Correctly decode tszip cols#213
Merged
benjeffery merged 2 commits intotskit-dev:mainfrom Oct 24, 2024
Merged
Conversation
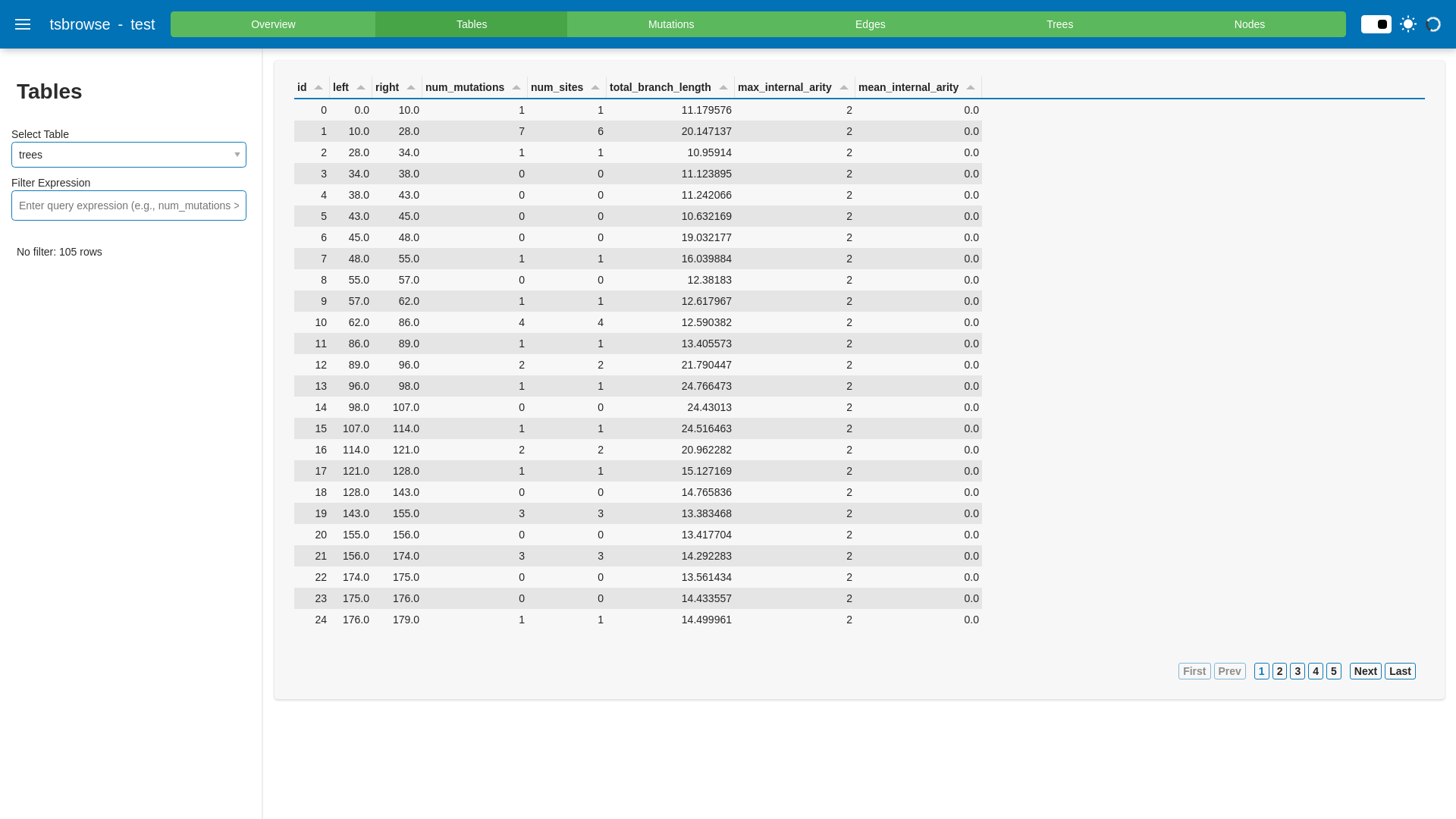
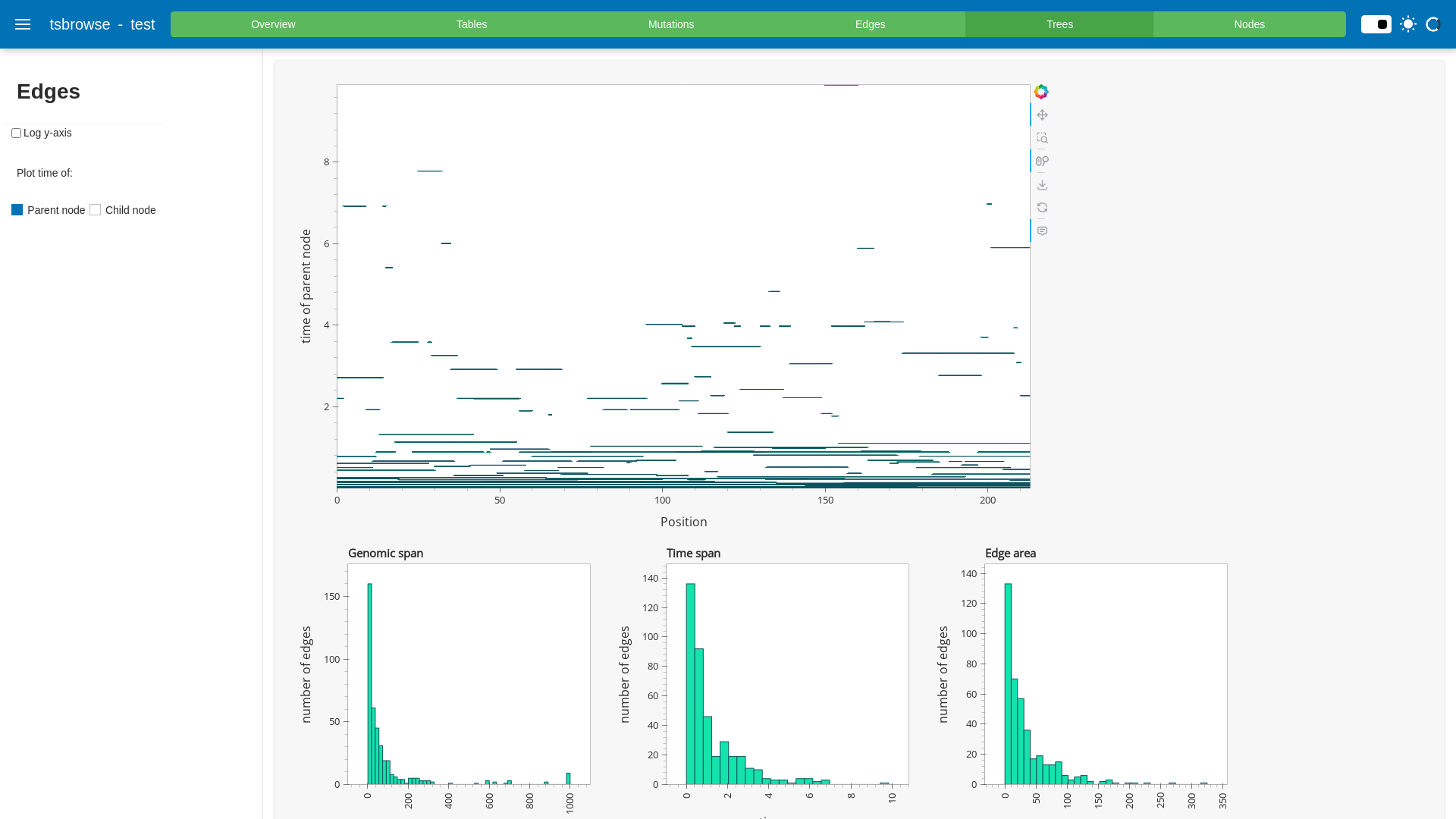
Automated ScreenshotsThese screenshots are automatically updated as the PR changes. Click to view screenshotsedges.png
mutations-popup.png
mutations.png
nodes.png
out_edges.png
out_mutations.png
out_nodes.png
overview.png
tables.png
trees.png
|
Pull Request Test Coverage Report for Build 11497469628Details
💛 - Coveralls |
Member
There was a problem hiding this comment.
I don't understand why we need to do this tbh - shouldn't we let tszip handle this? If we do
ts = tszip.load(tsbrowse_path)
root = zarr.open(tsbrowse_path)
# e.g.
edges_df = {
"left": ts.edges_left,
"right": ts.edges_right,
...
"extra_col_1": root["edges"]["extra_col_1"]
}
then we let tszip deal with these details, and we don't become depending on an implementation detail of tszip?
| "migrations", | ||
| "provenances", | ||
| ]: | ||
| ts_table = getattr(self.ts.tables, table_name) |
Member
There was a problem hiding this comment.
That's generating a fresh copy of the tables each time. Get a reference to the tables before the loop body
fabcea2 to
8d4cf4c
Compare
jeromekelleher
approved these changes
Oct 24, 2024
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
3 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Fixes #190
Fixed other odd columns too and added tests for all columns.