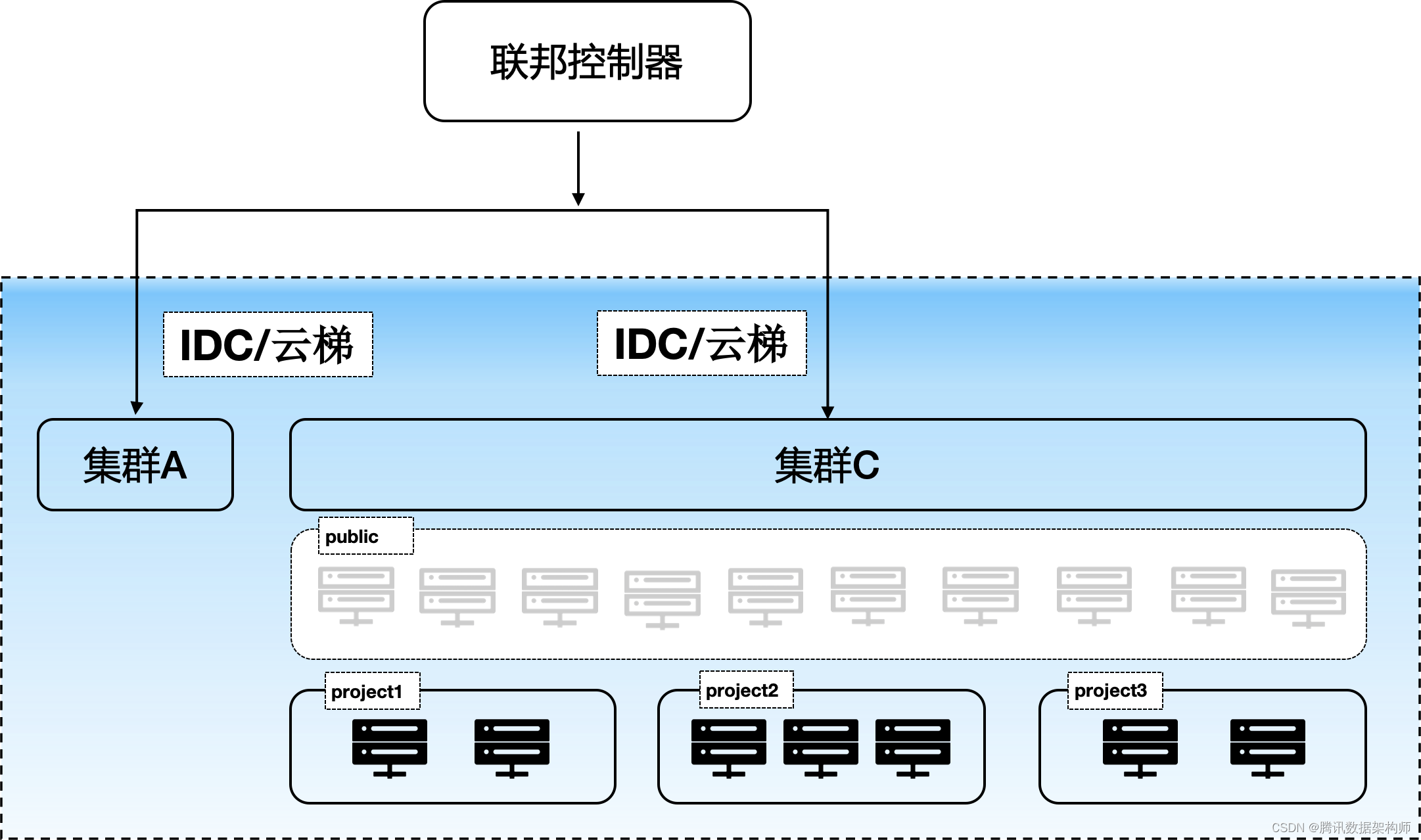
算力与分布式存储
面临的问题:
- 时间空间gpu资源利用率不足。
- 异构算力环境,任务区分cpu/gpu(T4)/gpu/(V100)/vgpu等类型。
- 超大数据量必须要跑分布式,并且资源要尽可能多。
- 个人代码和环境都依赖了固定的机器,机器的回收,损坏,裁撤,磁盘不足等事件频繁,花费很多时间工程运维。
- gpu训练中,利用率的优化,主动性不大。因为他们会优先考虑通过扩容提升效率。
解决方案:
- 统筹底层算力,最大程度上提高剩余资源的利用率,
- 项目组间算力自动均衡,基本能把保持任务挂起的等待时长不超过5分钟。
- 支持边缘集群模式,充分利用边缘网络资源,避免数据同步
- 会智能修正任务的启动资源配置,避免不合理的资源申请
面临问题:
- 为了减少数据导入导出链路,避免用户在开发/调试/训练/校验/上线时,数据文件在不同系统中间导来导去。
解决方案:
- 平台在开发notebook,数据文件处理训练pipeline,以及模型服务化中挂载相同的分布式存储,同时不同用户会挂载不同的子目录。同一个用户在平台的各个环节部分/mnt/$username下面都是个人的工作目录。

- 数据隔离:pvc挂载会自动添加用户个人子目录
- 组目录模式:支持多人共用分布式存储,满足团队工作目录的需求。
- 多存储挂载:每个项目可以添加多个pvc挂载,比如低性能cfs,高性能ssd ceph,应用不同的数据处理训练场景
- 解耦分布式存储的实现方案:只需要挂载或软链到主机(/data/k8s/),或绑定到pvc
- 磁盘爆炸:平台有存储的监控功能,会提醒用户及时删除不再使用的大文件目录;
- 磁盘不足:存储的扩缩容是弹性的,用户也就去除了存储大小的问题。
- 其他类型的挂载:比如hostpath,memory,configmap
-
pvc挂载,例如:kubeflow-user-workspace(pvc):/mnt/, 会自动将pvc下的$username子目录,挂载到容器目录的$username子目录下面
-
hostpath挂载,例如:/data/kubeflow/k8s/kubeflow/pipeline/workspace/group1(hostpath):/mnt1, 会将主机目录挂载到容器目录,一般用于多人共享编辑同一个目录使用
-
configmap挂载, 例如:kubernetes-config(configmap):/root/.kube,会将configmap挂载到容器目录,一般用于将特殊配置文件挂载到容器
-
内存挂载,例如: 4G(memory):/dev/shm,会将内存挂载到容器,一般用于处理k8s 共享内存的问题
可以使用juicefs作为分布式文件系统(不需要挂载到每台机器就可以实现多个Pod直接共享统一目录),
执行cd install/kubernetes/juicefs/ && sh start_juicefs.sh;
执行前请阅读install/kubernetes/juicefs/README.md,
并记得修改install/kubernetes/juicefs/.env的JUICEFS_HOST_IP为本节点的ip,保证/data目录有足够的空间
并注意配置好开机自动挂载避免在机器重启后挂载失效
