Just as it's important to understand the kinds of problems that can be solved by data science, it's also important to have a sense of the process used to conduct data science. In this lesson, we'll outline the lifecycle of a typical data science project - from business understanding through data visualization.
You will be able to:
- Describe the full data science process
There is much more to data science than just selecting, applying and tuning Machine Learning algorithms. A data science project will often include the following stages:
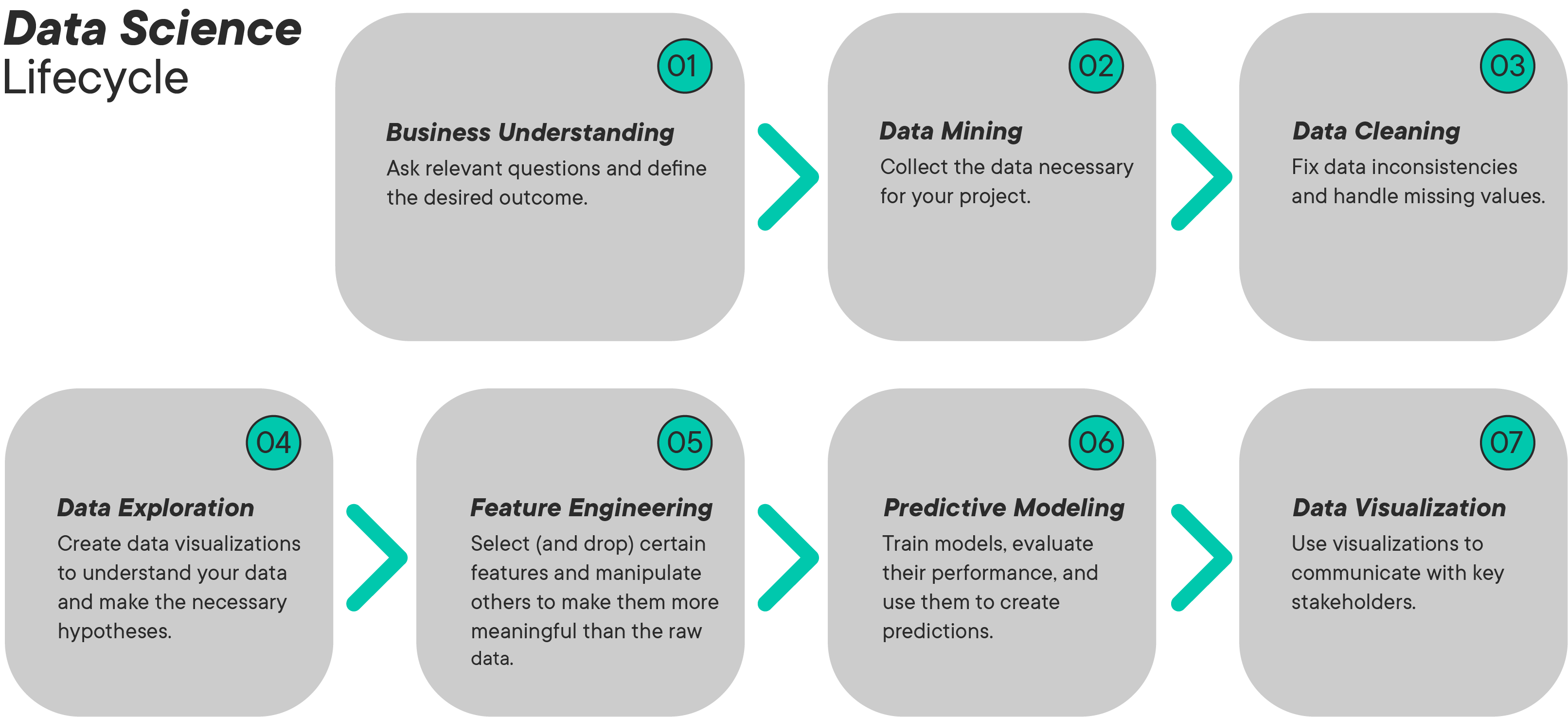
In this section, you will go through each of these stages and see what is involved.
