- 직업을 검색하는 html 파일을 만듭니다.
- 직종을 검색합니다. 여기서는 python을 검색합니다.
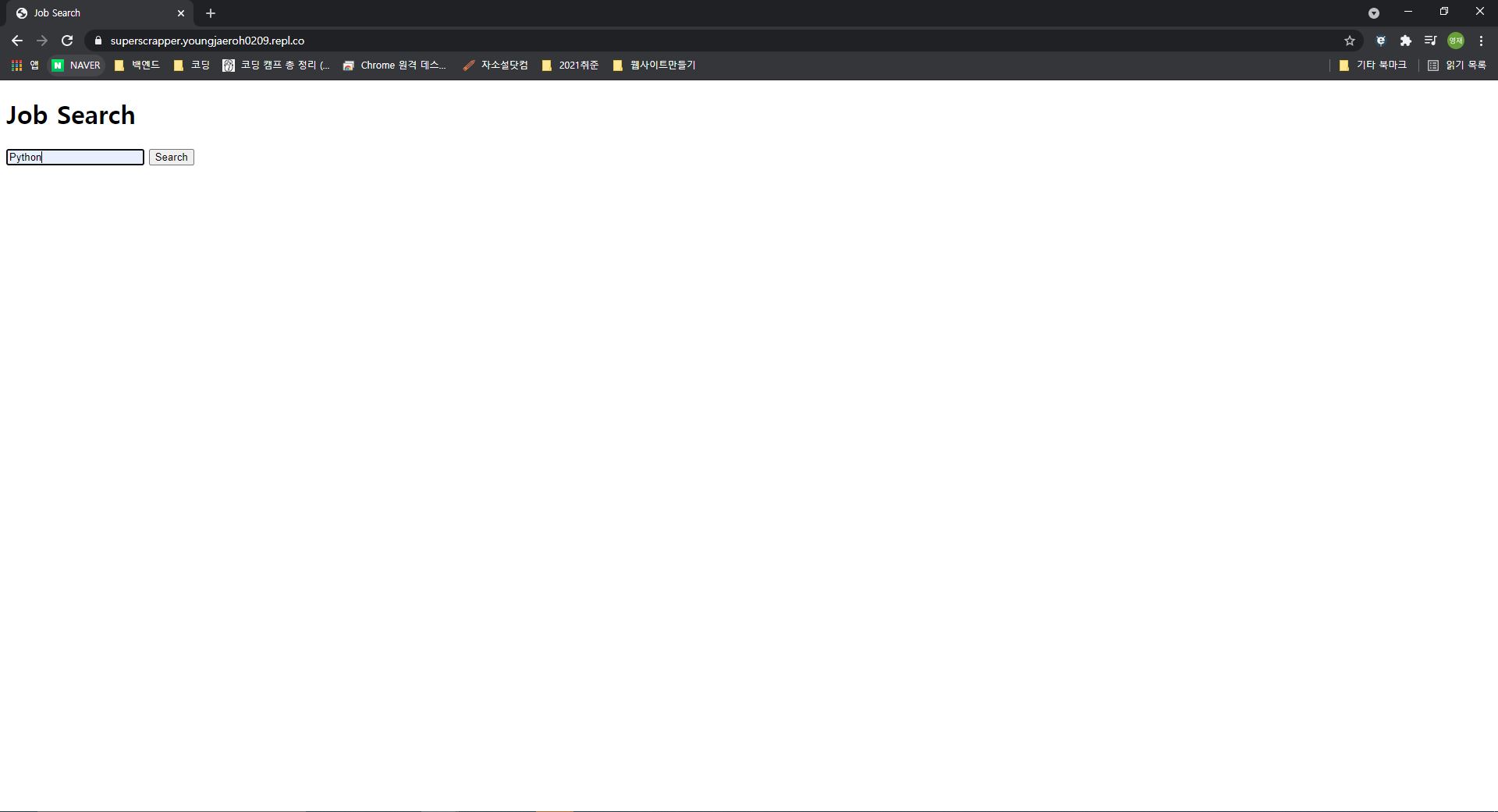
- 잠시 후 파이썬에 대한 구직글을 stackoverflow 에서 스크랩핑해서 보여줍니다.
- Export to csv를 클릭하면 csv 파일로 저장됩니다.
- csv 파일 또한 양식에 맞게 저장됩니다.
