forked from trekhleb/javascript-algorithms
-
Notifications
You must be signed in to change notification settings - Fork 1
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Brazilian Portuguese translation and typos fixes (trekhleb#943)
* Update README.pt-BR.md * TRIE README.pt-BR typo * TREE README.pt-BR typo * Stack README.pt-BR typo * Priority Queue README.pt-BR typo * hash-table README.pt-BR typo * doubly-linked-list README.pt-BR typo * disjoint-set README.pt-BR typo * bloom-filter README.pt-BR typo * merge-sort pt-BR translation * merge-sort README added pt-BR option * insertion sort pt-BR translation * insertion sort README added pt-br option * heap-sort pt-BR translation * heap-sort READMED added pt-BR option * bubble sort pt-BR typo * pt-BR translation for sorting algorithms Fixed typos and translated all the missing algorithms * Update README.pt-BR.md * linked list pt-BR translation * ml pt-BR translation * fix typo in README Co-authored-by: Oleksii Trekhleb <[email protected]>
- Loading branch information
Showing
34 changed files
with
567 additions
and
145 deletions.
There are no files selected for viewing
Large diffs are not rendered by default.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
23 changes: 23 additions & 0 deletions
23
src/algorithms/linked-list/reverse-traversal/README.pt-BR.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,23 @@ | ||
| # Travessia de Lista Encadeada Reversa | ||
|
|
||
| _Leia isso em outros idiomas:_ | ||
| [_中文_](README.zh-CN.md), | ||
| [_English_](README.md) | ||
|
|
||
| A tarefa é percorrer a lista encadeada fornecida em ordem inversa. | ||
|
|
||
| Por exemplo, para a seguinte lista vinculada: | ||
|
|
||
|  | ||
|
|
||
| A ordem de travessia deve ser: | ||
|
|
||
| ```texto | ||
| 37 → 99 → 12 | ||
| ``` | ||
|
|
||
| A complexidade de tempo é `O(n)` porque visitamos cada nó apenas uma vez. | ||
|
|
||
| ## Referência | ||
|
|
||
| - [Wikipedia](https://en.wikipedia.org/wiki/Linked_list) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,24 @@ | ||
| # Travessia de Lista Encadeada | ||
|
|
||
| _Leia isso em outros idiomas:_ | ||
| [_Русский_](README.ru-RU.md), | ||
