在线开发
在线开发是一个很重要的功能,对于大部分用户来说,在线的IDE比命令vim是要方便很多。cube主要提供了vscode和jupyter两种在线ide。并没有将代码和数据进行分割存储。所以在notebok中打开的就是完全用户自己的代码和数据,可以方便的进行调试。
theia是一个在线vscode,更像本地IDE,主要服务纯代码开发(多实例,一个人可以同时开多个theia)
工作目录默认是/mnt,归档目录是/archives,可以把一些想永久保存,不易被误删的文件放在归档目录。
需要说明的是,由于theia的功能中有些进程,例如rg进程,会不停的搜索扫描目录下的所有文件。由于个人目录下包含了用户的代码和用户的数据,文件可能非常多(千万到亿级别的文件数量)。这些进程扫描会严重拖慢分布式存储的性能。所以cube做了定时检杀的功能,能够及时检杀rg和git进程,提高在线vscode的响应速度。

数据挖掘的用户使用jupyter会更多一些。在jupyter里面跟vscode里面相同,也安装了一些实用的插件,比如tensorboard,使用jupyter pro版本可以在jupyter里面打开。
比如我们在pipeline/example/tensorboard中有一个示例文件demo.py,运行这个文件,会生成一个fit_logs文件夹,这就是tf的log目录,进入这个目录,然后使用tensorboard按钮启动tensorboard,就可以查看该训练的情况。
大数据版本的Jupyter notebook,创建notebook时选择Jupyter(bigdata)镜像,集成了大数据常用的基础包,比如spark、flink等。支持爬虫、数据分析、数据挖掘和可视化等常用Python包的使用。
机器学习版本的Jupyter notebook,创建notebook时选择Jupyter(machinelearning)镜像,集成了机器学习常用的基础包,比如sklearn、scipy等。
深度学习版本的Jupyter notebook,创建notebook时选择Jupyter(DeepLearning)镜像,集成了深度学习常用的基础包,比如TensorFlow、Keras等。
R版本的notebook,创建notebook时选择rstudio(bigdata)镜像,集成了R语言的在线IDE,IDE名称为Rstudio。
MATLAB版本的notebook,创建notebook时选择matlab(DeepLearning)镜像,集成了MATLAB的在线IDE。
Pro版本的Jupyter中使用不同版本的Python内核,从python2.7到python3.9均可支持。

pro版本的Jupyter有tensorboard,创建notebook时镜像选择jupyter-conda-pro(cpu),创建一个pro版本的jupyter,运行/mnt/$username/pipeline/example/tensorboard/demo.py,运行结束会产生结果文件。进入结果文件夹,此时点击“+”符号,打开tensorboard,再选择需要进行可视化的文件,即可查看可视化结果,如下图所示。

需要注意的是,集成了tensorboard的notebook是CPU版本的,因此,如果我们需要用GPU来训练模型,并且用tensorboard做可视化,可以用GPU版本的notebook来做模型训练,把需要可视化的结果文件写到分布式存储中,再在pro版本的notebook中打开tensorboard。
需要修改config.py配置文件中ENABLE_JUPYTER_PASSWORD设置为True并更新到线上,重启后端,则会在每个jupyter后面会自动生成密码,每次进入jupyter要使用这个密码。

