![]()
Command-line interface that enables interactive chat with LLMs.
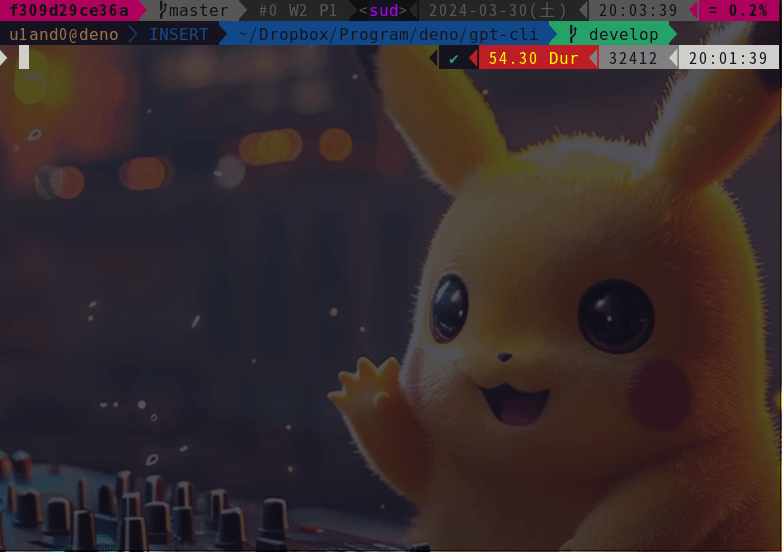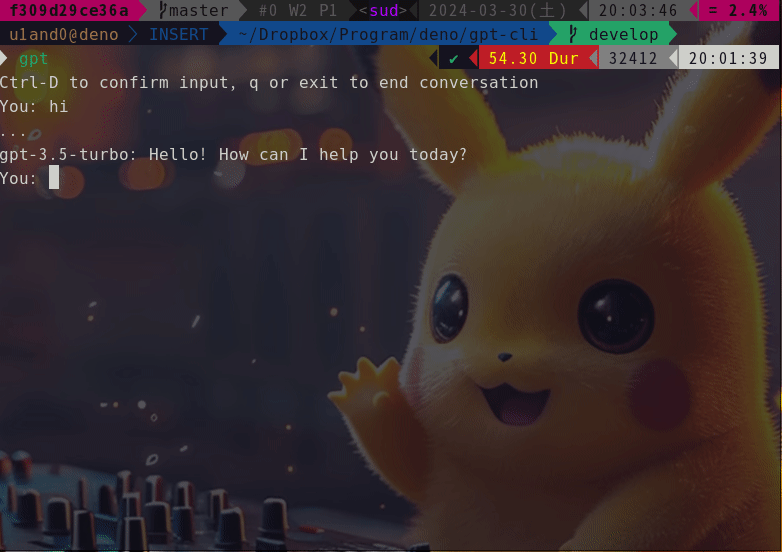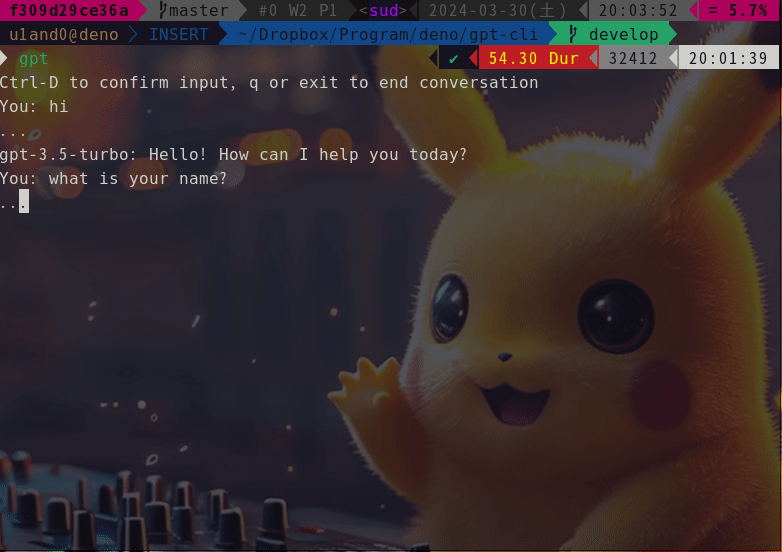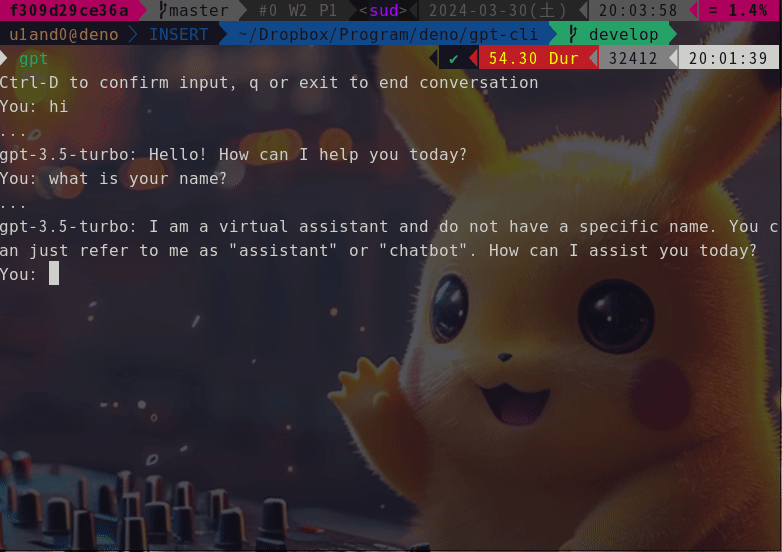
# Install binary
$ bash -c "$(curl -fsSL https://raw.githubusercontent.com/u1and0/gpt-cli/refs/heads/main/install.sh)"
$ sudo ln -s ./release-package/gpt /usr/bin
# Setup API key
$ export OPENAI_API_KEY='sk-*****'
# Run
$ gpt
Ctrl-D to confirm input, q or exit to end chat
You: hi
...
gpt-4o-mini: Hello! How can I assist you today?
You:
However, the API key must be set to an environment variable in advance.
$ gpt -n "hi"
Hello! How can I assist you today?
$ echo "hi" | gpt
Hello! How can I assist you today?
Forced output in single mode. (It does not shift to conversation mode.)
For practical examples of how to integrate gpt-cli with other command-line tools, see the example.md file.
This demonstrates piping data from tools like ddgr, w3m, jq, and others into gpt-cli for enhanced analysis and processing.
You have 3 options.
The simplest way.
$ bash -c "$(curl -fsSL https://raw.githubusercontent.com/u1and0/gpt-cli/refs/heads/main/install.sh)"
$ sudo ln -s ./release-package/gpt /usr/bin
$ gpt -v
Almost same command here.
$ curl -LO https://github.com/u1and0/gpt-cli/releases/download/v0.9.5/gpt-cli-linux-x64.zip
$ unzip gpt-cli-linux-x64.zip
$ sudo ln -s ./release-package/gpt /usr/bin
$ gpt -v