| [_中文_](README.zh-CN.md), | ||
| [_English_](README.md) | ||
|
|
||
| A tarefa é percorrer a lista encadeada fornecida em ordem direta. | ||
|
|
||
| Por exemplo, para a seguinte lista vinculada: | ||
|
|
||
|  | ||
|
|
||
| A ordem de travessia deve ser: | ||
|
|
||
| ```texto | ||
| 12 → 99 → 37 | ||
| ``` | ||
|
|
||
| A complexidade de tempo é `O(n)` porque visitamos cada nó apenas uma vez. | ||
|
|
||
| ## Referência | ||
|
|
||
| - [Wikipedia](https://en.wikipedia.org/wiki/Linked_list) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,35 @@ | ||
| # Algoritmo k-Means | ||
|
|
||
| _Leia isso em outros idiomas:_ | ||
| [_English_](README.md) | ||
|
|
||
| O **algoritmo k-Means** é um algoritmo de aprendizado de máquina não supervisionado. É um algoritmo de agrupamento, que agrupa os dados da amostra com base na semelhança entre as dimensões dos vetores. | ||
|
|
||
| Na classificação k-Means, a saída é um conjunto de classes atribuídas a cada vetor. Cada localização de cluster é continuamente otimizada para obter as localizações precisas de cada cluster de forma que representem cada grupo claramente. | ||
|
|
||
| A ideia é calcular a similaridade entre a localização do cluster e os vetores de dados e reatribuir os clusters com base nela. [Distância Euclidiana](https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/math/euclidean-distance) é usado principalmente para esta tarefa. | ||
|
|
||
|  | ||
|
|
||
| _Fonte: [Wikipedia](https://en.wikipedia.org/wiki/Euclidean_distance)_ | ||
|
|
||
| O algoritmo é o seguinte: | ||
|
|
||
| 1. Verifique se há erros como dados inválidos/inconsistentes | ||
| 2. Inicialize os locais do cluster `k` com pontos `k` iniciais/aleatórios | ||
| 3. Calcule a distância de cada ponto de dados de cada cluster | ||
| 4. Atribua o rótulo do cluster de cada ponto de dados igual ao do cluster em sua distância mínima | ||
| 5. Calcule o centroide de cada cluster com base nos pontos de dados que ele contém | ||
| 6. Repita cada uma das etapas acima até que as localizações do centroide estejam variando | ||
|
|
||
| Aqui está uma visualização do agrupamento k-Means para melhor compreensão: | ||
