803: Data exchange with SQL databases over Apache Arrow
This note introduces the features of PG-Strom for data exchange with SQL databases (transactional systems) over Apache Arrow format files. pg2arrow and mysql2arrow are utility commands to dump/append database contents in Apache Arrow format. arrow_fdw is a foreign-data-wrapper (FDW) of PostgreSQL for direct read of Apache Arrow files on the filesystem.
Unlike traditional dump & restore process, it does not need time-consuming data importing process onto the analytic databases.
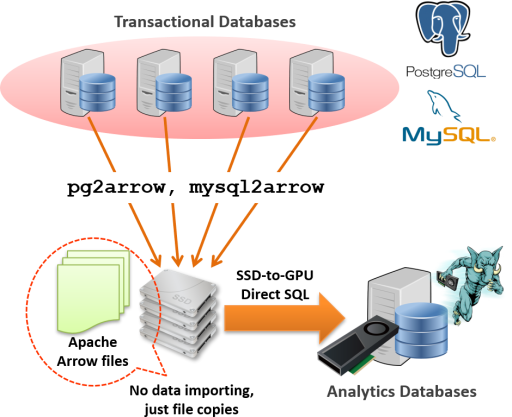
PG-Strom also distributes several utility commands. pg2arrow and mysql2arrow enables to write out query results (database contents) to files in Apache Arrow format, or append it on the existing Apache Arrow files.
As literal, pg2arrow is designed for PostgreSQL, and mysql2arrow is for MySQL.
Apache Arrow is a columnar data format designed for structured data; like tables in RDBMS. It optimizes I/O bandwidth consumption over the storage bus and pulls out maximum performance of GPU's memory access. Various kind of software already supports Apache Arrow as a portable and efficient data exchange format.
Once database contents are saved as Apache Arrow files, arrow_fdw allows to map these files as foreign tables. It supports to scan the Apache Arrow files as if it is normal PostgreSQL tables. Note that this step is much faster than traditional data importing using INSERT or COPY FROM, because arrow_fdw never makes copy of the referenced files. It just maps Apache Arrow files onto particular foreign tables, and read them directly.
pg2arrow is a utility command to dump PostgreSQL contents as Apache Arrow files.
Below is the simplest example to dump the table table0 in the database postgres to /path/to/file0.arrow.
$ pg2arrow -d postgres -c 'SELECT * FROM table0' -o /path/to/file0.arrow
You can supply more complicated query according to the -c option.
This example tries to cast id to bigint, and fetch 8 charactors from the head of x.
$ pg2arrow -d postgres -c 'SELECT id::bigint,substring(x from 1 for 8) FROM table0' -o /dev/shm/file0.arrow
Not only creation of a new file, you can expand an existing Apache Arrow file using --append instead of -o option.
In this case, the supplied query by -c option must be compatible to the schema definitions of the target file.
$ pg2arrow -d postgres -c 'SELECT * FROM table0' --append /path/to/file0.arrow
Below is the options of pg2arrow. Database connection parameters follows usual PostgreSQL commands like psql.
A debug option --dump is useful for developers to print out schema definition and data layout of the Apache Arrow file in human readable format.
$ pg2arrow --help
Usage:
pg2arrow [OPTION] [database] [username]
General options:
-d, --dbname=DBNAME Database name to connect to
-c, --command=COMMAND SQL command to run
-t, --table=TABLENAME Table name to be dumped
(-c and -t are exclusive, either of them must be given)
-o, --output=FILENAME result file in Apache Arrow format
--append=FILENAME result Apache Arrow file to be appended
(--output and --append are exclusive. If neither of them
are given, it creates a temporary file.)
Arrow format options:
-s, --segment-size=SIZE size of record batch for each
Connection options:
-h, --host=HOSTNAME database server host
-p, --port=PORT database server port
-u, --user=USERNAME database user name
-w, --no-password never prompt for password
-W, --password force password prompt
Other options:
--dump=FILENAME dump information of arrow file
--progress shows progress of the job
--set=NAME:VALUE config option to set before SQL execution
--help shows this message
Report bugs to <[email protected]>.
mysql2arrow is a utility command to dump MySQL contents as Apache Arrow files.