gpt-cli-macos.zip and gpt-cli-windows.zip are also available. Try to switch zip file name.
Required deno
Create link on your path like ~/.deno/bin using deno install.
$ git clone https://github.com/u1and0/gpt-cli
$ cd gpt-cli
$ deno install -f --allow-net --allow-env --allow-read --name gpt gpt-cli.ts
$ export PATH=$PATH:~/.deno/bin
$ bash -l
Required deno
Create binary by deno compile.
$ git clone https://github.com/u1and0/gpt-cli
$ cd gpt-cli
$ deno compile --allow-net --allow-env --allow-read --output gpt gpt-cli.ts
$ sudo ln -s ./release-package/gpt /usr/bin
Get OpenAI API key, then set environment argument.
export OPENAI_API_KEY='sk-*****'
Get Anthropic API key, then set environment argument.
export ANTHROPIC_API_KEY='sk-ant-*****'
Get Google API key, then set environment argument.
export GOOGLE_API_KEY='*****'
Get XAI API key, then set environment argument.
export XAI_API_KEY='*****'
Get Groq API key, then set environment argument.
export GROQ_API_KEY='*****'
Get Together AI API key, then set environment argument.
export TOGETHER_AI_API_KEY='*****'
Get Fireworks API key, then set environment argument.
export FIREWORKS_API_KEY='*****'
Get MistralAI API key, then set environment argument.
export MISTRAL_API_KEY='*****'
Get Replicate API token, then set environment argument.
export REPLICATE_API_TOKEN='*****'
- Setup Ollama, see github.com/ollama/ollama
- Download ollama model such as
ollama pull modelName - Start ollama
ollama serveon your server.