|
|
||
|  | ||
|
|
||
| _Fonte: [Wikipedia](https://en.wikipedia.org/wiki/K-means_clustering)_ | ||
|
|
||
| Os centroides estão se movendo continuamente para criar uma melhor distinção entre os diferentes conjuntos de pontos de dados. Como podemos ver, após algumas iterações, a diferença de centroides é bastante baixa entre as iterações. Por exemplo, entre as iterações `13` e `14` a diferença é bem pequena porque o otimizador está ajustando os casos limite. | ||
|
|
||
| ## Referências | ||
|
|
||
| - [k-Means neighbors algorithm on Wikipedia](https://en.wikipedia.org/wiki/K-means_clustering) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,44 @@ | ||
| # Algoritmo de k-vizinhos mais próximos | ||
|
|
||
| _Leia isso em outros idiomas:_ | ||
| [_English_](README.md) | ||
|
|
||
| O **algoritmo de k-vizinhos mais próximos (k-NN)** é um algoritmo de aprendizado de máquina supervisionado. É um algoritmo de classificação, determinando a classe de um vetor de amostra usando dados de amostra. | ||
|
|
||
| Na classificação k-NN, a saída é uma associação de classe. Um objeto é classificado por uma pluralidade de votos de seus vizinhos, com o objeto sendo atribuído à classe mais comum entre seus `k` vizinhos mais próximos (`k` é um inteiro positivo, tipicamente pequeno). Se `k = 1`, então o objeto é simplesmente atribuído à classe daquele único vizinho mais próximo. | ||
|
|
||
| The idea is to calculate the similarity between two data points on the basis of a distance metric. [Distância Euclidiana](https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/math/euclidean-distance) é usado principalmente para esta tarefa. | ||
|
|
||
|  | ||
|
|
||
| _Fonte: [Wikipedia](https://en.wikipedia.org/wiki/Euclidean_distance)_ | ||
|
|
||
| O algoritmo é o seguinte: | ||
|
|
||
| 1. Verifique se há erros como dados/rótulos inválidos. | ||
| 2. Calcule a distância euclidiana de todos os pontos de dados nos dados de treinamento com o ponto de classificação | ||
| 3. Classifique as distâncias dos pontos junto com suas classes em ordem crescente | ||
| 4. Pegue as classes iniciais `K` e encontre o modo para obter a classe mais semelhante | ||