登录jupyter时需要密码

jupyter版本的notebook中提供了sshd,会在notebook创建时自动启动ssh-server,并且会自动生成配置文件example/ssh链接
并为每个notebook的pod配置一个单独的service,service使用ip和端口的形式对外暴漏,每个notebook使用的端口为10000+10*id+1
需要公司网络能通过ip+端口的形式访问notebook的服务
按照example/ssh链接 文件中的描述,在本地~/.ssh/config中添加链接配置文件
# 将此文件内容追加到~/.ssh/config ssh root登录密码 cube-studio
# ssh-copy-id -p PORT root@HOST 本地设置免密登录
Host cube-studio
HostName xx.xx.xx.xx
Port xx
User root
IdentityFile ~/.ssh/id_rsa
ServerAliveInterval 10
ControlMaster auto
ControlPath ~/.ssh/master-%r@%h:%p
ForwardAgent yes然后就可以ssh链接远程notebook了,并且可以在本地将文件拖拽到本地vscode,这样文件就是自动同步到在线notebook中
要实现这个目标,您可以使用SSH端口转发功能。具体来说,您可以在内网中设置一个跳板机(也称为SSH代理服务器),并通过它连接到其他内网SSH服务器。以下是如何实现这个目标的步骤:
-
首先,确保您可以从本地客户端访问内网中的跳板机。例如,假设跳板机的IP地址为192.168.1.1,端口号为22,用户为user1。
-
在本地客户端上设置SSH代理隧道。这将允许您通过跳板机访问其他内网SSH服务器。例如,假设您希望连接到内网中的SSH服务器A(IP地址:192.168.1.2,端口:10022,用户:user2)和SSH服务器B(IP地址:192.168.1.3,端口:10023,用户:user3)。在本地客户端上,运行以下命令以创建SSH隧道:
ssh -L 10022:192.168.1.2:10022 -L 10023:192.168.1.3:10023 [email protected] -p 22user1是您在跳板机上的用户名。这将在您的本地客户端上创建两个端口转发(10022和10023),分别连接到内网中的SSH服务器A和B。 -
现在,您可以通过本地客户端上的端口10022和10023来访问内网中的SSH服务器A和B。例如,要连接到SSH服务器A,您可以运行以下命令:
ssh [email protected] -p 10022要连接到SSH服务器B,您可以运行以下命令:
ssh [email protected] -p 10023在这两个命令中,
user2,user3是您在SSH服务器A和B上的用户名。
通过这种方法,您可以通过仅可以访问的内网IP和端口来访问内网中的不同SSH服务器。
对于需要连接数据中台的场景,例如连接Hive或Spark集群,我们可以在自定义Notebook中预先配置好相关的XML文件,以便用户直接使用。这样,开发者只需要配置一次,普通用户就可以直接使用,无需再次配置。
在jupyter中启动提交spark任务,作为driver端需要监听端口,每个notebook在创建的时候会预留$PORT1和$PORT2两个环境变量代表的端口来对外监听,同时在$SERVICE_EXTERNAL_IP环境变量代表的主机上进行监听,所以需要告诉spark的master,driver的服务监听地址,这样能让master返回数据到driver端
# 创建 SparkSession
spark = SparkSession.builder \
.appName("PythonPi") \
.master('spark://myspark-master-0.myspark-headless.kubeflow.svc.cluster.local:7077') \
.config("spark.executor.memory", "2g") \
.config("spark.executor.cores", "2") \
.config("spark.cores.max", "8") \
.config("spark.driver.memory", "2g") \
.config("spark.ui.enabled", False) \
.config("spark.driver.port", os.getenv('PORT1')) \
.config("spark.blockManager.port", os.getenv('PORT2')) \
.config("spark.driver.bindAddress", '0.0.0.0') \
.config("spark.driver.host", os.getenv('SERVICE_EXTERNAL_IP')) \
.getOrCreate()使用pro版本的jupyter,在左侧目录树,进入到tensorboard对应的日志目录,再打开右侧的tensorboard按钮

就可以查看日志目录中所包含的记录的训练过程中的信息和模型的信息

pro版本的notebook中,可以直接使用git。比如直接clone一个项目到notebook中,修改文件,点击git图标,就能直接看到原文件和修改后文件的对比。

图示按钮,可帮助用户在notebook中查看资源的使用情况。需要注意的是,只有GPU版本的notebook可以在notebook中查看GPU监控,其他版本的notebook即使调用了GPU,也只能在grafana中统一查看GPU资源的监控。

在使用自定义Notebook时,需要注意的是,安装包时应该先激活对应的环境,然后再进行安装。这是因为Jupyter的内核和conda环境是两个不同的概念,需要分别进行管理。
cube采用的方案是只设置notebook的pod的limit,而不设置request,这种方案就对不资源进行独占,这样也就不用清理notebook,只是允许了notebook中的资源干扰。
GPU的占用方式上,允许独占、共享、VGPU三种方式,gpu申请(单位卡),示例:填写1,2,表示训练任务每个容器独占整卡。填写-1为共享占用方式,填写小数(0.1)为vgpu方式,申请具体的卡型号,可以类似 1(V100),目前支持T4/V100/A100。