$ gpt -m gpt-4o-mini -x 8192 -t 1.0 [OPTIONS] PROMPT
| short option | long option | type | description |
|---|---|---|---|
| -v | --version | boolean | Show version |
| -h | --help | boolean | Show this message |
| -m | --model | string | LLM model (default gpt-4o-mini) |
| -x | --max_tokens | number | Number of AI answer tokens (default 8192) |
| -t | --temperature | number | Higher number means more creative answers, lower number means more exact answers (default 1.0) |
| -u | --url | string | URL and port number for ollama server |
| -s | --system-prompt | string | The first instruction given to guide the AI model's response. |
| -f | --file | string | Attachment file path. The Glob pattern can be used. (Such as ./test/*.ts) |
| -n | --no-chat | boolean | No chat mode. Just one time question and answer. |
A Questions for Model. Using regular expressions to match and generate the appropriate LLM instance allows you to use new models in 0 days after a new API is released.
- OpenAI
- gpt-4o-mini
- gpt-4o
- o1-mini
- o1
- o3-mini...
- Anthropic
- claude-3-7-sonnet-latest
- claude-3-5-sonnet-20241022
- claude-3-5-sonnet-latest
- claude-3-opus-20240229
- claude-3-haiku-20240307
- Gemini
- gemini-2.5-pro-exp-03-25
- gemini-2.0-flash...
- gemini-2.0-flash-thinking-exp...
- Gemma
- gemma-3-27b-it...
- Grok
- grok-3-latest
- grok-2-latest
- grok-2-1212
- Groq
- groq/llama3.1-70b-specdec
- groq/llama-3.3-70b-specdec
- groq/deepseek-r1-distill-qwen-32b
- groq/deepseek-r1-distill-llama-70b
- TogetherAI
- togetherai/deepseek-ai/DeepSeek-R1
- togetherai/deepseek-ai/DeepSeek-R1-Distill-Llama-70B-free
- togetherai/meta-llama/Llama-3.3-70B-Instruct-Turbo-Free
- togetherai/Qwen/QwQ-32B-Preview
- togetherai/meta-llama/Llama-3.1-405B-Instruct-Turbo
- togetherai/google/gemma-2-27b-it
- togetherai/mistralai/Mistral-7B-Instruct-v0.3...
- Fireworks
- fireworks/accounts/fireworks/models/deepseek-r1
- fireworks/accounts/fireworks/models/llama-v3p1-405b-instruct
- fireworks/accounts/fireworks/models/deepseek-v3
- MistralAI
- mistralai/codestral-latest
- mistralai/mistral-large-latest
- mistralai/mistral-small-latest
- Replicate
- replicate/deepseek-ai/deepseek-r1
- replicate/meta/meta-llama-3-70b-instruct
- replicate/mistralai/mixtral-8x7b-instruct-v0.1
- replicate/snowflake/snowflake-arctic-instruct
- replicate/replicate/flan-t5-xl...
- Ollama Use before
$ ollama servelocally- ollama/phi4
- ollama/llama3.3:70b
- ollama/mixtral:8x7b-text-v0.1-q5_K_M...
Help (/commands):
- /?, /help Help for a command
- /clear Clear session context
- /modelStack Show model's history
- /bye,/exit,/quit Exit
Help (@commands): Change model while asking.
- @ModelName Change LLM model
- ex) @gemini-1.5-pro your question...
$ deno test --allow-env --allow-read --allow-write
See gpt-cli/test
This is a Vimmer-only option. This option brings a Github Copilot-like experience to your Vim.
