
This is is the ribofinder pipeline from the Sequana project
| Overview: | Simple parallele workflow to detect and report ribosomal content |
|---|---|
| Input: | FastQ files |
| Output: | HTML reports |
| Status: | production |
| Citation: | Cokelaer et al, (2017), ‘Sequana’: a Set of Snakemake NGS pipelines, Journal of Open Source Software, 2(16), 352, JOSS DOI doi:10.21105/joss.00352 |
Using pip from Python, just install this package:
pip install sequana_ribofinder --upgrade
The --upgrade option is to make sure you'll get the latest version.
This pipeline scans input fastq.gz files found in the local directory and identify the proportion of ribosomal content.
For help, please type:
sequana_ribofinder --help
The following command searches for input files in DATAPATH. Then, te user provide a list of rRNA sequences in FastA format in test.fasta. This command creates a directory called ribofinder/ where a snakemake pipeline can:
sequana_ribofinder --input-directory DATAPATH --rRNA-file test.fasta
You will then need to execute the pipeline:
cd ribofinder sh ribofinder.sh # for a local run
This launch a snakemake pipeline. If you are familiar with snakemake, you can retrieve the pipeline itself and its configuration files and then execute the pipeline yourself with specific parameters:
snakemake -s ribofinder.rules -c config.yaml --cores 4 --wrapper-prefix git+file:////home/user/sequana_wrappers
Or use sequanix interface.
This pipelines requires the following executable(s):
- bowtie1 >= 1.3.0
- bedtools
- samtools
- bamtools
- pigz
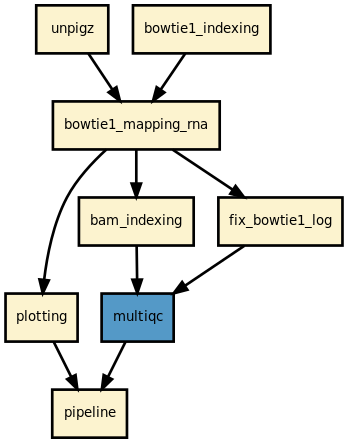
This pipeline runs ribofinder in parallel on the input fastq files. A brief sequana summary report is also produced.
You can start from the reference file and the GFF file. By default we search for the feature called rRNA to be found in the GFF file:
sequana_ribofinder --input-directory . --reference-file genome.fasta --gff-file genome.gff
If the default feature rRNA is not found, no error is raised for now. If you know the expected feature, you can provide it though:
sequana_ribofinder --input-directory . --reference-file genome.fasta --gff-file genome.gff --rRNA-feature gene_rRNA
If you have an existing or custom rRNA file, you can then use it as follows, in which case, no input reference is required:
sequana_ribofinder --input-directory . --rRNA-file ribo.fasta
Here is the latest documented configuration file to be used with the pipeline. Each rule used in the pipeline may have a section in the configuration file.
| Version | Description |
|---|---|
| 1.1.1 |
|
| 1.1.0 |
|
| 1.0.1 |
|
| 1.0.0 |
|
| 0.13.0 |
|
| 0.12.0 |
|
| 0.11.1 |
|
| 0.11.0 |
|
| 0.10.2 |
|
| 0.10.1 |
|
| 0.10.0 |
|
| 0.9.3 |
|
| 0.9.2 | First release. |