


Обгортку проєкту згенеровано з допомогою Copilot у Windows, оригінал зображення обгортки знаходиться тут.
Україномовний Telegram чат-бот з використанням штучного інтелекту. Цей проєкт базується на LLM Studio, яка працює як сервер для великої мовної моделі LLAMA3 8B від компанії META. Саме вона займається обробкою користувацьких повідомлень та генерацією токенів(відповідей) чат-боту.
Цей чат-бот може як генерувати текстові, так і аудіоповідомленя українською мовою. Синтез та розпізнавання мовлення реалізовано за допомогою бібліотек для Python від Google:
- SpeechRecognition: https://pypi.org/project/SpeechRecognition/
- gTTS (Google Text-to-Speech): https://pypi.org/project/gTTS/
В якості інтерфейсу взаємодії з штучним інтелектом, я використав меседжер Telegram, це зручно тому, що маєш доступ з сматфону до свого власного ШІ в любому місці, де є інтернет.
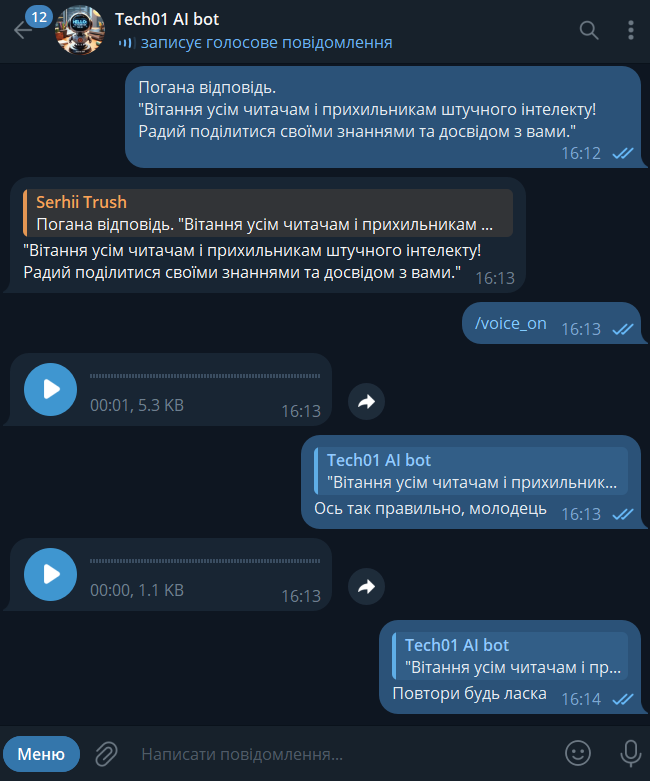
Ось посилання на Telegram API: https://core.telegram.org/bots/api
Для роботи з Telegram API використовується бібліотека pyTelegramBotAPI: https://pypi.org/project/pyTelegramBotAPI/
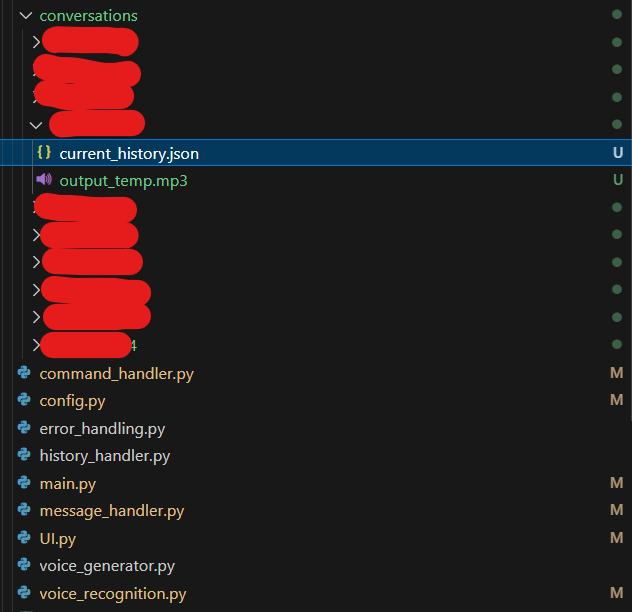
Контекст розмови, а саме вміст змінної history у файлі message_handler.py(переписки з чат ботом) зберігається в JSON форматі(каталог conversations/id_Telegram_користувача/current_history.json) на диск, щоб навіть після перезавантаження скрипта бот "пам'ятав" про що Ви розмовляли з ним раніше.
