Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Adding H-Entropy Search and a corresponding tutorial (#1794)
Summary: <!-- Thank you for sending the PR! We appreciate you spending the time to make BoTorch better. Help us understand your motivation by explaining why you decided to make this change. You can learn more about contributing to BoTorch here: https://github.com/pytorch/botorch/blob/main/CONTRIBUTING.md --> ## Motivation This pull request introduces an implementation of the H-Entropy Search [1] procedure, along with a tutorial covering two tasks: Top-K Search and MinMax Search. This PR addresses issue #1733, which requested a new acquisition function for top-K search. [1] W. Neiswanger, L. Yu, S. Zhao, C. Meng, S. Ermon. Generalizing Bayesian Optimization with Decision-theoretic Entropies. In Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022). ### Have you read the [Contributing Guidelines on pull requests](https://github.com/pytorch/botorch/blob/main/CONTRIBUTING.md#pull-requests)? Yes, I have read the Contributing Guidelines on pull requests. Pull Request resolved: #1794 Test Plan: (Write your test plan here. If you changed any code, please provide us with clear instructions on how you verified your changes work. Bonus points for screenshots and videos!) In the associated tutorial, two tests can be executed using the built-in 2D Ackley function with an input range of [-1, 1]. Within this range, there are four maxima located at each corner and one minimum at the center. The H-Entropy Search (HES) procedure, employing a Top-K (K = 2) loss function, is expected to identify two of the four maxima, with any combination being acceptable. Meanwhile, the H-Entropy Search procedure utilizing the MinMax loss function should locate one maximum and the central minimum. Below are the results after running 10 steps of HES with MinMax: 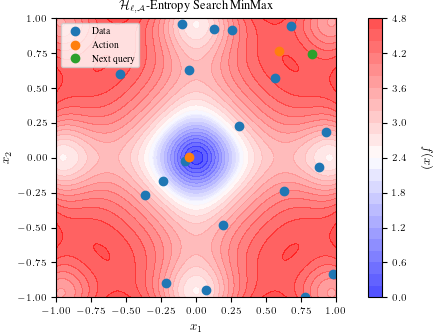 And here are the results after running 10 steps of HES with TopK: 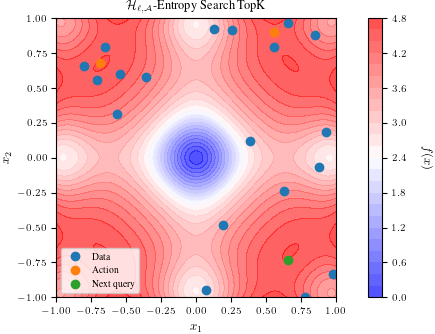 Both images can be reproduced by following the respective tutorial. ## Related PRs Not applicable. (If this PR adds or changes functionality, please take some time to update the docs at https://github.com/pytorch/botorch, and link to your PR here.) Reviewed By: esantorella Differential Revision: D46999676 Pulled By: saitcakmak fbshipit-source-id: 4486c7e55919a331ed8bca9e7f2029ac7eeed54a
{kind=link}
{kind=link}
- Loading branch information
1 parent
881c324
commit 9df7a40