| 5. Informe a classe mais semelhante | ||
|
|
||
| Aqui está uma visualização da classificação k-NN para melhor compreensão: | ||
|
|
||
|  | ||
|
|
||
| _Fonte: [Wikipedia](https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm)_ | ||
|
|
||
| A amostra de teste (ponto verde) deve ser classificada em quadrados azuis ou em triângulos vermelhos. Se `k = 3` (círculo de linha sólida) é atribuído aos triângulos vermelhos porque existem `2` triângulos e apenas `1` quadrado dentro do círculo interno. Se `k = 5` (círculo de linha tracejada) é atribuído aos quadrados azuis (`3` quadrados vs. `2` triângulos dentro do círculo externo). | ||
|
|
||
| Outro exemplo de classificação k-NN: | ||
|
|
||
| 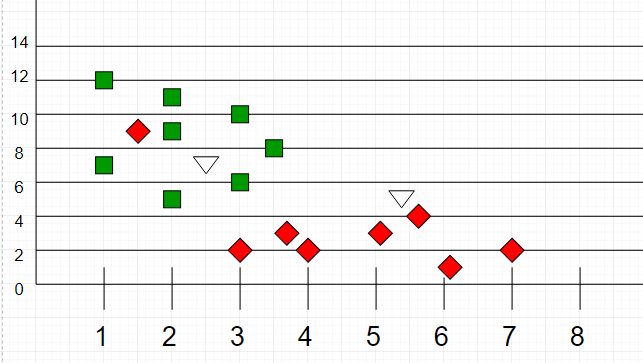 | ||
|
|
||
| _Fonte: [GeeksForGeeks](https://media.geeksforgeeks.org/wp-content/uploads/graph2-2.png)_ | ||
|
|
||
| Aqui, como podemos ver, a classificação dos pontos desconhecidos será julgada pela proximidade com outros pontos. | ||
|
|
||
| É importante notar que `K` é preferível ter valores ímpares para desempate. Normalmente `K` é tomado como `3` ou `5`. | ||
|
|
||
| ## Referências | ||
|
|
||
| - [k-nearest neighbors algorithm on Wikipedia](https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,70 @@ | ||
| # Counting Sort | ||
|
|
||
| _Leia isso em outros idiomas:_ | ||
| [_English_](README.md) | ||
|
|
||
| Em ciência da computação, **counting sort** é um algoritmo para ordenar | ||
| uma coleção de objetos de acordo com chaves que são pequenos inteiros; | ||
| ou seja, é um algoritmo de ordenação de inteiros. Ele opera por | ||
| contando o número de objetos que têm cada valor de chave distinto, | ||
| e usando aritmética nessas contagens para determinar as posições | ||
| de cada valor de chave na sequência de saída. Seu tempo de execução é | ||
| linear no número de itens e a diferença entre o | ||
| valores de chave máximo e mínimo, portanto, é adequado apenas para | ||
| uso em situações em que a variação de tonalidades não é significativamente | ||
| maior que o número de itens. No entanto, muitas vezes é usado como | ||