如果notebook因为oom,定时清理,机器故障,主动reset等可能原因而重启,notebook中的环境就会丢失,但分布式存储下的内容都会保留,也就是/mnt/$username文件夹下的内容都会保留。
所以我们如果需要环境保存,有两个方案:
-
cube添加了notebook启动后自动执行/mnt/$username/init.sh脚本,用户只需要在init.sh中定义notebook特定的环境,就可以在启动notebook后拥有自己独特的环境了。
-
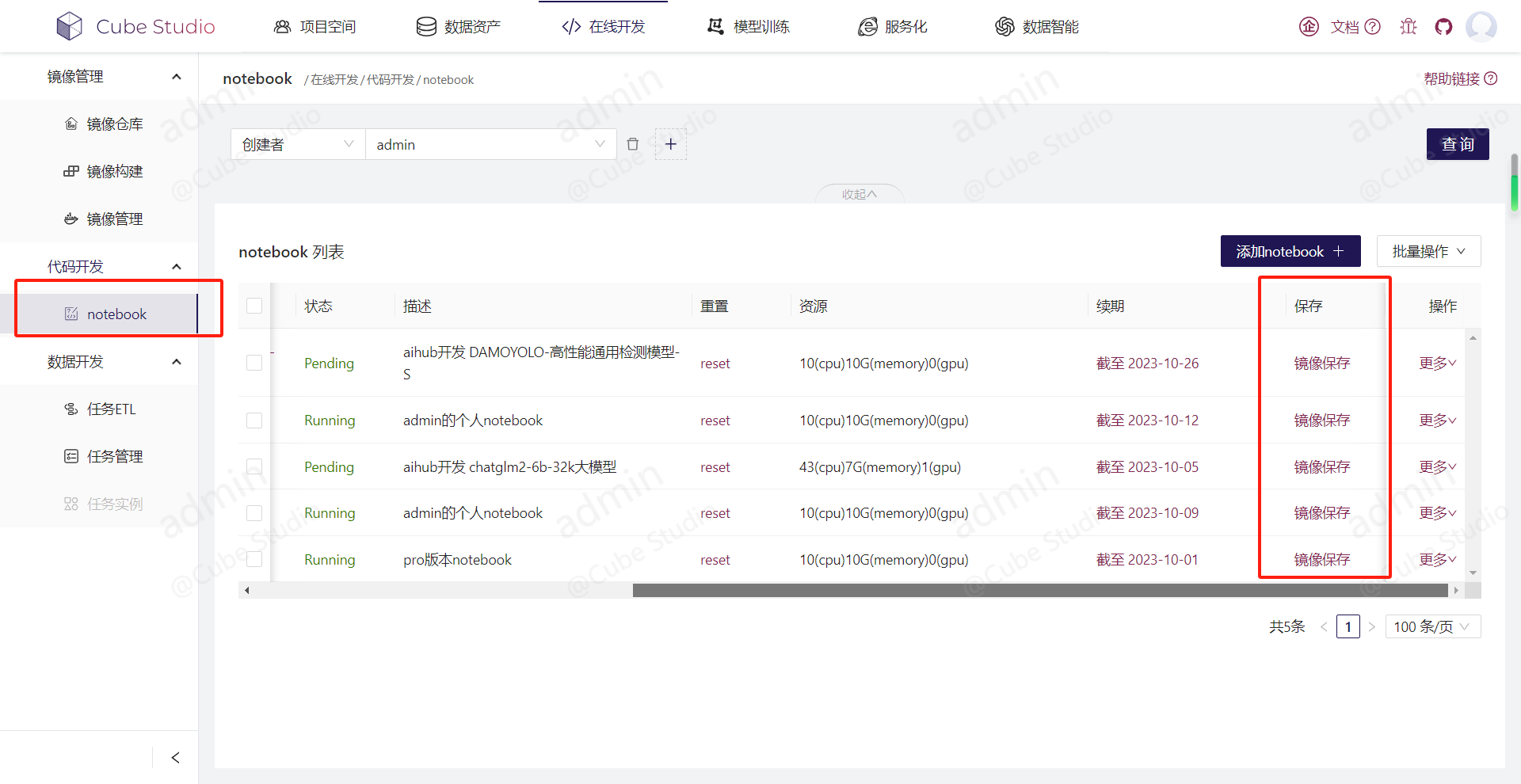
在notebook中有一个“镜像保存”按钮,每次notebook环境更改之后,都可以点击这个按钮,保存环境,下次重启就会自动用这个镜像来启动notebook,如下图所示。
多实例在线IDE图示
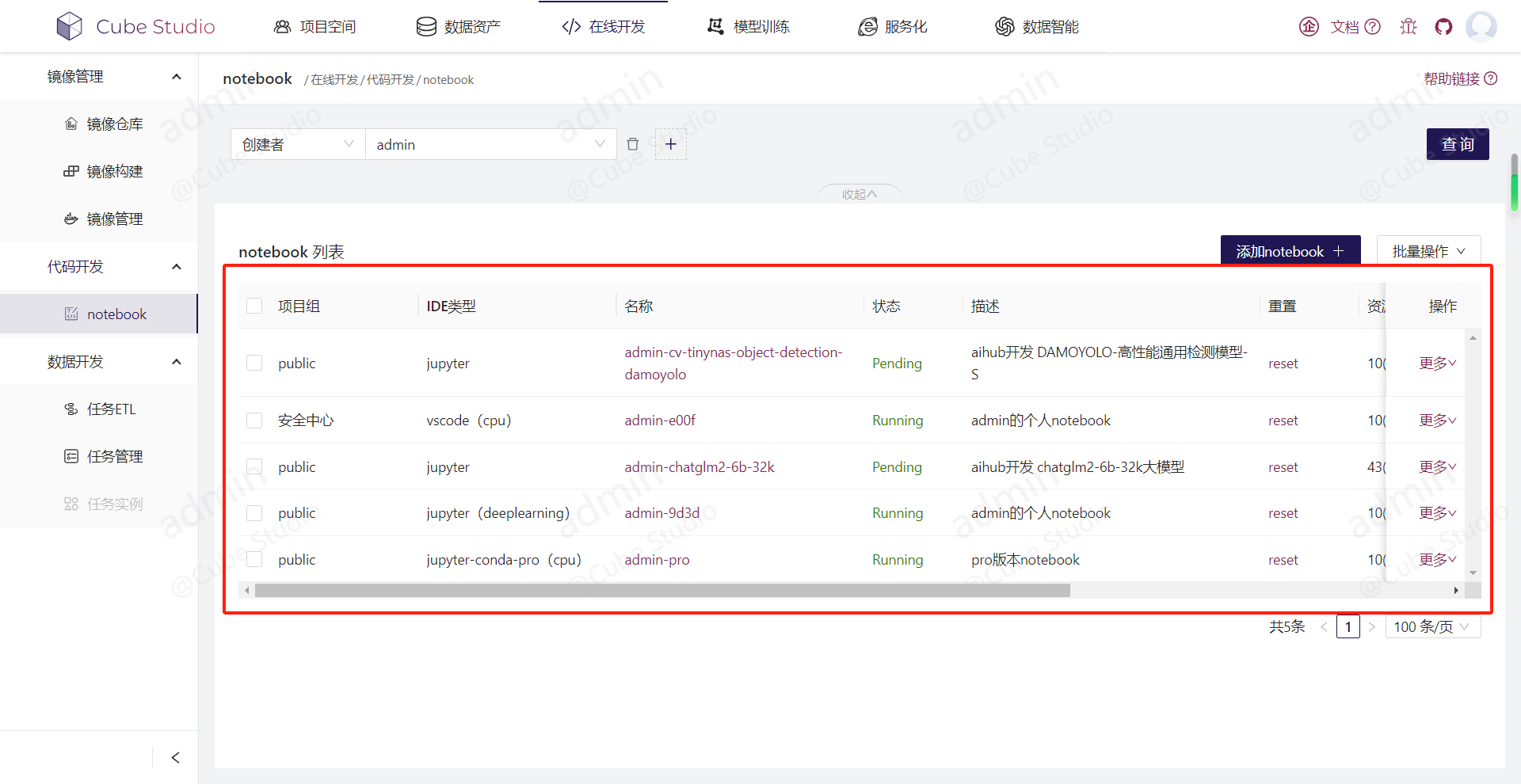
每个用户可以配置多个在线IDE,可以自己配置资源,镜像,类型。每个在线IDE都是通过istio virtualservice来代理的。所以只要在线IDE的镜像启动的web服务支持url prefix,就可以被加进来作为在线IDE,比如matlab,rstudio。每个在线IDE实例,都有独立的以名称为prefix的url地址,在virtualservice配置绑定istio ingressgateway,这样来实现多实例。
名为admin-9d3d的在线IDE的url prefix:

名为admin-e00f的在线IDE的url prefix:

如果想保存自己notebook中的环境,可以在notebook列表中点击"镜像保存"的按钮,平台将自动将该notebook的pod通过docker commit成镜像,镜像名称为jupyter-user:$notebook-name,并推送到仓库,所以还需要管理员提前配置自己内网的仓库地址和账号密码
默认情况下在线ide每天晚上会清理三天前的,清理只是关闭容器,不会清理文件,重启容器,环境会丢失。
在config.py的task_delete_notebook,注释这个任务,可以停止定时清理notebook,每次notebook有效期为3天,清理前一天会提醒用户进行续期。
点击对应notebook后的续期按钮,可以为当前notebook续期三天使用时间。