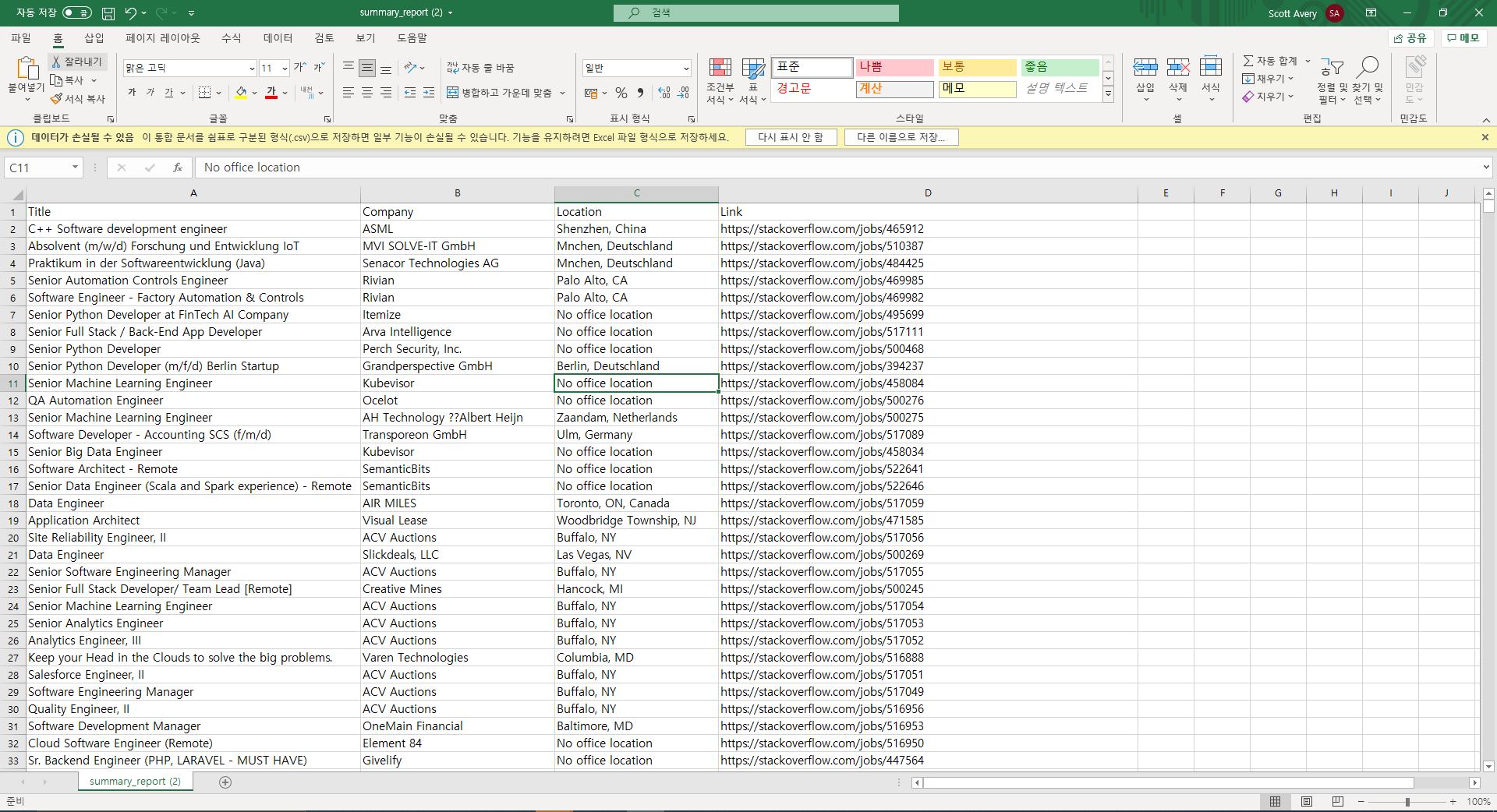
- 마지막페이지를 찾고, 마지막페이지까지 해당직종의 목록을 title,company,location,apply_link로 각각 저장
import requests
from bs4 import BeautifulSoup
def get_last_page(url):
result = requests.get(url)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class": "s-pagination"}).find_all("a")
last_page = pages[-2].get_text(strip=True)
return int(last_page)
def extract_job(html):
title = html.find("h2", {"class": "mb4"}).find("a")["title"]
company, location = html.find("h3", {
"class": "mb4"
}).find_all("span", recursive=False)
company = company.get_text(strip=True)
location = location.get_text(strip=True)
job_id = html['data-jobid']
return {
'title': title,
'company': company,
'location': location,
"apply_link": f"https://stackoverflow.com/jobs/{job_id}"
}
def extract_jobs(last_page,url):
jobs = []
for page in range(last_page):
print(f"Scrapping SO: Page: {page}")
result = requests.get(f"{url}&pg={page+1}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs(word):
url = f"https://stackoverflow.com/jobs?q={word}&sort=i"
last_page = get_last_page(url)
jobs = extract_jobs(last_page,url)
return jobs
- flask를 사용하여 웹사이트를 만들고 export하면 csv파일로 저장
from flask import Flask, render_template, request, redirect, send_file
from scrapper import get_jobs
from exporter import save_to_file
app = Flask("SuperScrapper")
db = {}
@app.route("/")
def home():
return render_template("potato.html")
@app.route("/report")
def report():
word = request.args.get("word")
if word:
word = word.lower()
existingJobs = db.get(word)
if existingJobs:
jobs = existingJobs
else:
jobs = get_jobs(word)
db[word] = jobs
else:
return redirect("/")
return render_template("report.html",searchingBy=word,resultsNumber=len(jobs),jobs=jobs)
@app.route("/export")
def export():
try:
word = request.args.get("word")
if not word:
raise Exception()
word = word.lower()
jobs = db.get(word)
if not jobs:
raise Exception()
save_to_file(jobs)
return send_file("jobs.csv", mimetype='text/csv',attachment_filename='summary_report.csv',as_attachment=True)
except:
return redirect("/")
app.run(host="0.0.0.0")
- 지역까지 검색에 추가하여 가까운 거리순으로 정렬하여 출력할 수 있습니다.