| sub-rotina em outro algoritmo de ordenação, radix sort, que pode | ||
| lidar com chaves maiores de forma mais eficiente. | ||
|
|
||
| Como a classificação por contagem usa valores-chave como índices em um vetor, | ||
| não é uma ordenação por comparação, e o limite inferior `Ω(n log n)` para | ||
| a ordenação por comparação não se aplica a ele. A classificação por bucket pode ser usada | ||
| para muitas das mesmas tarefas que a ordenação por contagem, com um tempo semelhante | ||
| análise; no entanto, em comparação com a classificação por contagem, a classificação por bucket requer | ||
| listas vinculadas, arrays dinâmicos ou uma grande quantidade de pré-alocados | ||
| memória para armazenar os conjuntos de itens dentro de cada bucket, enquanto | ||
| A classificação por contagem armazena um único número (a contagem de itens) | ||
| por balde. | ||
|
|
||
| A classificação por contagem funciona melhor quando o intervalo de números para cada | ||
| elemento do vetor é muito pequeno. | ||
|
|
||
| ## Algoritmo | ||
|
|
||
| **Passo I** | ||
|
|
||
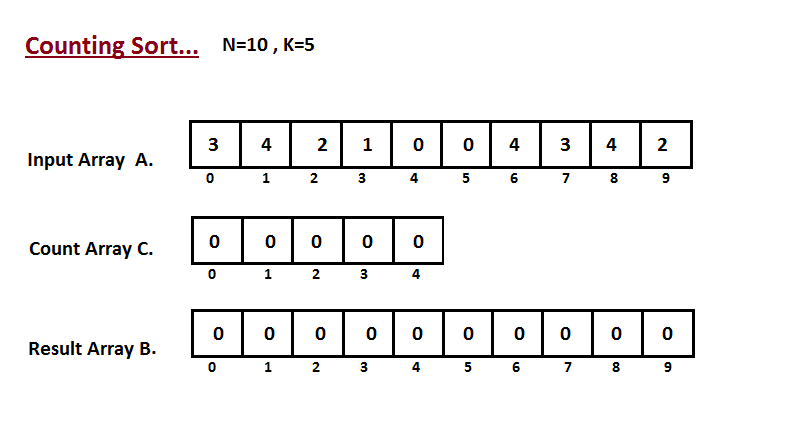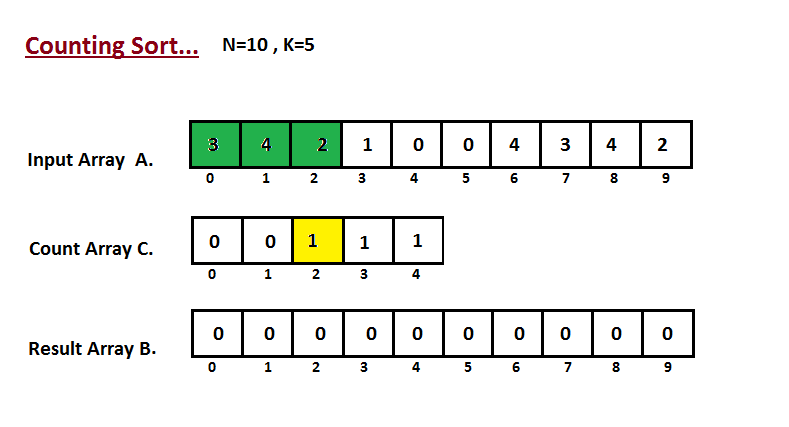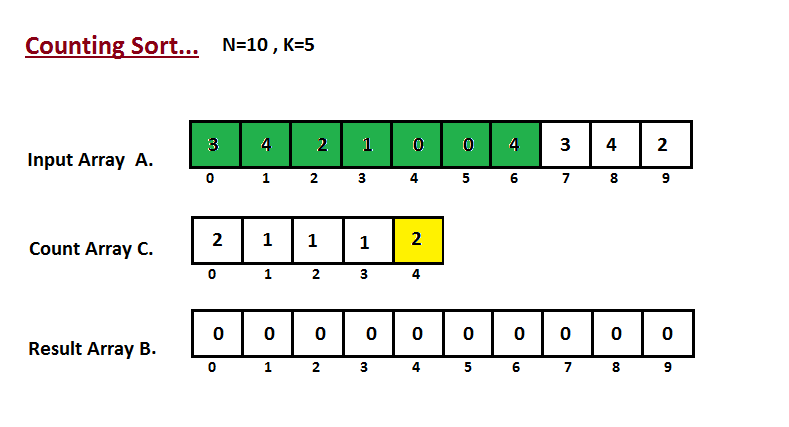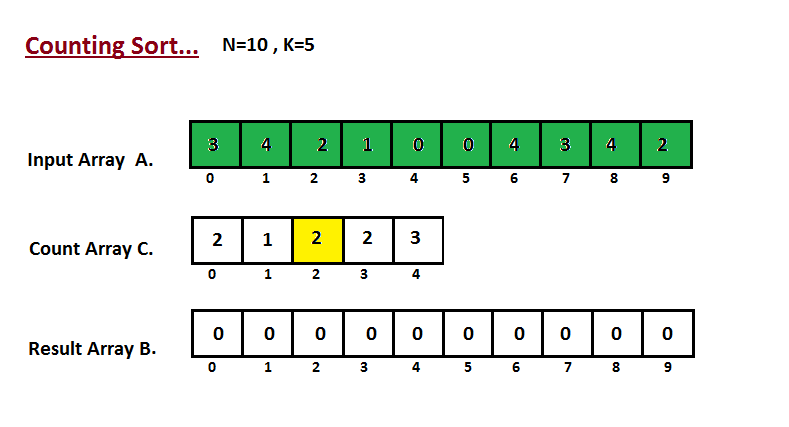
| Na primeira etapa, calculamos a contagem de todos os elementos do | ||
| vetor de entrada 'A'. Em seguida, armazene o resultado no vetor de contagem `C`. | ||
| A maneira como contamos é descrita abaixo. | ||
|
|
||
|  | ||
|
|
||
| **Passo II** | ||
|
|
||
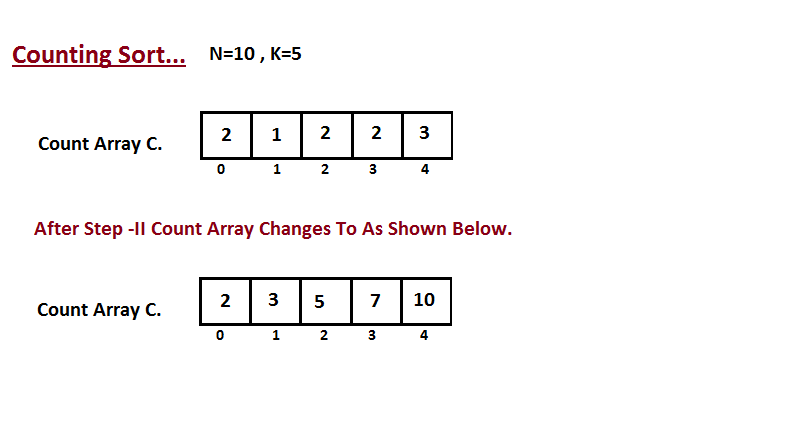
| Na segunda etapa, calculamos quantos elementos existem na entrada | ||
| do vetor `A` que são menores ou iguais para o índice fornecido. | ||
| `Ci` = números de elementos menores ou iguais a `i` no vetor de entrada. | ||
|
|
||
|  | ||
|
|
||
| **Passo III** | ||
|
|
||
| Nesta etapa, colocamos o elemento `A` do vetor de entrada em classificado | ||
| posição usando a ajuda do vetor de contagem construída `C`, ou seja, o que | ||
| construímos no passo dois. Usamos o vetor de resultados `B` para armazenar | ||
| os elementos ordenados. Aqui nós lidamos com o índice de `B` começando de | ||
| zero. | ||
|
|
||