Before trying to solve a data related problem, it is important that a Data Scientist/Analyst has a clear understanding of the problem domain and the kinds of question(s) that need to be answered by their analysis. Some of the questions that the Data Scientist might be asked include:
-
How much or how many? E.g. Identifying the number of new customers likely to join your company in the next quarter. (Regression analysis)
-
Which category? E.g. Assigning a document to a given category for a document management system. (Classification analysis)
-
Which group? E.g. Creating a number of groups (segments) of your customers based on their monetary value. (Clustering)
-
Is this weird? E.g. Detecting suspicious activities of customers by a credit card company to identify potential fraud. (Anomaly detection)
-
Which items would a user prefer? E.g. Recommending new products (such as movies, books or music) to existing customers (Recommendation systems)

After identifying the objective for your analysis and agreeing on analytical question(s) that need to be answered, the next step is to identify and gather the required data.
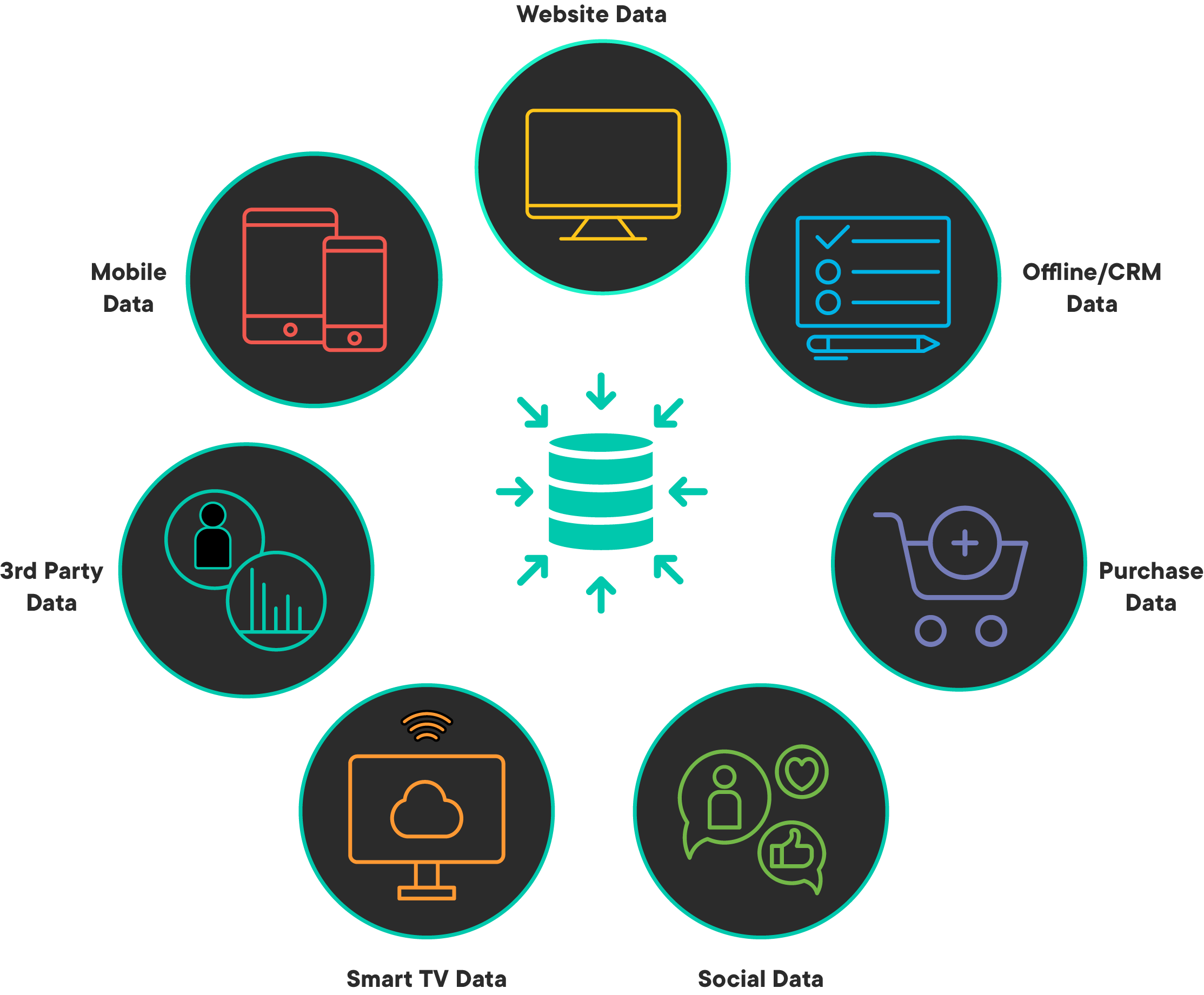
Data mining is a process of identifying and collecting data of interest from different sources - databases, text files, APIs, the Internet, and even printed documents. Some of the questions that you may ask yourself at this stage are:
- What data do I need in order to answer my analytical question?
- Where can I find this data?
- How can I obtain the data from the data source?
- How do I sample from this data?
- Are there any privacy/legal issues that I must consider prior to using this data?