Для реалізації читання структури JSON використана стандартна бібліотека: https://docs.python.org/uk/3/library/json.html
Для роботи з великою мовною моделью використовується 2 елементи програмного забезпечення, а саме бібліотека від OpenAI, яка в свою чергу взаємодіє з LLM Studio.
- Працювати з API від OpenAI на мові Python можна з використаннім бібліотеки, ось посилання: https://pypi.org/project/openai/ Ця бібліотека має широкий функціонал для роботи з ШІ, за цю зручність я вибрав її для свого проєкту чат-боту. Хоча вона і призначена для роботи з продуктами компанії OpenAI, але її також можна використовувати для інших проєктів, наприклад LLM Studio.
- LLM Studio - зручний інструмент з графічним інтерфейсом(GUI), він крорисний для старту роботи з великими мовними моделями(LLM), ось тут можна скачати під Вашу операційну систему: https://lmstudio.ai/
У цьому проєкті використовуються кілька ключових бібліотек, ось вони:
- telebot == 0.0.5
- openai == 1.33.0
- gTTS == 2.5.1
- SpeechRecognition == 3.10.4
- pydub == 0.25.1
Для початку встановлюємо Python https://www.python.org/downloads/
Потім для роботи бібліотеки(окрім самої бібліотеки) pydub необхідно встановити FFmpeg, ось як його встановити: https://www.editframe.com/guides/how-to-install-and-start-using-ffmpeg-in-under-10-minutes
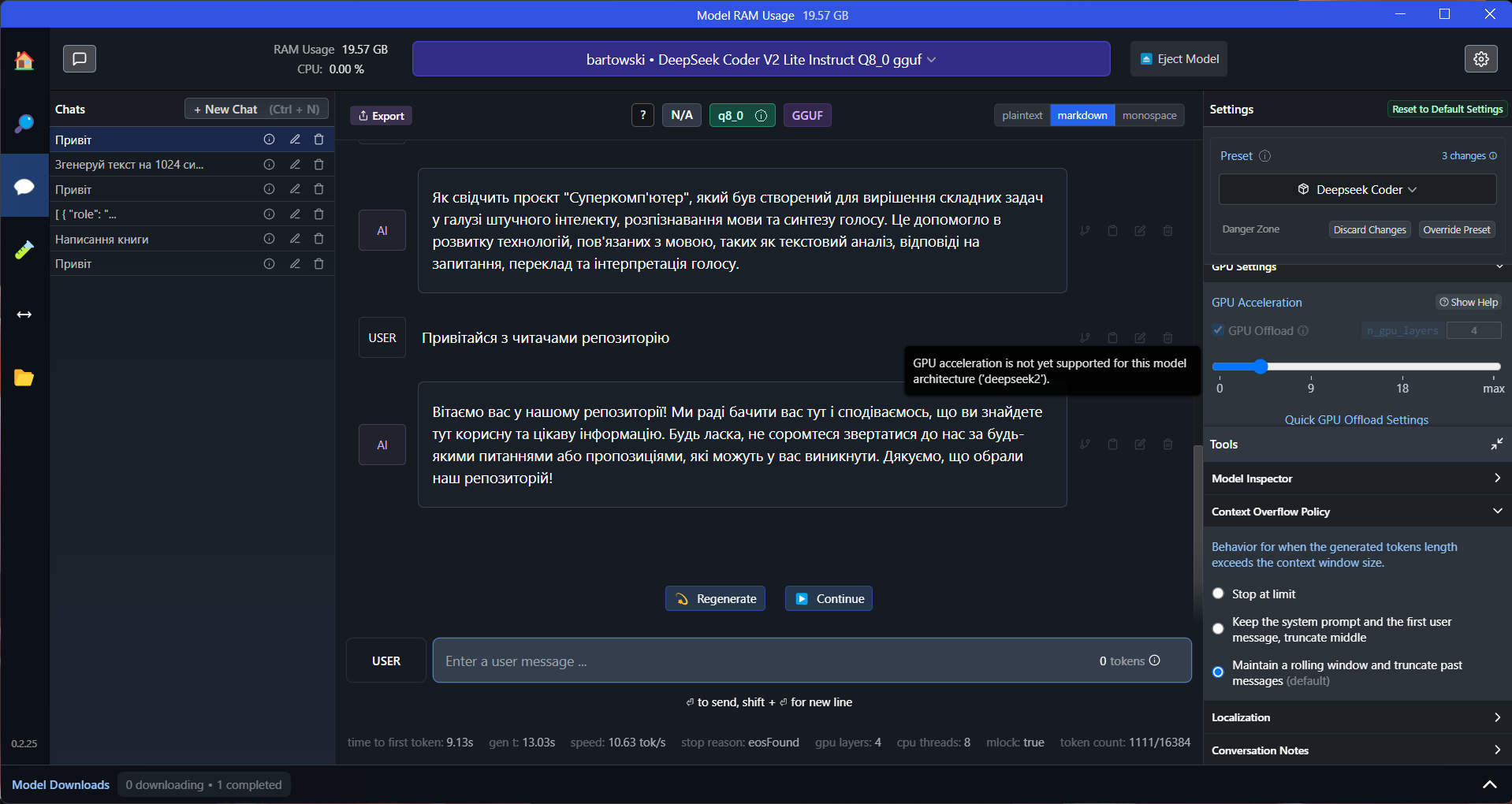
Після встановлення LLM Studio треба скачати LLM, для свого проєкту, в якості ШІ, я використав LLAMA3 на 8 мільярдів параметрів(8B) від компанії META: https://llama.meta.com/llama3/
Щоб встановити велику мовну модель в свою систему потрібно її скачати в LLM Studio, для цього робимо наступні кроки:
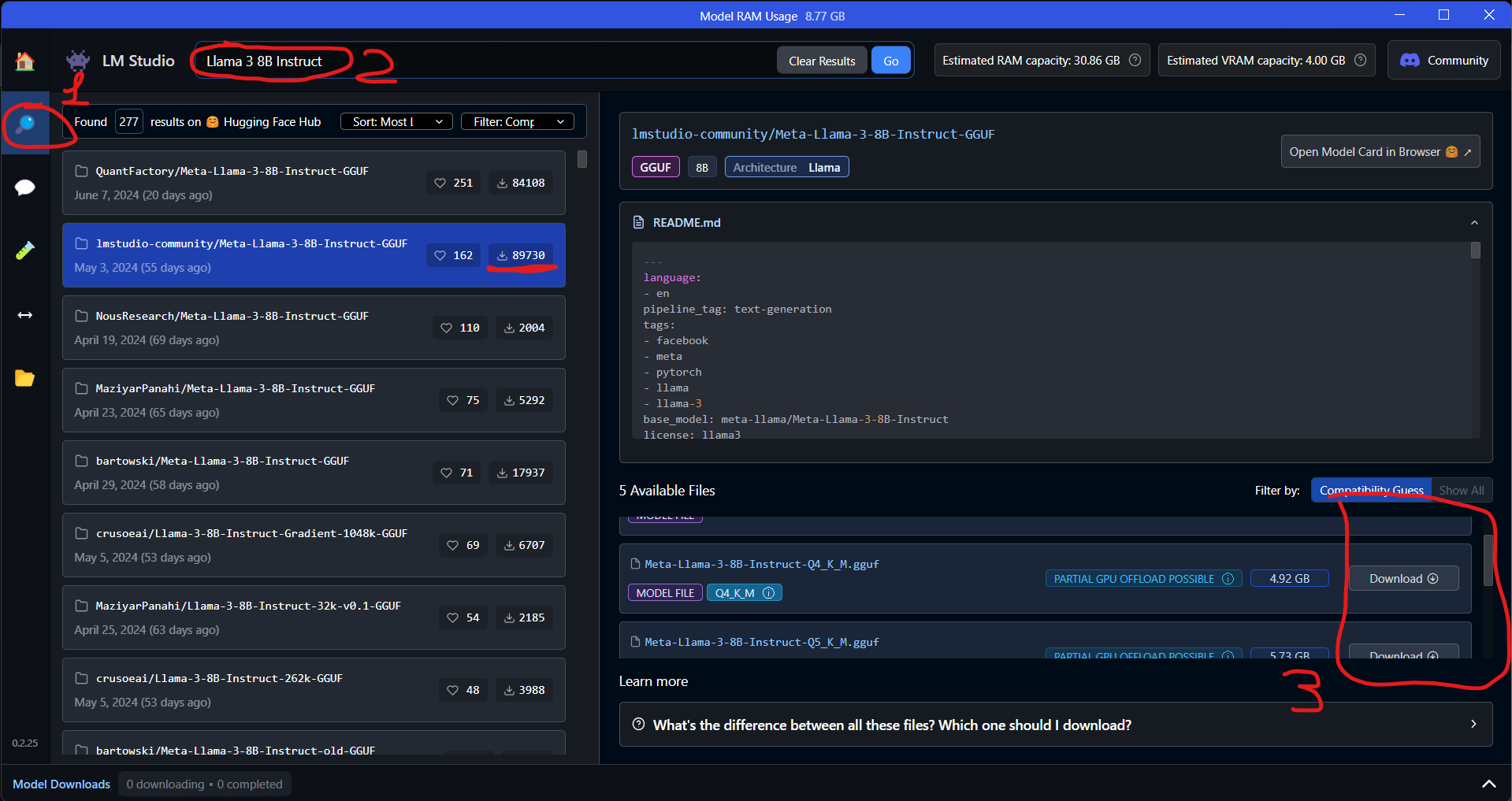
- Натискаємо кнопку пошуку.