| 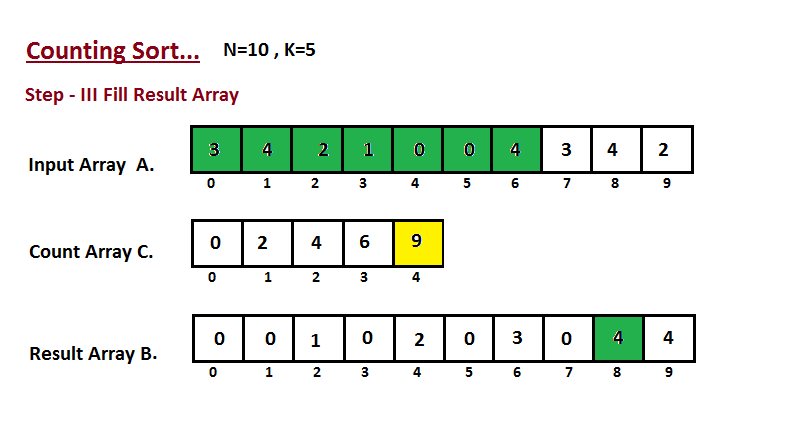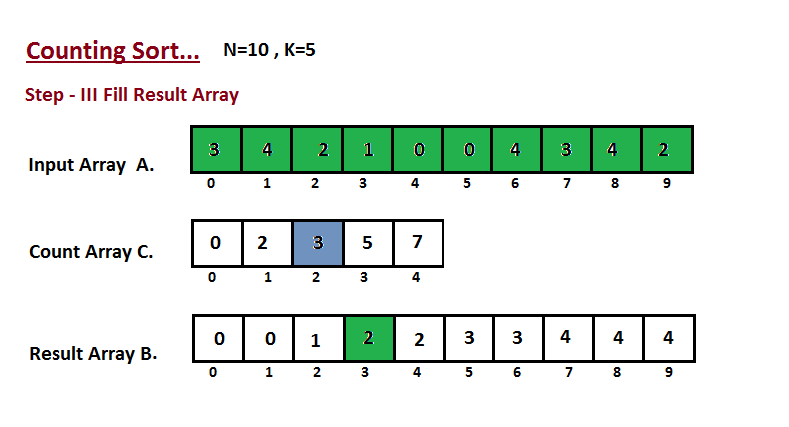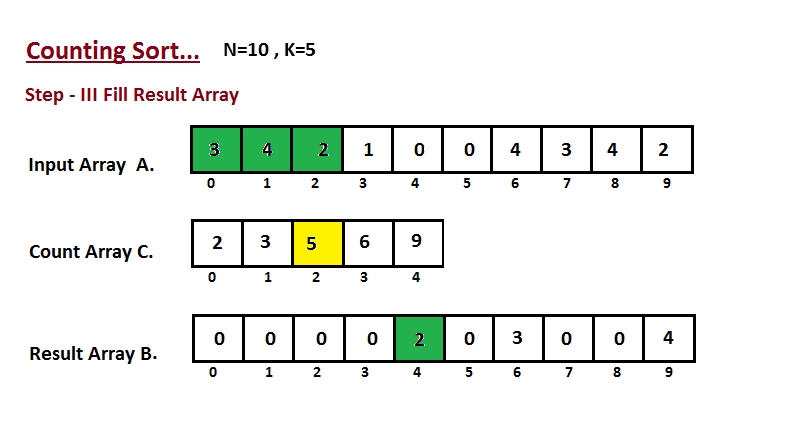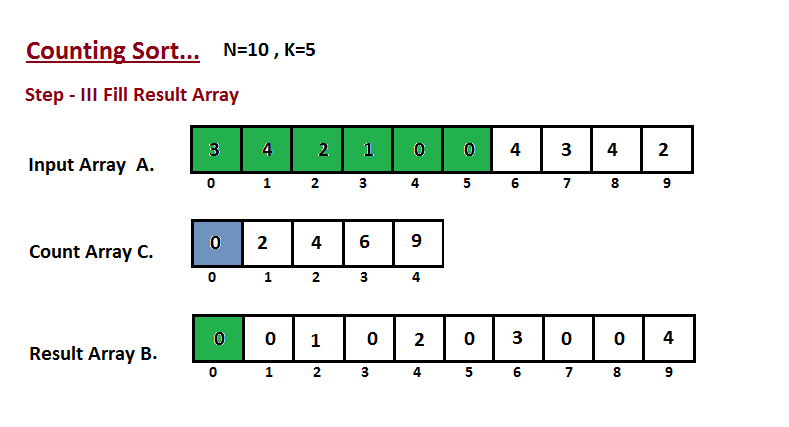 | ||
|
|
||
| ## Complexidade | ||
|
|
||
| | Nome | Melhor | Média | Pior | Memória | Estável | Comentários | | ||
| | --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- | | ||
| | **Counting sort** | n + r | n + r | n + r | n + r | Sim | r - Maior número no vetor | | ||
|
|
||
| ## Referências | ||
|
|
||
| - [Wikipedia](https://en.wikipedia.org/wiki/Counting_sort) | ||
| - [YouTube](https://www.youtube.com/watch?v=OKd534EWcdk&index=61&t=0s&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8) | ||
| - [EfficientAlgorithms](https://efficientalgorithms.blogspot.com/2016/09/lenear-sorting-counting-sort.html) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,20 @@ | ||
| # Heap Sort | ||
|
|
||
| _Leia isso em outros idiomas:_ | ||
| [_English_](README.md) | ||
|
|
||
| Heapsort é um algoritmo de ordenação baseado em comparação. O Heapsort pode ser pensado como uma seleção aprimorada sort: como esse algoritmo, ele divide sua entrada em uma região classificada e uma região não classificada, e iterativamente encolhe a região não classificada extraindo o maior elemento e movendo-o para a região classificada. A melhoria consiste no uso de uma estrutura de dados heap em vez de uma busca em tempo linear para encontrar o máximo. | ||
|
|
||
|  | ||
|
|
||
|  | ||
|
|
||
| ## Complexidade | ||
|
|
||
| | Nome | Melhor | Média | Pior | Memória | Estável | Comentários | | ||
| | --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- | | ||
| | **Heap sort** | n log(n) | n log(n) | n log(n) | 1 | Não | | | ||
|
|
||
| ## Referências | ||
|
|
||
| [Wikipedia](https://en.wikipedia.org/wiki/Heapsort) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,22 @@ | ||
| # Insertion Sort | ||
|
|
||
| _Leia isso em outros idiomas:_ | ||
| [_English_](README.md) | ||
|
|
||
| A ordenação por inserção é um algoritmo de ordenação simples que criaa matriz classificada final (ou lista) um item de cada vez. | ||
| É muito menos eficiente em grandes listas do que mais algoritmos avançados, como quicksort, heapsort ou merge | ||