Most of the usages are common to pg2arrow. It runs a SQL query supplied with -c option (or SELECT * FROM table if -t option specifies a particular table), then writes out the results in Apache Arrow format.
Below is the example to dump t1 table on MySQL server, where the column 'd' (timestamp) is newer than '2020-01-01'.
$ mysql2arrow -d mysql -u root -c "SELECT * FROM t1 WHERE d >= '2020-01-01'" -o /tmp/mytest.arrow
You can see the schema definition and data layout using --dump option, as like pg2arrow supports.
$ mysql2arrow --dump /tmp/mytest.arrow
[Footer]
{Footer: version=V4, schema={Schema: endianness=little, fields=[{Field: name="id", nullable=true, type={Int32}, children=[], custom_metadata=[]}, {Field: name="a", nullable=true, type={Int32}, children=[], custom_metadata=[]}, {Field: name="b", nullable=true, type={Float64}, children=[], custom_metadata=[]}, {Field: name="c", nullable=true, type={Utf8}, children=[], custom_metadata=[]}, {Field: name="d", nullable=true, type={Timestamp: unit=sec}, children=[], custom_metadata=[]}], custom_metadata=[{KeyValue: key="sql_command" value="SELECT * FROM t1 WHERE d >= '2020-01-01'"}]}, dictionaries=[], recordBatches=[{Block: offset=496, metaDataLength=360 bodyLength=29376}]}
[Record Batch 0]
{Block: offset=496, metaDataLength=360 bodyLength=29376}
{Message: version=V4, body={RecordBatch: length=483, nodes=[{FieldNode: length=483, null_count=0}, {FieldNode: length=483, null_count=13}, {FieldNode: length=483, null_count=10}, {FieldNode: length=483, null_count=0}, {FieldNode: length=483, null_count=0}], buffers=[{Buffer: offset=0, length=0}, {Buffer: offset=0, length=1984}, {Buffer: offset=1984, length=64}, {Buffer: offset=2048, length=1984}, {Buffer: offset=4032, length=64}, {Buffer: offset=4096, length=3904}, {Buffer: offset=8000, length=0}, {Buffer: offset=8000, length=1984}, {Buffer: offset=9984, length=15488}, {Buffer: offset=25472, length=0}, {Buffer: offset=25472, length=3904}]}, bodyLength=29376}
The Apache Arrow files generated by the command are portable to other commands.
Below is an example to open the Apache Arrow file using Python(PyArrow) generated by mysql2arrow.
initial setup
$ sudo pip3 install --upgrade pyarrow
open arrow file with Python
>>> import pyarrow as pa
>>> f = pa.ipc.open_file('/tmp/mytest.arrow')
>>> f.schema
id: int32
a: int32
b: double
c: string
d: timestamp[s]
metadata
--------
OrderedDict([(b'sql_command', b"SELECT * FROM t1 WHERE d >= '2020-01-01'")])
>>> X = f.get_record_batch(0)
>>> X.to_pandas()
id a ... c d
0 1 750.0 ... c4ca4238a0b923820dcc509a6f75849b 2020-11-25 17:14:56
1 4 573.0 ... a87ff679a2f3e71d9181a67b7542122c 2023-05-14 15:24:37
2 5 948.0 ... e4da3b7fbbce2345d7772b0674a318d5 2023-01-18 16:41:12
3 8 -510.0 ... c9f0f895fb98ab9159f51fd0297e236d 2021-07-22 04:12:52
4 9 -658.0 ... 45c48cce2e2d7fbdea1afc51c7c6ad26 2021-08-13 23:38:11
.. ... ... ... ... ...
478 992 -267.0 ... 860320be12a1c050cd7731794e231bd3 2020-12-25 03:57:07
479 994 -9.0 ... 934815ad542a4a7c5e8a2dfa04fea9f5 2022-05-15 03:26:19
480 995 -262.0 ... 2bcab9d935d219641434683dd9d18a03 2021-07-27 16:14:57
481 997 -849.0 ... ec5aa0b7846082a2415f0902f0da88f2 2023-05-23 08:58:55
482 998 530.0 ... 9ab0d88431732957a618d4a469a0d4c3 2024-07-20 14:13:06
[483 rows x 5 columns]
Most of options are equivalent to pg2arrow, but only -P option (password for the database connection) followed the manner of MySQL related commands. PostgreSQL prefers password prompt by -W option.