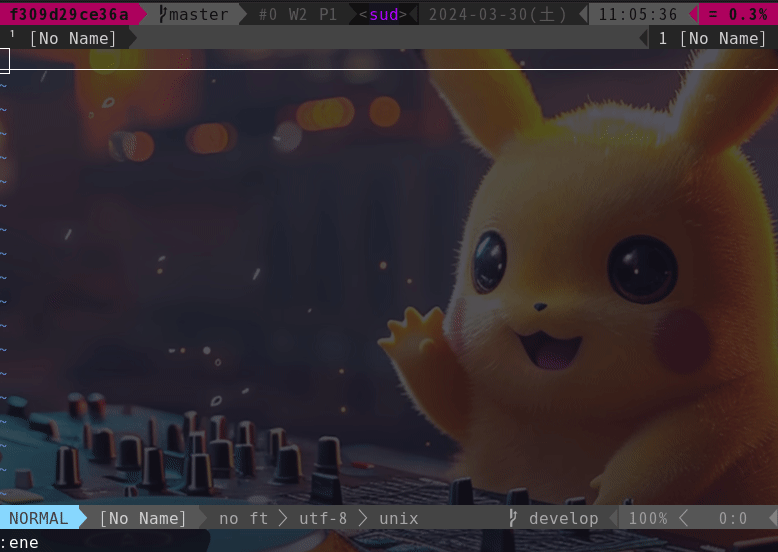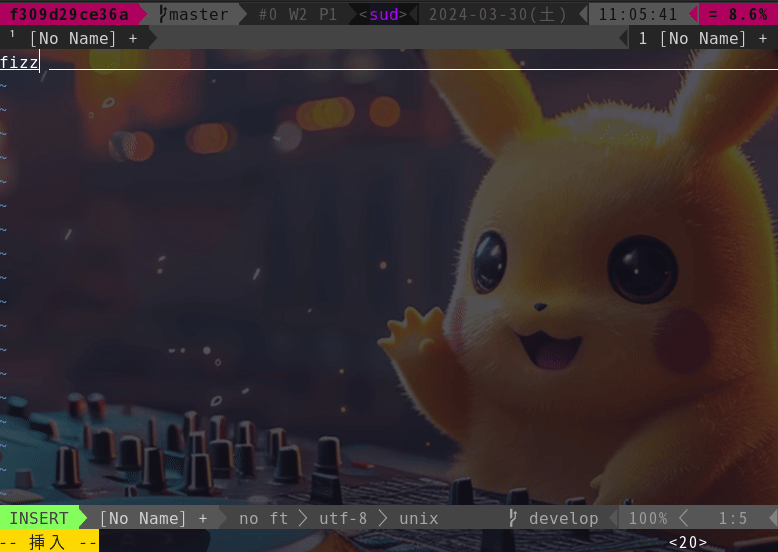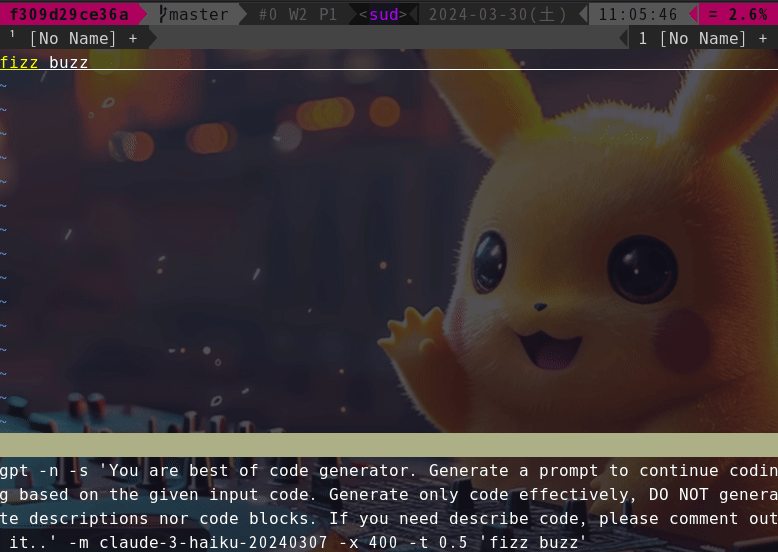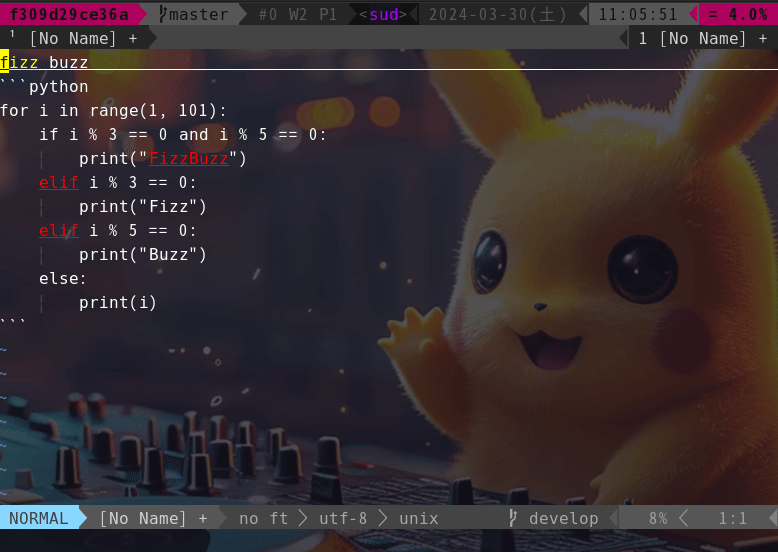
For example, if you want to manage plug-ins with dein, write a toml file like this.