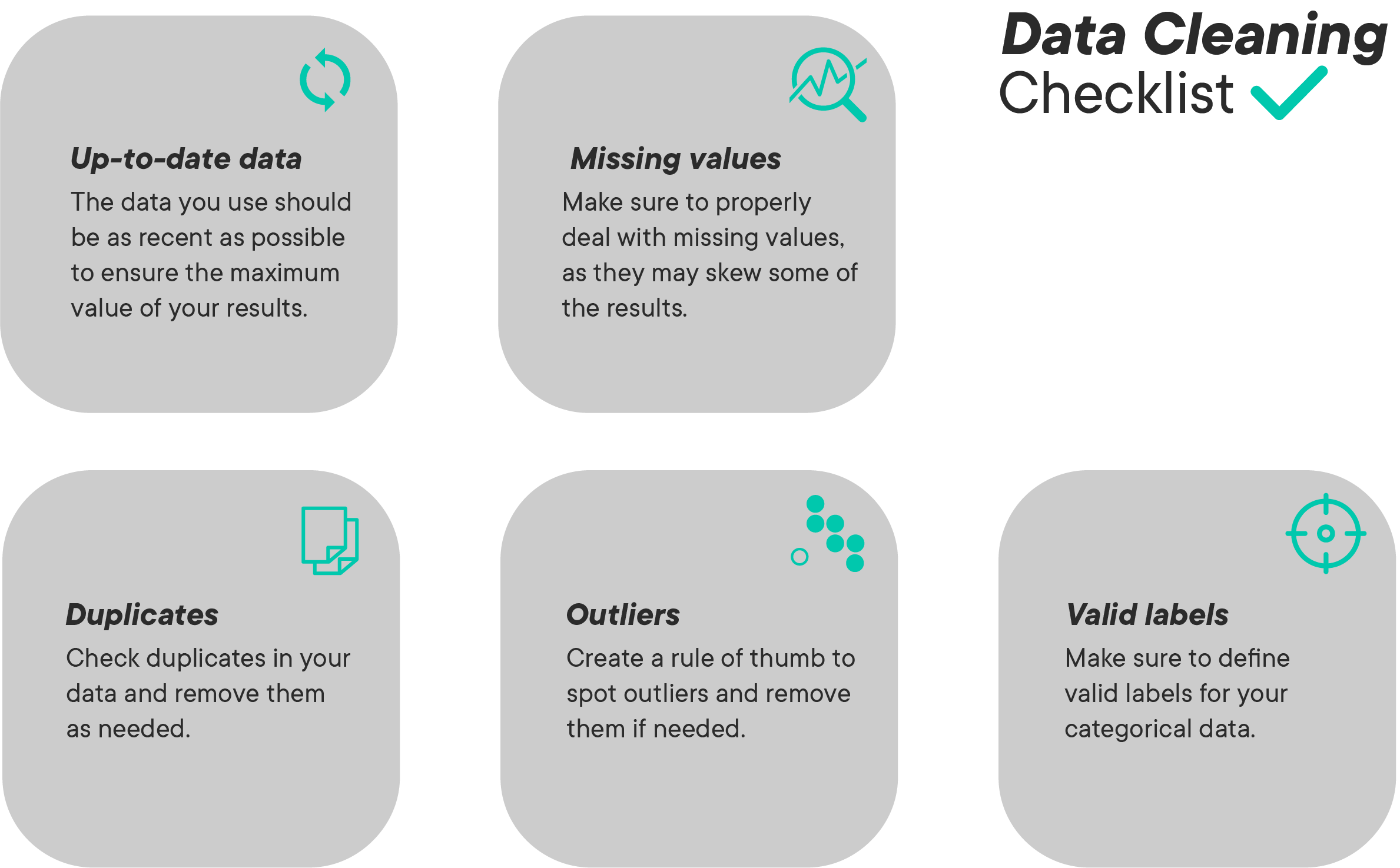
Data cleaning is usually the most time-consuming stage of the Data Science process. This stage may take up to 50-80% of a Data Scientist's time as there are a vast number of possible problems that make the data "dirty" and unsuitable for analysis. Some of the problems you may see in data are:
- Inconsistencies in data
- Misspelled text data
- Outliers
- Imbalanced data
- Invalid/outdated data
- Missing data
This stage requires the development of a careful strategy on how to deal with these issues. Such a strategy may vary substantially between different analyses depending on the nature of problems being solved.
Data exploration or Exploratory Data Analysis (EDA) helps highlight the patterns and relations in data. Exploratory analysis may involve the following activities:
- Calculating basic descriptive statistics such as the mean, the median, and the mode
- Creating a range of plots including histograms, scatter plots, and distribution curves to identify trends in the data
- Other interactive visualizations to focus on a specific segments of data

A "Feature" is a measurable attribute of the phenomenon being observed - the number of bedrooms in a house or the weight of a vehicle. Based on the nature of the analytical question asked in the first step, a Data Scientist may have to engineer additional features not found in the original dataset. Feature engineering is the process of using expert knowledge to transform raw data into meaningful features that directly address the problem you are trying to solve. For example, taking weight and height to calculate Body Mass Index for the individuals in the dataset. This stage will substantially influence the accuracy of the predictive model you construct in the next stage.

Modeling is the stage where you use mathematical and/or statistical approaches to answer your analytical question. Predictive Modeling refers to the process of using probabilistic statistical methods to try to predict the outcome of an event. For example, based on employee data, an organization can develop a predictive model to identify employee attrition rate in order to develop better retention strategies.
Choosing the "right" model is often a challenging decision as there is never a single right answer. Selecting a model involves balancing the accuracy and computational cost of the analysis process. For example, some recent approaches in predictive modeling such as deep learning have been shown to offer vastly improved accuracy of results, but with a very high computational cost.

After deriving the required results from a statistical model, visualizations are normally used to summarize and present the findings of the analysis process in a form which is easily understandable by non-technical decision makers.
Data visualization could be thought of as an evolution of visual communication techniques as it deals with the visual representation of data. There are a wide range of different data visualization techniques, from bar graphs, line graphs and scatter plots to alluvial diagrams and spatio-temporal visualizations, each of which will work better for presenting certain types of information.

In this lesson, we looked at the end-to-end Data Science process to give a sense of the activities that Data Scientists engage with.