- Пишемо у полі пошуку назву потрібної LLM, у моєму випадку це
Llama 3 8B Instruct - Скачуємо. Доступні різні версії квантування(стиснення інформації яка зберігається в LLM), пропоную почати з
Q4_K_M- золота середина між швидкодією та якістю відповідей. Для більш продуктивніших комп'ютерів є "Q8" або "fp32" версії.
Після завантаження великої мовної моделі тиснемом кнопку Local Server - запускаємо сервер, який забезпечить можливість "спілкуватись" з LLM використовуючи локальний сервер за адресою http://localhost:1234/v1 або http://localhost:1234/v1/chat/completions.
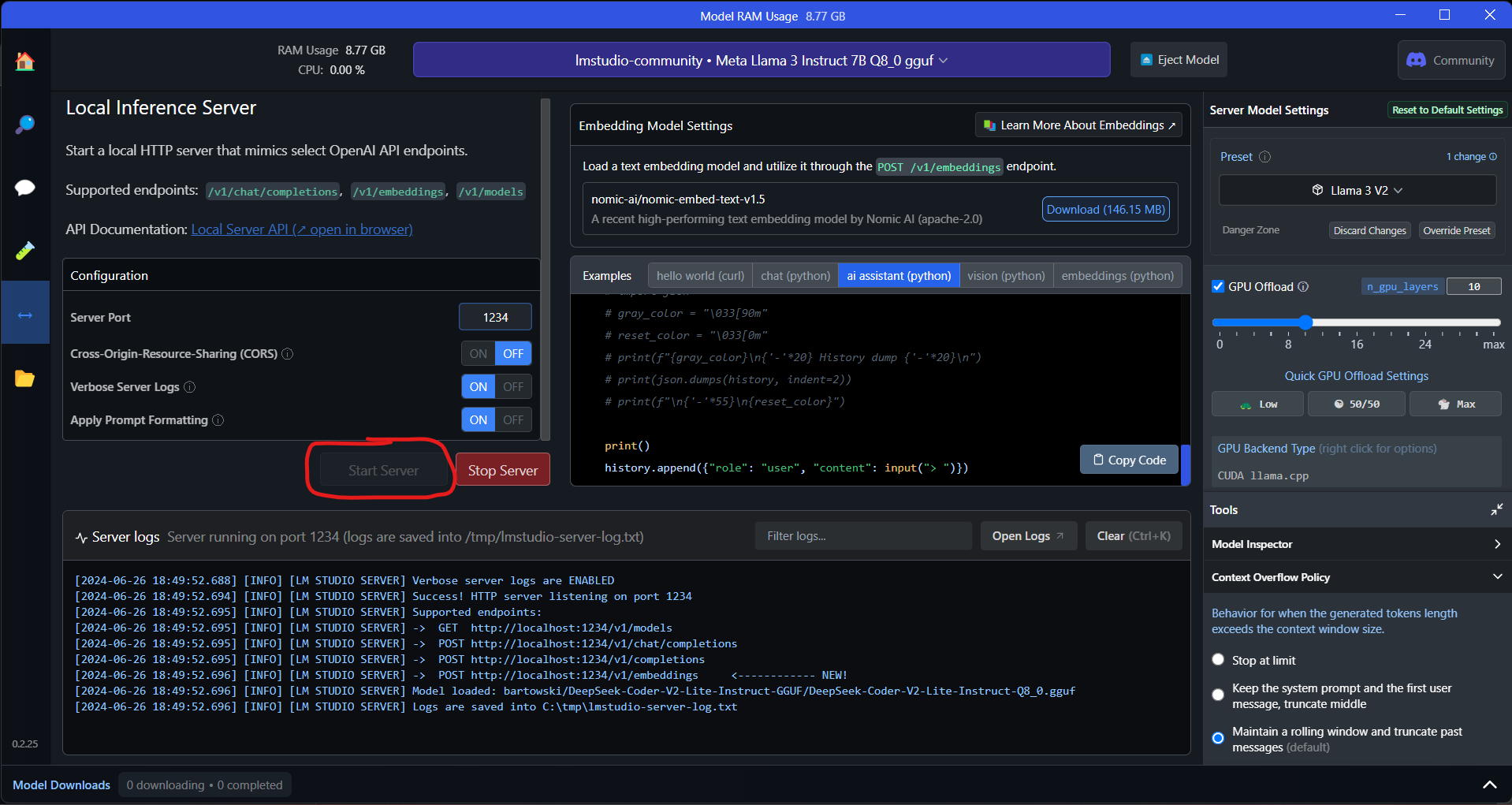
Після налаштування програмного забезпечення потрібно отримати API-ключ, ось чудова стаття як це можна зробити: https://www.freecodecamp.org/news/how-to-create-a-telegram-bot-using-python/

Наступним кроком є прописати API-ключ, який отримали від @botfather в коді файлу config.py або для зручності можна всі параметри можна ввести виконавши скрипт ui.py.