[[plugins]]
repo = 'u1and0/gpt-cli'
if = '''executable('gpt')'''
hook_add = '''
let s:model = 'gemini-2.0-flash' "'claude-3-5-haiku-20241022'
let s:code_model = 'claude-3-5-haiku-latest' " 'claude-3-5-sonnet-20241022'
let s:pro_model = 'groq/deepseek-r1-distill-qwen-32b' " 'groq/deepseek-r1-distill-llama-70b' 'claude-3-5-sonnet-20241022' gemini-2.0-flash
let s:llama = 'groq/llama-3.3-70b-versatile'
let s:url = 'http://localhost:11434'
command! -nargs=0 -range GPTGenerateCode <line1>,<line2>call gptcli#GPT('You are best of code generator. Generate a prompt to continue coding based on the given input code. Generate only code effectively, DO NOT generate descriptions nor code blocks. If you need describe code, please comment out it.', { 'max_tokens': 500, 'temperature': 0.5, 'model': s:llama})
" Keybind C-X, C-G
inoremap <C-x><C-g> <Esc>:.-5,.+5GPTGenerateCode<CR>
" Docs to code
command! -nargs=0 -range GPTGenerateDocs <line1>,<line2>call gptcli#GPT('あなたの仕事は、提供されたコード スニペットを取り出し、シンプルでわかりやすい言葉で説明することです。コードの機能、目的、主要コンポーネントを分析します。最小限のコーディング知識を持つ人でも説明が理解できるように、例え話、例、わかりやすい用語を使用します。どうしても必要な場合を除き、専門用語の使用を避け、使用される専門用語については明確な説明を提供します。目標は、コードが何をするのか、そしてそれが高レベルでどのように機能するのかを読者が理解できるようにすることです。', {"max_tokens": 2000, "model": s:model})
" Create test code
command! -nargs=0 -range GPTGenerateTest <line1>,<line2>call gptcli#GPT('You are the best code tester. Please write test code that covers all cases to try the given code.', { "temperature": 0.5, "model": s:code_model})
command! -nargs=0 -range GPTErrorBustor <line1>,<line2>call gptcli#GPT('Your task is to analyze the provided code snippet, identify any bugs or errors present, and provide a corrected version of the code that resolves these issues. Explain the problems you found in the original code and how your fixes address them. The corrected code should be functional, efficient, and adhere to best practices in programming.', {"temperature": 0.5, "model": s:code_model})
command! -nargs=0 -range GPTCodeOptimizer <line1>,<line2>call gptcli#GPT("Your task is to analyze the code snippet and suggest improvements to optimize its performance. Identify areas where the code can be made more efficient, faster, or less resource-intensive. Provide specific suggestions for optimization, along with explanations of how these changes can enhance the code’s performance. The optimized code should maintain the same functionality as the original code while demonstrating improved efficiency.", { "model": s:code_model})
command! -nargs=0 -range GPTShaper <line1>,<line2>call gptcli#GPT("Format the code without rewriting the content of the code.", { "model": "gemini-2.0-flash-lite-preview-0205", "temperature": 0})
" Any system prompt
command! -nargs=? -range GPTComplete <line1>,<line2>call gptcli#GPT(<q-args>, { 'model': s:model})
" command! -nargs=? -range GPTComplete <line1>,<line2>call gptcli#GPT(<f-args>, {'model': 'llama3.2:1b', 'url': 'http://localhost:11434' })
" Conversate with GPT
command! -nargs=? GPTChat call gptcli#GPTWindow(<q-args>, {'model': s:model})
command! -nargs=? GPTProChat call gptcli#GPTWindow(<q-args>, {'model': s:pro_model})
command! -nargs=? GPTWizard call gptcli#GPTWindow(<q-args>, 'あなたは偉大な老魔術師であり、Linuxエンジニアです。コマンドを魔術に見立てて、儀式を弟子に伝授する形式で質問に答えるのじゃ。' , {'model': s:llama, 'temperature': 1.04})
" Conversate with file content
command! -nargs=* GPTChatWithFile call gptcli#GPTWindow(<f-args>, {'model': s:model})
'''
By setting your own prompt in the GPT() function, the AI will return a one-shot document based on your own document with your own arrangements.
