Netflix Prize data was an open competition for the best collaborative filtering algorithm to predict user ratings for films, based on previous ratings without any other information about the users or films
- In this project, we calculate one person's rating for one movie he has not seem and make recommendation for top N movies for him.
- We use collaborative filtering based on the similarity between items calculated using people’s rating of those items.
- based on the user rating files for 100 movie, we generate a recommendation list for the user about top 5 movies for them to watch next.
- we predict user id 2351607 is recommend with the following movie in ascending order:
- Lilo and Stitch
- 7 Seconds
- Never Die Alone
- Mostly Martha
- What the #$*! Do We Know!?

- Pre-processing of Netflix raw data
- Data processing
- Build co-occurrence matrix
- Build rating matrix
- Generate top N recommend list for user based on his view history and rating
Netflix Prize data raw data has the following format:
MovieID:
UserID, Rating, Date
- Movie ID range from 1-17770
- Customer ID range from 1 to 2649429
- Rating from 1-5
- in this project, I don't take account of the dates.
For prove of concept, I first process the data so I only have user rating data from 100 movie, so my input is 100 files that has the following format
UserID, MovieID, Rating
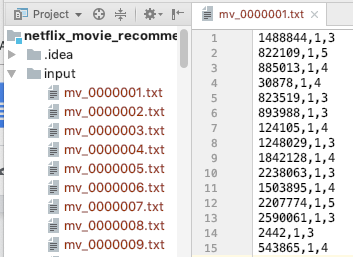
DataDividerByUser.java
- arg0: input path from pre-processed data (user rating data from 100 movies)
- arg1: output path job1
UserID movieID: rating, movieID: rating, movieID: rating
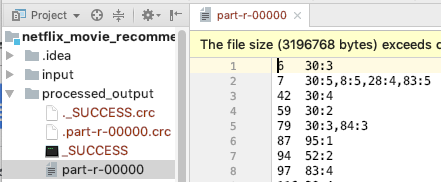
CoOccurrenceMatrixGenerator.java.
calculate number of time two movies are seem together.
- arg0: output path from job1
- arg1: output path for job2
movieID: movieID num_time_seem_together
ex: movieID_100 and movie_ID_1 has been seem together 8 times.
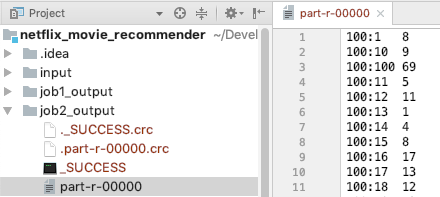
Multiplication.java
- From user’s rating for movie he has seen, predict his score on movies he hasn’t seem based on the relationship between the 2 movies.
- normalize the original input by multiply use rating matrix (original input) with co-occurence matrix (job2_output)
- For example:
- user rate movie_1 with rating “3”, movie_1 and movie_2 has co-occurance of 10 times.
- movie_2 has total occurance of 121.
- so for user1, the likelihood of watching movie_2 is 3*10 / 121
- For example:
- arg0: output from job2
- arg1: input for job1 (user rating file for 100 movies)
- arg2: output path for job3
- Build movieRelation map from ouput of job2
input:
movie_A:movie_B \t num_time_seem_together
output:
{ movie_1 : {movie_1, movie_2, num_time_seem_together}, {movie_1, movie_2, num_time_seem_together}}
- use movieRelationMap to build denominatorMap
{ movie_1, totalOccurance}
- mapper job to transform above output to
user_id:movie_id dividedScore
formula for divided score:
divided_score for user on movie_2= (user rating on movie_1) *(num of time movie_1 movie_2 co-ocuurence)/ (number of time movie 2 occure)
- reducer job to get sum
user_id movie_id:sum(dividedScore)
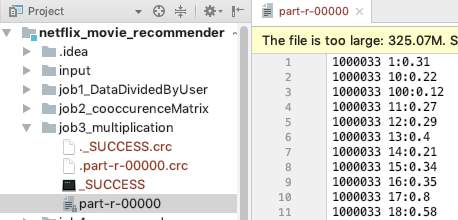
RecommenderListGenerator.java
get recommendation user about movie them have not seem
- args0: userRating.txt
userId, movieId, rating
- args1: movie_titles.txt
movieId, movieName
- args2: number of recommendation for this user
- args3:user movie relation (input from job3)
user_id movie_id:sum(dividedScore)
- args4:output path for this job
- args5:name of finalRecommendationResult
- Build a map for user id and list of movie he/she has seem (alreadyWatchedList)
- Filter out the alreadyWatchedList from output of job3
- Replace movieid with movieName
user_name, movieName:Rating
- Cumston comparator to return top N movie recommendation for user and their predicted rating for those recommended movie