One functional restriction at mysql2arrow, but pg2arrow already supports, is handling of Enum data type in MySQL.
mysql2arrow saves values of Enum data as non-dictionarized Utf8 data, because libmysqlclient does not allow to run another queries to obtain the list of enumulated keys before completion of the primary query.
![]()
Apache Arrow internally contains several message blocks - header, schema-definition, footer and actual data. RecordBatch contains the actual data blocks for a particular number of rows, and Apache Arrow can have multiple record-batches in a single file.
The footer has indexes to record-batches within a file, and locates just after the last record-batch.
When --append option is supplied on pg2arrow or mysql2arrow, it adds new record-batches from the SQL results, next to the last record-batch on the existing Apache Arrow file, then reconstruct the new footer.
Arrow_Fdw is a foreign-data-wrapper driver provided as a part of PG-Strom. It allows to map Apache Arrow files on filesystem, as follows.
=# CREATE FOREIGN TABLE ft1 (
id int,
a int,
b float,
c text,
d timestamp
) SERVER arrow_fdw
OPTIONS (file '/tmp/mytest.arrow');
=# SELECT * FROM ft1 LIMIT 5;
id | a | b | c | d
----+------+------------------+----------------------------------+---------------------
1 | 750 | 884.851090090746 | c4ca4238a0b923820dcc509a6f75849b | 2020-11-25 17:14:56
4 | 573 | 890.063600097812 | a87ff679a2f3e71d9181a67b7542122c | 2023-05-14 15:24:37
5 | 948 | 778.885924620035 | e4da3b7fbbce2345d7772b0674a318d5 | 2023-01-18 16:41:12
8 | -510 | 525.537846389011 | c9f0f895fb98ab9159f51fd0297e236d | 2021-07-22 04:12:52
9 | -658 | 698.654857789471 | 45c48cce2e2d7fbdea1afc51c7c6ad26 | 2021-08-13 23:38:11
(5 rows)
Foreign table definition must be identical to the schema definition of the Apache Arrow file, specified by the file option. It is a bit messy task for human's operation.
IMPORT FOREIGN SCHEMA command is another way for automatic configuration. It constructs foreign table definition according to the schema definition of the specified Apache Arrow file.
The example below defines ft2 foreign table at public schema based on the schema of /tmp/mytest.arrow.
=# IMPORT FOREIGN SCHEMA ft2
FROM SERVER arrow_fdw
INTO public
OPTIONS (file '/tmp/mytest.arrow');
=# SELECT * FROM ft2 LIMIT 5;
id | a | b | c | d
----+------+------------------+----------------------------------+---------------------
1 | 750 | 884.851090090746 | c4ca4238a0b923820dcc509a6f75849b | 2020-11-25 17:14:56
4 | 573 | 890.063600097812 | a87ff679a2f3e71d9181a67b7542122c | 2023-05-14 15:24:37
5 | 948 | 778.885924620035 | e4da3b7fbbce2345d7772b0674a318d5 | 2023-01-18 16:41:12
8 | -510 | 525.537846389011 | c9f0f895fb98ab9159f51fd0297e236d | 2021-07-22 04:12:52
9 | -658 | 698.654857789471 | 45c48cce2e2d7fbdea1afc51c7c6ad26 | 2021-08-13 23:38:11
(5 rows)
Of course arrow_fdw supports data accesses by CPU, on the other hand, the fastest way is combination of SSD-to-GPU Direct SQL and columnar data store by arrow_fdw. If and when Apache Arrow files are stored on the NVME-SSD drives with supported filesystem (Ext4) and GPU supports GPUDirect RDMA (some of Tesla models), PG-Strom can choose SSD-to-GPU Direct SQL for execution of WHERE/JOIN/GROUP BY.
Author: KaiGai Kohei [email protected] Last update: 23-Mar-2020 Software version: PG-Strom v2.3