The GPTWindow() function allows you to open a terminal and interact with AI on Vim by putting a case-by-case system prompt in the command line.
This section compares gpt-cli with other popular LLM terminal clients to help you understand the similarities and differences between these tools.
| Client Name | Description |
|---|---|
gpt-cli |
Command-line interface for interactive chat with various LLMs including OpenAI, Anthropic, Google, Groq, and local models. |
ollama |
Tool for running large language models locally with a simple API. |
Claude Code |
Anthropic's command-line tool for delegating coding tasks to Claude directly from the terminal. |
llm |
CLI tool by Simon Willison for interacting with LLMs, with plugin support. |
shell\_gpt (sgpt) |
Command-line interface to chat with ChatGPT from the terminal. |
aichat |
Chat with AI models in your terminal with support for multiple providers. |
lm-terminal |
Minimalist terminal interface for interacting with LLMs. |
openai-cli |
Official OpenAI command-line interface for their models. |
Anthropic CLI |
Official Anthropic command-line interface for Claude models. |
Gemini CLI |
Google's command-line tool for interacting with Gemini models. |
| Feature | gpt-cli | ollama | Claude Code | llm | shell_gpt | aichat |
|---|---|---|---|---|---|---|
| Model Support | ||||||
| OpenAI Models | ✅ | ❌ | ❌ | ✅ | ✅ | ✅ |
| Anthropic Models | ✅ | ❌ | ✅ | ✅ | ❌ | ✅ |
| Google Models | ✅ | ❌ | ❌ | ✅ | ❌ | ✅ |
| Grok Models | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Groq Models | ✅ | ❌ | ❌ | ✅ | ❌ | ✅ |
| Together AI Models | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Fireworks Models | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| MistralAI Models | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ |
| Replicate Models | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ |
| Local Models | ✅ | ✅ | ❌ | ✅ | ❌ | ✅ |
| Core Features | ||||||
| Interactive Chat | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Single-prompt Mode | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Pipeline Support | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| System Prompts | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| File Attachments | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Model Switching | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ |
| Technical Aspects | ||||||
| Language | TypeScript/Deno | Go | Python | Python | Python | Go |
| Local Execution | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ |
| API Required | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ |
| Open Source | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ |
| Single binary operation | ✅ | ✅ | ❌ | ❌ | ❌ | ✅ |
| Integration | ||||||
| Vim Plugin | ✅ | ❌ | ❌ | ❌ | ✅ | ❌ |
| Shell Integration | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Context Preservation | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Unique Features | ||||||
| Model History Stack | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| In-chat Model Switching | ✅ | ❌ | ❌ | ❌ | ❌ | ✅ |
| Coding-Focused | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ |
| Local Model Serving | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
- gpt-cli focuses on providing a unified interface for multiple cloud-based LLM providers, while ollama specializes in running models locally.
- ollama includes its own model serving capability, while gpt-cli connects to existing API services (including ollama).
- gpt-cli offers more flexibility in provider selection and model switching during conversations.
- gpt-cli is a general-purpose LLM client, while Claude Code is specifically designed for coding tasks.
- Claude Code provides more coding-specific features and optimizations for developers.
- gpt-cli supports a wider range of models beyond just Claude.
- gpt-cli is built with TypeScript/Deno, while most others use Python or Go.
- gpt-cli offers unique features like model history stack and in-chat model switching.
- Each tool has its own approach to command structure, configuration, and extension mechanisms.
- When you need flexibility to switch between different LLM providers
- When you want to use both cloud-based and local models
- When you need Vim integration for code assistance
- When you prefer a TypeScript/Deno-based solution
- When you want to dynamically switch models during a conversation
- For local model usage only: ollama might be more suitable
- For dedicated coding tasks: Claude Code might be more specialized
- For integration with Python ecosystems: llm or shell_gpt might be better
- For maximum model flexibility: gpt-cli offers the widest range of options
Each tool has its strengths and ideal use cases. The best choice depends on your specific needs, workflow, and preferences.