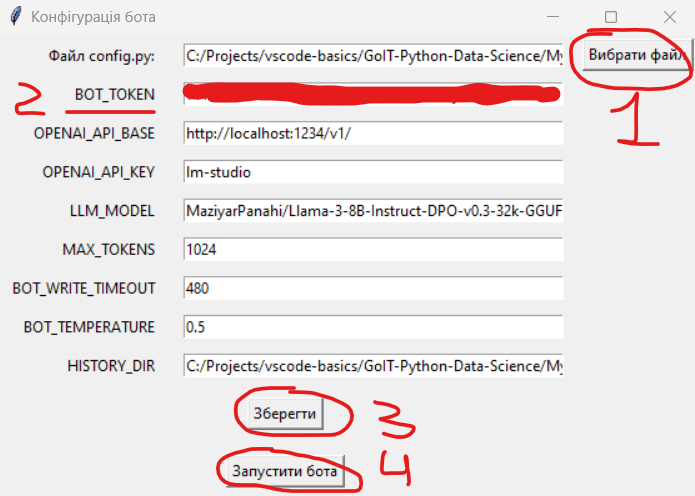
- Відкрити файл
config.pyтим самим задавши абсолютну адресу до робочого каталогу з проєктом. - Скопіювати API-ключ(змінити розкладку клавіатури на "eng", це важливо). А також важливо у поле
HISTORY_DIRскопіювати абсолютний шлях до каталогуconversations, наприкладC:\Projects\TelegramAIChatbot\conversations\. - Зберегти конфігурацію у файл
config.pyнатиснувши кнопку. - Запустити бота з кнопки а не виконавши головний скрипт. Після цього Telegram чат-бот виконає файл
main.pyі все повинно запрацювати - можете написати своєму чат-боту українською мовою.
Проєкт складається з декількох модулів, кожен з яких розділяє окремий функціонал, це зроблено для зручності обслуговування коду в майбутньому. Проєкт має наступну структуру:
-
ui.py - Модуль графічного інтерфейсу(GUI) для конфігурування та запуску чат-боту.
-
main.py - Головний модуль, котрий ініціалізує Telegram бота та всі інші модулі. Для запуску бота виконайте цей файл командою
python main.pyабоpython3 main.py. -
config.py - Модуль який містить конфігурації для чат боту, такі як API-ключ, шлях до каталогу з історією, температура віповідей, кількість токенів для відповіді та інше.
-
command_handler.py - Модуль обробки користувацьких команд, таких як увімкнення та вимкнення голосового режиму(аудіоповідомлень), старт нової бесіди(очищення файлу з історією), команда перекладу ботом тексту з англійської на українську мову.
-
error_handling.py - Модуль у якому відбувається логування помилок.
-
history_handler.py - Модуль, для роботи(завантаження та збереження) користувацької переписки, іншими словами історії чату. Використовується ID користувача Telegram для розділення розмов користувачів. Тобто один користувач - окрема історія спілкування. Переписка зберігається за наступним каталогом
conversations/id_Telegram_користувача/у файлcurrent_history.json. -
message_handler.py - Модуль, обробки повідомлень від великої мовної моделі. Використовується бібліотека від OpenAI
-
voice_generator.py - Модуль, у якому відбувається генерація тексту(відповіді від LLM) у мовлення(TTS) українською мовою. Також там для конвертації OGG у WAV використовується бібліотека pydub https://pypi.org/project/pydub/
-
voice_recognition.py - Модуль, де виконуються функції розпізнавання мовлення(з аудіо в текст), українською мовою, для подальної передачі тексту у велику мовну модель, яка у свою чергу генеруватиме відповідь користувачеві.
Спасибі ChatGPT за асистування розробки проєкту.