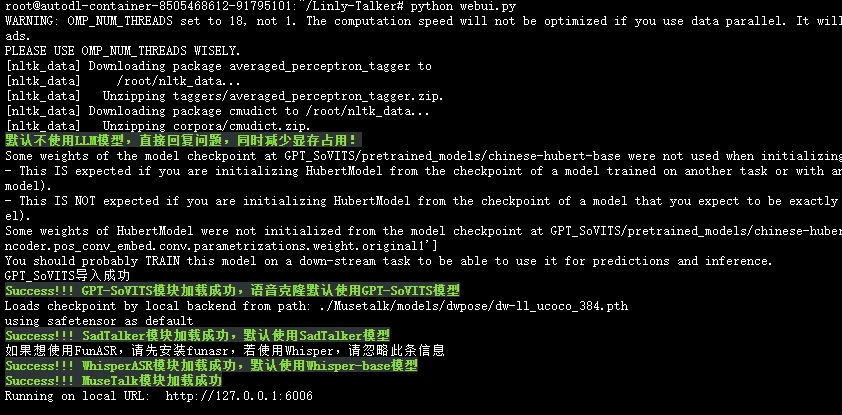
这可以直接打开autodl的自定义服务,默认是6006端口,我们已经设置了,所以直接使用即可
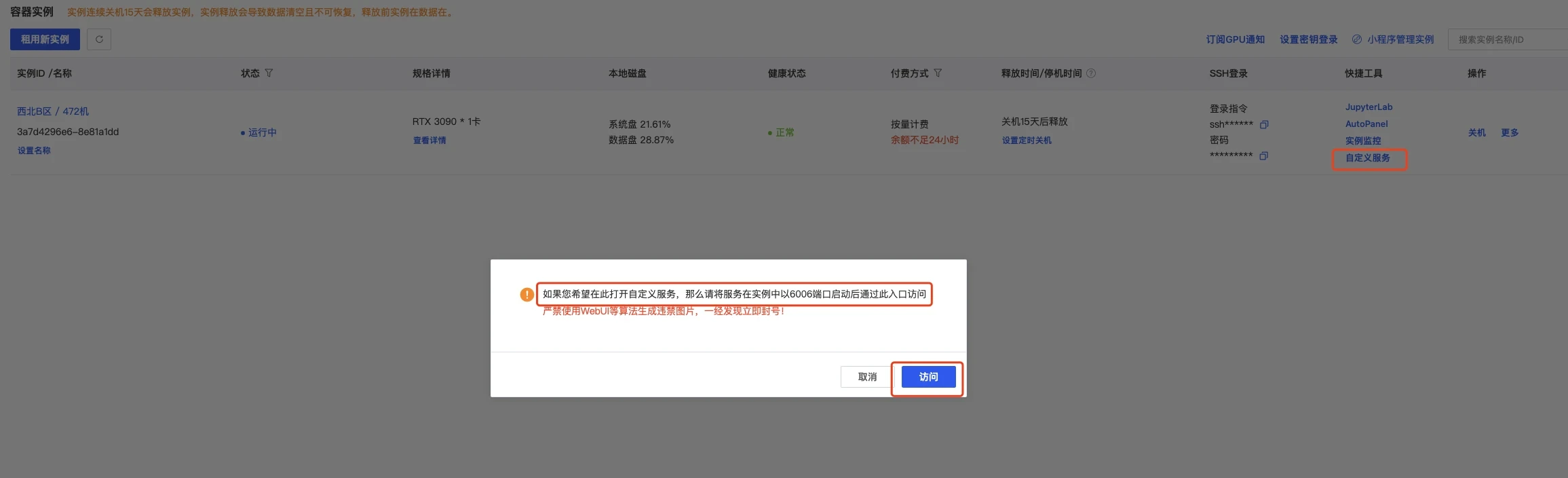
另外还有一种端口映射方式,是通过输入ssh账密实现的,步骤是一样的
ssh端口映射工具:windows:https://autodl-public.ks3-cn-beijing.ksyuncs.com/tool/AutoDL-SSH-Tools.zip
点开网页,即可正确执行Linly-Talker,这一部分就跟视频一模一样了