| ordenar. | ||
|
|
||
|  | ||
|
|
||
|  | ||
|
|
||
| ## Complexidade | ||
|
|
||
| | Nome | Melhor | Média | Pior | Memória | Estável | Comentários | | ||
| | --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- | | ||
| | **Insertion sort** | n | n<sup>2</sup> | n<sup>2</sup> | 1 | Sim | | | ||
|
|
||
| ## Referências | ||
|
|
||
| [Wikipedia](https://en.wikipedia.org/wiki/Insertion_sort) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,38 @@ | ||
| # Merge Sort | ||
|
|
||
| _Leia isso em outros idiomas:_ | ||
| [_한국어_](README.ko-KR.md), | ||
| [_English_](README.md) | ||
|
|
||
| Em ciência da computação, merge sort (também comumente escrito | ||
| mergesort) é uma ferramenta eficiente, de propósito geral, | ||
| algoritmo de ordenação baseado em comparação. A maioria das implementações | ||
| produzir uma classificação estável, o que significa que a implementação | ||
| preserva a ordem de entrada de elementos iguais na ordenação | ||
| resultado. Mergesort é um algoritmo de divisão e conquista que | ||
| foi inventado por John von Neumann em 1945. | ||
|
|
||
| Um exemplo de classificação de mesclagem. Primeiro divida a lista em | ||
| a menor unidade (1 elemento), então compare cada | ||
| elemento com a lista adjacente para classificar e mesclar o | ||
| duas listas adjacentes. Finalmente todos os elementos são ordenados | ||
| e mesclado. | ||
|
|
||
|  | ||
|
|
||
| Um algoritmo de classificação de mesclagem recursivo usado para classificar uma matriz de 7 | ||
| valores inteiros. Estes são os passos que um ser humano daria para | ||
| emular merge sort (top-down). | ||
|
|
||
|  | ||
|
|
||
| ## Complexidade | ||
|
|
||
| | Nome | Melhor | Média | Pior | Memória | Estável | Comentários | | ||
| | --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- | | ||
| | **Merge sort** | n log(n) | n log(n) | n log(n) | n | Sim | | | ||
|
|
||
| ## Referências | ||
|
|
||
| - [Wikipedia](https://en.wikipedia.org/wiki/Merge_sort) | ||
| - [YouTube](https://www.youtube.com/watch?v=KF2j-9iSf4Q&index=27&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.